摘要
尽管大型语言模型近期取得了显著进展,但开源模型在复杂推理任务上往往难以持续表现优异。现有的集成方法,无论是在标记级别还是输出级别应用,都未能应对这些挑战。为此,我们提出了结合蒙特卡罗树搜索的语言模型集成(LE-MCTS),这是一种新颖的过程级语言模型集成框架。LE-MCTS将语言模型的逐步推理过程构建为一个马尔可夫决策过程。在此框架下,状态代表中间推理路径,而动作包括使用从预定义池中选择的一种语言模型生成下一个推理步骤。在基于过程的奖励模型指导下,LE-MCTS对不同语言模型生成的推理步骤进行树搜索,识别出最准确的推理链。在五个数学推理基准测试上的实验结果表明,我们的方法优于单一语言模型解码算法和语言模型集成方法。值得注意的是,LE-MCTS的性能提升了3.6%和4%。在MATH和MQA数据集上分别有3%的表现,这突显了它在解决复杂推理问题上的有效性。
1 引言
大型语言模型(LLMs)在一系列任务中展现了卓越的性能,主要归功于其大容量和高质量训练数据。然而,与像G Gemini-1.5(Gemini,2023年)和Mistral(江等人,2023a年)、LLaMA-3(LLaMA,2024年)以及Gemma-2(Gemma,2024年)这样的知名闭源LLMs不同,它们受到可用数据、架构和超参数选择等因素的限制。
问题:珍妮特的鸭子每天下16个蛋。她每天早上吃三个作为早餐,并且每天用四个为朋友烤松饼。她每天在农贸市场出售剩余的鸭蛋,每个新鲜鸭蛋卖2美元。她在农贸市场每天能赚多少钱?

LLaMA-3:我们一步步来分析:
Rho-数学:每天产16个鸡蛋。
LLaMA-3:珍妮特早餐吃3个鸡蛋,所以她还剩下16-3=13个鸡蛋。
Rho-数学:她为朋友们烤了4个鸡蛋,所以她还剩下13-4=9个鸡蛋。
LLaMA-3:她在农贸市场以每个2美元的价格出售剩下的9个鸡蛋。
Gemma-2:她的收入是9美元乘以2美元等于18美元。
Rho-数学:所以,她在农贸市场每天能赚18美元。
Gemma-2:答案:18美元
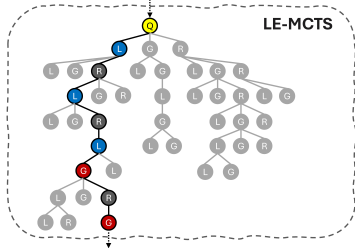
图1:LE-MCTS的示例输出。LE-MCTS输出的推理步骤可以由不同的LLM生成。我们用黄色突出显示根节点,并将相同的颜色编码应用于相应的节点和语言模型。
因此,它们表现出不同的优势和劣势(Jiang等人,2023b)。
语言模型集成是一种通过组合较弱的多个语言模型来创建多功能模型的众所周知的方法。以往关于语言模型集成的学术研究主要集中在合并标记级别和输出级别的语言模型。标记级方法合并了语言模型的输出logits或概率,使用基于困惑度的加权平均(Liu等人,2024年)以及开源模块集成方法提供了对语言模型的细粒度融合,但它们面临与分词器词汇表和模型架构相关的几个限制,需要训练额外的投影矩阵(Xu等人,2024年)来缓解这些问题。输出级方法涉及完全生成的输出的集成,要么选择最佳的一个(Farinhas等人,2023年;Jiang等人,2023年)(2023b)或通过使用额外的融合模型将它们融合起来(江等人,2023b)。尽管输出级集成可以应用于任何语言模型,但如果所有候选输出都有缺陷,它无法产生正确答案(徐等人,2024年)。
我们在表2中的实验表明,大型语言模型在不同类型的数学问题上具有不同程度的专业能力。这种差异不能简单地通过应用为单一大型语言模型设计的解码算法来缓解。此外,结果显示现有的标记级和输出级语言模型集成方法的表现都不如单一的语言模型。这些结果清楚地表明,当前的语言模型集成方法在解决复杂推理问题上特别无效,这表明需要一个专门为处理此类任务而设计的框架,并确保在不同推理问题上始终如一地保持高性能。
为了解决标记级和输出级集成的局限性,我们提出了一个针对复杂推理任务的过程级语言模型集成框架。许多复杂推理问题可以逐步解决,并且分别评估每个推理步骤允许模型尽早纠正错误,从而指导解码过程朝着更准确的解决方案前进(姚等人,2024年;贝斯塔等人,2024年;余等人,2024年;马等人,2023年)。这一方法进一步得到了基于过程的奖励模型(PRMs)的最新进展的支持(莱特曼等人,2023年;王等人,2024b年;陆等人,2024年)。我们提出了蒙特卡洛树搜索语言模型集成(LE-MCTS),这是一种用于语言模型过程级集成的开创性框架。我们将涉及多个大型语言模型(LLM)的逐步推理过程表述为一个马尔可夫决策过程(MDP)(贝尔曼,1957年)。具体来说,状态被定义为由预定义LLM池中选择的一个语言模型对多个外部推理步骤进行排名的中间推理结果。我们的MCTS算法受到AlphaZero(西尔弗等人,2017年)的启发,在由不同LLM生成的推理步骤的统一空间中进行树搜索。通过遵循PRM的指导,我们可以获得可能是由LLM生成的推理步骤组合中最准确的推理链。
我们在五个数学推理基准测试上评估了LE-MCTS:GSM8K(科贝等人,2021年)、MATH(亨德里克斯等人,2021年)、SVAMP(帕特尔等人,2021年)、ASDiv(苗等人,2020年)以及IQA(阿米尼等人,2019年)。我们的结果显示,LE-MCTS在所有任务上一致性地优于或匹敌现有的语言模型集成方法。我们还评估了过程奖励引导解码算法与语言模型集成的直接整合。尽管这些模型在小学数学习题上表现良好,但在更复杂的数据集上,如MATH和MQA,它们失败了。相比之下,LE-MCTS在MATH和MQA上的性能分别提高了3.6%和4.3%,与次优模型相比。这些实验结果突显了LE-MCTS在解决复杂推理问题上的有效性。
2 方法
首先,我们介绍问题的表述和关键符号。然后描述我们的LE-MCTS算法。
2.1 问题设置
给定一个输入问题q和L个语言模型{\pi_{1},…,\pi_{L}},一个语言模型 πl 可以生成一个完整的输出o或者一个推理步骤 pk∼πl(⋅∣q,p1:k−1),其中 p1:k−1 是直到 pk 为止之前生成的推理步骤序列。我们将以换行符结尾的每个句子定义为一步推理。这种设置允许我们比较来自不同语言模型的推理步骤,{pk1,…,pkL},它们都是基于相同的中间推理轨迹 p1:k−1 生成的。我们的目标是找到由不同语言模型生成的推理步骤的最佳组合,表示为 o∗=p1:K∗,其中 pK 是包含答案的最终推理步骤。理想情况下,我们可以通过评估集合P=∏k=1KPk中的所有元素来获得 o∗,其中Pk={pk1,…,pkL}。虽然o∗ 与单一方案相比提供了更好的解决方案

图2:LE-MCTS的单次迭代。本示例展示了三个大型语言模型(LLM)的组合。迭代重复进行,直到达到最大迭代次数niter,或者树中无法再扩展更多节点。
随着L和K的增加,评估整个P变得不可行。
为了解决这个问题,我们将逐步推理问题建模为一个马尔可夫决策过程(MDP)(Bellman,1957年),并使用蒙特卡洛树搜索(MCTS)(Coulom,2006年)来解决它。具体来说,根节点代表输入q,每个子节点s对应一个中间推理轨迹p1:k,存储其值vs和访问次数Ns。值vs代表中间推理轨迹的准确性。一个动作定义为使用πl从p1:k−1生成pkl,其中πl选自集合{π1,…,πL}。PRM计算奖励,以指导MCTS在中间推理步骤和最终输出中最大化过程奖励。在接下来的部分中,我们将介绍LE-MCTS如何有效地将来自不同LLM的推理步骤整合到树中,并在此设置中进行展望搜索。
2.2 LE-MCTS
我们的LE-MCTS算法的每次迭代包括四个阶段:选择、扩展、评估和价值回传。LE-MCTS重复迭代,直到迭代次数达到最大值niter,或者树中无法再扩展更多节点。LE-MCTS的伪代码在表1中提供。
选择LE-MCTS的每次迭代都以选择阶段开始,从根节点开始,并在层次结构中选择子节点,直到到达一个叶子节点sleaf。为了结合节点的质量值,我们使用UCT算法(Kocsis和Szepesvári,2006年)来选择一个子节点:
U(s)=vs+CNslnNparent(s)(1)
其中,Nparent(s) 是节点 s 的父节点的访问次数,C 是一个控制探索-利用权衡的常数。在每个中间节点,我们选择具有最高 U(s) 的子节点。较高的 C 值促进对欠探索节点的探索,而较低的 C 值则优先搜索高价值节点。终端状态节点被排除在选择之外,因为 LE-MCTS 选择的目的是为了识别最佳的不完整中间推理轨迹。该选择使 LE-MCTS 能够有效地探索高精度轨迹,而无需详尽检查整个集合 P。
在选择叶节点 sleaf 之后,我们为其添加一个新的子节点。为了简便起见,我们在接下来的章节中假设 sleaf 对应于中间推理轨迹 p1:k−1。
首先,我们从集合 {π1,…,πL} 中随机选择一个语言模型 πl。然后我们使用 πl 贪婪地解码下一个推理步骤 pk,直到出现换行符:
pk,t=w∈Vargmaxπl(w∣pk,<t;q,p1:k−1)(2)
其中V是词汇量。扩展阶段在过程级集成中起着关键作用,因为它将不同语言模型生成的新推理步骤引入树中。我们不扩展满足以下任一条件的完全展开的节点:
- 子节点的数量达到常数nchild
⋅vs−maxs′∈child(s)vs′<ε
第二个标准鼓励LE-MCTS通过在扩展中优先考虑深度而非广度来探索更深层次的推理路径。在复杂的推理问题中,推理链条的长度往往随着问题难度的增加而增长。因此,这个标准使LE-MCTS能够在有限的MCTS迭代次数内充分探索足够深的推理轨迹。
评估 在评估阶段,我们计算推理步骤pk的奖励。按照AlphaZero及其变体(Silver等人,2017年;Feng等人,2023年)所使用的方法,我们不进行任何展开(rollouts)。相反,我们直接采用基于过程的奖励模型(PRM)来计算奖励。具体来说,我们利用来自Math Shepherd(Wang等人,2024b年)的预训练PRM ϕ,它以推理步骤pk和问题q作为输入,预测过程奖励rk=ϕ(q,pk)。
在我们的设置中进行展开的一个优势是它使得能够使用基于结果的奖励模型(ORM)来计算奖励。然而,正如Uesato等人(2022年)所展示的,PRM和ORM都模拟基于过程的反馈,并且达到相似的性能。因此,我们决定不进行展开,因为使用ORM的性能提升微小,而执行时间增加了大约五到十倍。
价值反向传播 在扩展并评估一个叶节点后,统计数据沿着树向上传播,每个在选择阶段访问过的节点更新其价值和访问次数。标准做法(Browne等人,2014年)(2012年)关于价值反向传播的实现方法是,将访问次数Ns增加1,然后根据以下公式更新节点的值:
vs=Ns(Ns−1)vs+rk(3)
使用标准的反向传播策略,不同语言模型生成的推理步骤对vs的贡献是平等的。然而,在我们的设置中,只需识别至少一个中间推理轨迹,任何语言模型都能生成一个可行的后续推理路径即可。因此,只要一个节点至少有一个子节点的值很高,即使其他子节点的值较低,该节点也被认为是可接受的。
为解决这一问题,我们提出了一种新的反向传播策略——乐观反向传播,该策略根据其子节点中的最大值而不是奖励来更新节点的值。
vs=Ns(Ns−1)vs+maxs′∈child(s)vs′

表1:LE-MCTS的伪代码。
这种乐观的反向传播策略忽略了来自低值兄弟节点的信号,并指导LE-MCTS专注于最有希望的推理路径。
3 实验
3.1 实验设置
数据集和评估 我们使用五个广泛使用的数学推理数据集进行实验:GSM8K(Cobbe等人,2021年)、MATH(Hendrycks等人,2021年)、SVAMP(Patel等人,2021年)、ASDiv(Miao等人,2020年)以及IQA(Amini等人,2019年)。对于MATH数据集,我们使用了MATH500子集以避免数据泄露,这与Lightman等人(2023年)使用的测试集相同。对于其他数据集,我们使用了整个测试集进行评估。我们使用数学评估 harness 库(Gou和张,2024年)以确保与现有工作的一致性和可比性,遵循DeepSeek-Math(Shao等人,2024年)的评估框架。我们使用数学评估 harness 提供的上下文示例进行小样本思维链(CoT)提示,并报告准确率作为表现指标。
| Base LLM | Method | GSM8K | MATH | SVAMP | ASDiv | MQA | Average |
| LLaMA-3 | Greedy | 69.4 | 12.0 | 81.2 | 77.9 | 21.4 | 52.4 |
| LLaMA-3 | SC | 69.3 | 11.8 | 79.5 | 76.4 | 18.9 | 51.2 |
| LLaMA-3 | BS | 74.2 | 19.0 | 81.0 81.083.3 | 79.8 | 21.7 | 55.1 53.1 |
| LLaMA-3 | BoN | 74.6 | 13.4 | 77.7 | 16.6 | ||
| Gemma-2 | Greedy | 80.9 | 40.4 | 69.2 | 65.6 | 27.9 | 56.8 |
| Gemma-2 | SC | 80.6 | 39.4 | 68.1 | 66.2 | 27.0 | 56.3 |
| Gemma-2 | BS | 81.4 | 40.8 | 67.3 | 67.2 | 28.6 | 57.1 |
| Gemma-2 | BoN | 82.7 | 41.6 | 73.2 | 69.5 | 29.1 | 59.2 |
| DeepSeek-Math | Greedy | 46.6 | 28.6 | 64.0 | 70.6 | 63.8 | 54.7 |
| DeepSeek-Math | SC | 47.1 | 27.8 | 60.2 | 68.0 | 60.9 | 52.8 |
| DeepSeek-Math | BS | 52.4 | 29.0 | 60.1 | 67.5 | 66.8 | 55.2 |
| DeepSeek-Math | BoN | 65.9 | 35.0 | 73.0 | 83.5 | 66.1 | 64.7 |
| Rho-Math | Greedy | 67.6 | 29.6 | 76.6 | 77.8 | 55.8 | 61.5 |
| Rho-Math | SC | 66.9 | 28.2 | 74.2 | 77.3 | 57.5 | 60.8 |
| Rho-Math | BS | 69.9 | 28.8 | 77.7 | 81.1 | 58.2 | 63.1 |
| Rho-Math | BoN | 74.8 | 34.6 | 79.8 | 82.2 | 61.6 | 66.6 |
| Top-3 Top-3 | BoE | 80.0 | 36.0 | 84.5 | 83.8 | 65.1 | 69.9 |
| Top-3 Top-3 | EBS | 66.7 | 41.0 | 80.8 | 78.2 | 64.0 | 66.1 |
| All | Blender | 51.9 | 1.4 | 71.3 | 69.0 | 21.9 | 43.1 |
| Top-3 | MoA+ | 42.5 | 22.2 | 44.3 | 47.4 | 60.4 | 43.4 |
| All | EVA | 66.3 | 26.0 | 73.8 | 81.4 | 54.6 | 60.4 |
| Top-3 | Ours | 84.1(+1.4) | 45.2(+3.6) | 84.0(-0.5) | 84.4(+0.6) | 71.1(+4.3) | 73.8(+3.9) |
表2:主要结果摘要。我们在五个数学推理基准测试集上衡量准确性。我们还报告了最右侧一列中五个数据集性能的平均值。我们将最佳模型以粗体突出显示,次优模型以下划线标出。我们复用官方代码进行实验。
评估指标。
基线 我们将我们的方法与单语言模型解码算法和语言模型集成方法进行了对比。我们评估了两种无奖励算法,贪婪解码和自一致性(SC)(Wang等人,2023年),以及两种过程奖励引导算法,N个最佳(BoN)(Lightman等人,2023年)和束搜索(BS)(Yu等人,2024年),作为单语言模型的基线。我们还将我们的方法与令牌级集成方法EVA(Xu等人,2024年)以及输出级集成方法LLM-Blender(Jiang等人,2023b年)和MOA(Wang等人,2024a年)进行了比较。
此外,我们通过利用多个大型语言模型提出了两种新颖的过程奖励引导解码算法变体。具体来说,集成最佳(BoE)在各种大型语言模型生成的完整解决方案中选择得分最高的一个作为最终输出。集成束搜索(EBS)使用多个大型语言模型而不是单一的大型语言模型生成候选推理步骤,并进行束搜索。基线的更多细节在附录D中提供。
实施细节 我们考虑了两个通用领域大型语言模型,LLaMA-38B(LLaMA,2024年)和Gemma-2 9B(Gemma,2024年),以及两个数学大型语言模型,DeepSeek-Math 7B(Shao等人,2024年)和Rho-Math 7B(Lin等人,2024年),作为基础模型。
用于模型集成。我们设置niter=200,并在所有实验中执行无放回的LM随机选择,除非提及特定的超参数设置。在每个示例上运行LE-MCTS后,我们提取了达到终端节点的MCTS树中的所有轨迹。然后我们使用PRM对这些轨迹进行排名,并选择排名最高的轨迹作为最终输出。我们对两组基础模型进行了集成方法测试,Top-3和All,并报告平均性能更好的作为主要结果。具体来说,对于Top-3,每个数据集使用一组不同的LLM,而对于All,我们集成了所有四个基础LLM。完整的实验结果以及Top-3的基础模型选择的进一步细节在附录A中提供。
3.2 主要结果
我们在表2中报告了数学基准测试的主要结果。
LE-MCTS的表现优于或等同于现有方法。结果显示,LE-MCTS在SVAMP上的表现与最佳模型相匹配,并在其余数据集中优于所有其他模型。具体来说,五个任务的平均表现比第二好的模型BoE高出3.9%。这表明LE-MCTS是一个多功能的语言模型集成。

图3:关于价值反向传播策略的消融研究。
特别是在数学问题解决中的复杂推理框架。
LE-MCTS特别擅长复杂推理。在数学(MATH)和数学问答(MQA)问题上,LE-MCTS显著优于次优模型。数学问题包括竞赛级别的数学题目,而数学问答则包括GRE和GMAT考试题,这两类题目都比其他中学数学数据集需要更多样化和复杂的推理技能。这些具有挑战性的问题通常因为需要深入推理而涉及更长的推理步骤。
LE-MCTS与其他方法的区别在于其优先考虑深入推理的能力。例如,完全扩展标准指导LE-MCTS探索更深入的推理步骤,而不是扩展早期阶段推理的广度。此外,较小的UCT常数C鼓励选择高价值节点而非探索不足的节点。当与乐观反向传播结合使用时,这一设置也使LE-MCTS倾向于更深入的探索。相比之下,BoE和EBS依赖于核采样来生成推理步骤,这并不保证更深入或更彻底的推理。
在数学推理方面,过程级集成方法优于标记级和输出级方法。
标记级和输出级集成方法的性能显著低于过程级集成方法。在某些情况下,它们的性能甚至比最弱的单一大型语言模型基线还要差。例如,LLM-Blender在数学问题上的表现不佳,准确率仅为1.4%。我们相信,GenFuser(它聚合多个大型语言模型(LLM)的输出以生成最终结果)在理解复杂推理方面的能力有限。相比之下,MOA使用一个更大的语言模型进行操作。
| C | GSM8K | MATH | SVAMP | ASDiv | MQA |
| 0.5 | 81.7 | 45.2 | 82.7 | 84.2 | 71.1 |
| 1.0 | 83.7 | 43.6 | 84.0 | 84.4 | 69.0 |
| 1.414 | 84.1 | 44.4 | 83.8 | 84.2 | 68.6 |
表3:UCT常数C的影响。
输出融合并利用提示工程来增强聚合效果。因此,其在数学题上的准确率超过了LLM-Blender,尽管仍不及过程级集成方法。
EVA的平均表现优于输出级集成基线。然而,其词汇对齐需要在基础模型之间匹配嵌入维度,这限制了它的适用性。因此,我们无法使用Gemma-2作为EVA的基础模型,尽管它在GSM8K和数学题上取得了基础大型语言模型中的最高性能。相比之下,基于过程的算法(包括我们的算法)不受架构或词汇的限制,确保在各种大型语言模型中有广泛的适用性。
3.3 分析
反向传播策略 作为一项消融研究,我们比较了LE-MCTS与标准值反向传播的LE-MCTS以及乐观值反向传播的LE-MCTS。图3的结果显示,乐观反向传播在所有数据集上一致提高了性能,提升幅度从0.1%到1.6%不等。此外,如附录B所示,在使用乐观反向传播时,我们观察到叶节点的平均奖励更高。这是因为乐观反向传播仅通过树更新最高价值节点的值,从而在搜索过程中忽略了低价值节点。由于PRM更准确地估计过程奖励,预计乐观策略和标准策略之间的性能差距将会扩大。
UCT常数C,控制着LE-MCTS中探索与利用之间的平衡。在我们的框架中,节点的深度对应于推理步骤的数量。附录C中的实验结果显示,随着C值的减小,叶节点的平均深度趋于增加。我们假设,简单的数学问题,如小学水平的数学文字题(例如,SVAMP和ASDiv),不需要长的推理链,并且会从较高的C值中受益,因为它促进了早期步骤中更有效的推理,比如识别数学变量。
| niter | GSM8K | MATH | SVAMP | ASDiv | MQA |
| 10 | 79.8 | 43.8 | 82.9 9 | 82.4 | 65.7 |
| 25 | 81.0 | 43.4 | 82.9 | 83.5 | 65.5 |
| 50 | 81.5 | 44.4 | 82.7 | 83.2 | 68.9 |
| 100 | 82.9 | 45.2 | 83.1 | 83.5 | 68.2 |
| 200 | 184.1 | 45.2 | 84.0 | 84.4 | 71.1 |
表4:最大MCTS迭代次数niter的影响。
相反,更具挑战性的数学问题,如数学(MATH)和数学问答(MQA)中的问题,需要竞赛级别的推理技能。在这些情况下,较低的C值是有利的,因为它鼓励更深入地探索推理路径,而不是专注于早期步骤。
为了验证我们的假设,我们评估了C∈{0.5,1.0,1.414}1的LE-MCTS,结果在表3中报告。结果表明,C=0.5在数学(MATH)和数学问答(MQA)上表现最佳,而C=1.0和C=1.414在GSM8K、SVAMP和AS-Div上优于C=0.5。我们的实验为选择适当C值以应对之前未见过的难题提供了指导。对于复杂程度类似于简单的小学数学文字题的问题,推荐使用大于1的C值,以促进对早期阶段推理步骤的有效探索。相比之下,对于更复杂的问题,小于1的C值更为可取,因为它鼓励对深入推理路径进行更彻底的调查。
最大MCTS迭代次数,niter 超参数niter在确定性能与计算成本之间的平衡中起着至关重要的作用。较大的niter会增加算法的执行时间,而太小的niter可能不足以找到一个最优的推理路径。为了研究niter对性能的影响,我们在集合{10,25,50,100,200}中改变niter,并在表4中报告结果。结果显示,随着迭代次数niter从10增加到200,性能得到提升,这表明我们在进行更多MCTS迭代时可以找到更好的推理路径。然而,这种提升在不同数据集之间是有变化的,并且性能通常在200次迭代后趋于饱和。这些结果强调了选择合适的迭代次数以平衡性能与计算的重要性。
| Method | ASDiv | ASDiv | MATH | MATH |
| Method | VRAM(↓) | min/ex(↓) | VRAM(↓) | min/ex(↓) |
| BoE | 76.7 | 17.6 | 64.8 | 71.1 |
| EBS | 79.2 | 12.3 | 71.8 | 47.2 |
| Blender | 70.4 | 22.2 | 66.5 | 59.1 |
| MoA | 67.4 | 84.4 | 79.8 | 93.7 |
| EVA | 69.9 | 92.2 | 70.3 | 480.2 |
| Oursniter=25 | 76.7 | 34.6 | 64.6 | 129.1 |
| Oursniter=200=200 | 77.4 | 112.2 | 71.0 | 342.2 |
表5:效率分析。我们比较了我们的方法与基于峰值显存使用量和吞吐量的现有集成方法的效率。吞吐量以每个样本的平均时间计算,以每个样本分钟(min/ex)报告。显存使用量量化为推理过程中观察到的最大值,以千兆字节(GB)表示。对于这两个指标,较低的值表示更高的效率。
成本。
效率分析 我们遵循Dehghani等人(2022年)的方法,比较所提出的方法与现有的集成方法的效率。具体来说,我们沿着两个轴线分析效率:GPU内存消耗和吞吐量。吞吐量定义为处理每个样本所需的平均时间。我们使用推理期间的峰值显存使用量作为内存消耗指标。我们选择显存使用量作为效率指标,因为浮点运算次数(FLOPs)虽然常用,但难以在不同解码算法之间公平比较。相比之下,显存使用量作为编码过程中涉及的参数数量和输入序列长度的间接指标,这些是衡量Transformer架构中计算成本的最重要因素。
为了公平比较,我们在单个NVIDIA H100 80GB GPU上测量了显存使用和吞吐量,使用了相同的CUDA和PyTorch版本。我们在最复杂的数据集MATH和最简单的数据集ASDiv上评估了这些效率指标。表5中的结果显示EBS在吞吐量方面是最有效的算法。在峰值VRAM使用情况下,MOA和LE-MCTS(迭代次数niter=25)分别在ASDiv和MATH上是最有效的算法。输出级和标记级集成方法在MATH上表现出高吞吐量,而LLM-Blender和MOA由于聚合器的长输入序列长度而受影响,EVA在实现中缺乏生成长序列的优化。
我们的LE-MCTS(迭代次数niter=200)比大多数现有算法更资源密集,但实现了更好的性能。虽然LE-MCTS在复杂问题上提供了显著的性能提升,但在较简单任务上的优势则微不足道。在ASDiv中,即使我们运行少量MCTS迭代(n=25),LE-MCTS在吞吐量上也不如BoE和EBS高效。这一结果强调,尽管LE-MCTS的深入搜索对于解决复杂推理问题是有益的,但对于直接的任务可能引入不必要的计算开销,在这些任务中,EBS和BoE可以以较低的成本实现可比的性能。因此,LE-MCTS特别适合于需要深入分析的具有挑战性的推理任务,在这种情况下,性能和计算成本之间的权衡是可以接受的。
4 相关工作
4.1 语言模型集成
集成学习是一种通过整合多个较弱模型来提高模型性能的广泛应用方法(Lu等人,2024b)。在大型语言模型(LLMs)中,集成方法通常应用于标记级或输出级。标记级集成(Liu等人,2021, 2024a; Li等人,2024; Mavromatis等人)(2024年)涉及合并来自多个大型语言模型(LLM)的标记对数似然或概率,这通常要求模型共享相同的标记词汇和模型架构。为了克服这一限制,EVA(徐等人,2024年)通过预训练的映射将不同LLM的输出分布映射到一个统一的空间。相比之下,输出级集成方法(江等人,2023b;王等人,2024a;伊扎卡德和格拉夫,2021年;拉沃特等人,2022年)使用额外的融合模型组合整个模型的输出。例如,LLM-Blender(江等人,2023b)引入了一个通用框架,该框架采用一对排名器筛选出前K个最优输出,然后通过融合模型合并它们以生成最终结果。
我们的工作介绍了一种新颖的过程级集成方法,它比标记级方法提供了更大的灵活性,因为LE-MCTS不需要匹配词汇或架构。此外,在输出级集成方法中,聚合器接收多个LLM的输出作为输入,这可能导致输入序列长度超出其处理能力的限制。相比之下,LE-MCTS的最大输入序列长度与使用贪婪解码解决单个LLM的数学推理问题时相同。因此,输出级集成方法不适用于需要深入、冗长推理的复杂推理任务。
4.2 奖励引导解码
数学推理问题的两种主要验证器类型是结果奖励模型(ORM)和过程奖励模型(PRM)。ORM评估整个解决方案,而PRM评估单个步骤,提供更细粒度的反馈。与自洽性相比,这两种方法在数学推理方面都显示出改进(Wang等人,2023年),然而有证据表明PRM优于ORM(Lightman等人,2023年;Wang等人,2024b年)。先前的研究已经使用奖励来指导句子层面的解码过程(Uesato等人,2022年;Welleck等人,2022年;Yao等人,2024年)以及标记层面(Dathathri等人,2020年;Yang和Klein,2021年;Chaffin等人,2022年;Li等人,2023年)。ARGS(Khanov等人,2024年)已经将语言模型对齐作为奖励引导的搜索纳入其中。Yu等人(2024年)和Ma等人(2023年)已经应用过程奖励来增强启发式搜索算法。最近,ReST-MCTS*(Zhang等人,2024年)也采用了类似我们方法的过程奖励引导的MCTS,以生成高质量数据进行自训练。然而,我们使用MCTS的重点在于集成大型语言模型。据我们所知,这是首次尝试将过程奖励引导应用于大型语言模型集成。
5 结论
在本文中,我们介绍了一种新颖的框架,用于对语言模型进行过程级集成,解决了传统语言模型集成方法的关键局限性。我们将语言模型集成的逐步推理构建为一个马尔可夫决策过程。通过利用现有的基于过程的奖励模型和蒙特卡洛树搜索,我们的方法有效地进行了导航不同语言模型生成的推理步骤的统一空间,以发现更准确的解决方案。在数学推理基准测试上的广泛实验证明了所提出方法的有效性,特别是在解决复杂推理问题方面。我们相信这种方法为更广泛的过程级语言模型集成铺平了道路,因为它可以应用于任何存在适当过程奖励模型的逐步推理问题。
限制
我们提出的LE-MCTS框架依赖于来自基于过程的奖励模型的信号,以有效导航推理步骤的空间。当过程奖励模型(PRM)无法准确计算奖励时,LE-MCTS也会失败。虽然Math-Shepherd的PRM通常在已建立的数学数据集上表现良好,但不能保证其适用于新的数学问题。此外,其他复杂、逐步推理任务的过程奖励模型(PRMs)相对尚未被探索。因此,开发健壮且具有泛化能力的PRMs对于增强LE-MCTS至关重要,我们认为这是一个有价值的未来方向。
我们工作的另一个限制是需要选择基础模型。附录A中的实验结果表明,使用弱基础模型会损害LE-MCTS的性能。尽管我们展示了即使是少量合成数据也能有效识别弱基础模型,但这种方法可能不适用于其他任务和数据集。尽管如此,选择基础模型在效率方面提供了明显的优势。通过仅结合少量大型语言模型(LLM),LE-MCTS 在显存使用和 MCTS 迭代次数上实现了更高的效率。我们认为,开发一种健壮的选择算法以识别有效的基础模型是另一个重要的未来方向。

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-360x180.png)
![Claude客户支持聊天web app开发[可建私域知识库]](https://assh83.com/wp-content/uploads/2024/10/preview-360x180.png)

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)