检索增强生成(RAG)在整合外部知识以解决大型语言模型(LLMs)的局限性方面是有效的,但可能因不完美的检索而受到损害,这可能会引入无关紧要、误导甚至恶意的信息。尽管其重要性,但以往的研究很少通过联合分析不完美检索的错误属性和传播方式,以及LLMs内部知识与外部来源之间潜在的冲突来探索RAG的行为。我们发现,在现实条件下通过受控分析,不完美检索增强可能是不可避免且相当有害的。我们确定了在RAG的后检索阶段克服LLM内部和外部知识之间的知识冲突是一个瓶颈。为了使LLMs对不完美检索具有弹性,我们提出了ASTUTE RAG,这是一种新颖的RAG方法,它自适应地从LLMs的内部知识中提取关键信息,迭代地巩固内部和外部知识,并根据信息的可靠性最终确定答案。我们的使用Gemini和Claude的实验表明,ASTUTE RAG显著优于之前的增强鲁棒性RAG方法。值得注意的是,AsTUTE RAG是唯一一种在最坏情况下不依赖RAG就能匹配或超越LLMs性能的方法。进一步分析揭示了Astitute RAG有效地解决了知识冲突,提高了RAG系统的可靠性和可信度。
1. 引言
检索增强生成(RAG)已成为大型语言模型(LLMs)解决知识密集型任务的标准方法(顾等,2020;刘易斯等,2020)。以往的工作主要利用RAG来解决LLMs固有的知识限制,有效地整合缺失信息和归因到可靠的来源。然而,最近的研究突显了一个重大缺点,即RAG可能依赖于不完美的检索结果,包括无关紧要的、误导性的甚至恶意的信息,这最终导致LLMs的响应不准确(陈等,2024a;向等,2024;邹等,2024)。例如,当被问及吃石头的行为时,LLMs可能会引用误导性的信息,比如一个讽刺的新闻来源声称人们每天至少应该吃一块石头。不完美的检索增强是不可避免的,受到语料库质量限制(邵等,2024)、检索器的可靠性(戴等,2024)以及查询复杂性(苏等,2024)等因素的驱动。这对RAG的可信度提出了重大挑战。
虽然已经对LLMs的信息检索和RAG进行了独立的分析(马伦等,2023;苏等),但仍有许多工作尚未进行。在之前的研究中,检索和后续生成的行为很少被联系起来,特别是关于信息检索错误的传播,这可能导致知识冲突(Longpre等人,2021年;Wang等人,2023a年;Xu等人,2024b年)。为此,我们对检索发生的情况进行了全面分析。
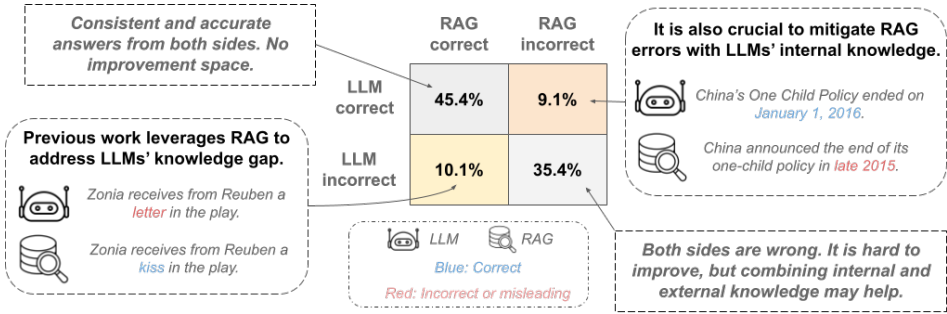
图1|大型语言模型(LLMs)内部知识与外部来源检索知识之间的知识冲突。我们在第4.1节中报告了Claude在设置下的总体结果。
不完美的检索增强及其对LLM行为的影响(第2节)。我们在NQ(Kwiatkowski等人,2019年)、TriviaQA(Joshi等人,2017年)、BioASQ(Tsatsaronis等人,2015年)和PopQA(Mallen等人,2023年)的广泛一般性、领域特定性和长尾问题上进行了对照实验。我们观察到,即使有像谷歌搜索这样的熟练的现实世界搜索引擎——大约70%的检索段落并不直接包含真实答案,这导致了带有RAG增强的LLM性能受阻。
这些发现强调了现实世界RAG中不完美检索问题的潜在严重性,并突出了知识冲突作为克服这一瓶颈的普遍存在(图1)。最近的研究表明,LLM内部和外部知识提供了不同的优势,但LLMs往往难以可靠地整合冲突信息,未能基于集体知识做出响应(Jin等人,2024年;Mallen等人,2023年;Tan等人,2024年;Xie等人,2024年)。这就提出了以下研究问题:有没有一种有效的方法来结合内部(来自LLMs预训练权重)和外部(来自特定语料库或知识库)的知识,以获得更可靠的RAG?
以往的工作已经广泛探讨了使用外部知识来增强大型语言模型(LLMs)通过强化学习(RAG)。我们寻求进一步利用LLMs的内部知识来从RAG失败中恢复。
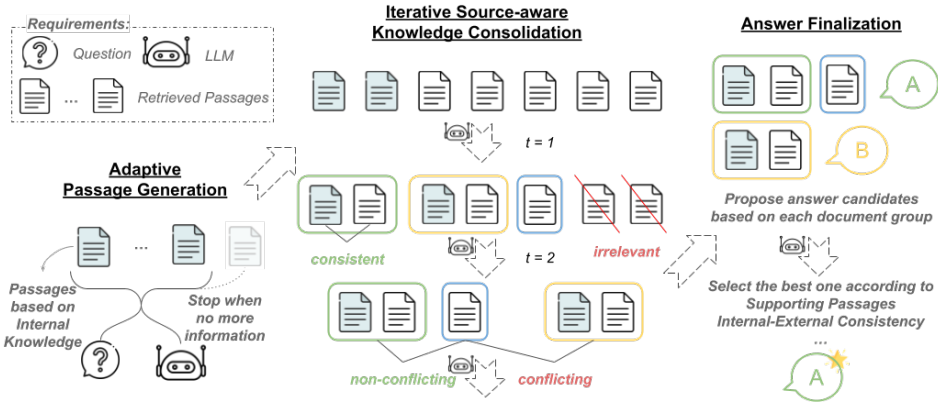
受到这些重要的现实世界挑战的激励,我们提出了ASTUTE RAG(第3节),这是一种新颖的RAG方法,旨在对不完美的检索增强具有弹性,同时当RAG可靠时保持RAG的基础效果。为此,ASTUTE RAG需要有效地区分LLM的内在知识和在RAG中检索的外部信息的可靠性,仅在可信时使用每个,并确保适当的整合。具体来说,AsTUTE RAG最初从LLMs的内部知识中提取信息,以明确补充从外部来源检索到的段落。然后,ASTUTE RAG进行源感知的知识巩固,来自各种内部和外部来源的信息。目标是结合一致的信息,识别冲突的信息,并过滤掉不相关的信息。最后,ASTUTE RAG基于每组一致段落提出答案,并比较不同段落组的答案来确定最终答案。我们在各种数据集上涉及Gemini和Claude3的实验(第4节)证明了与之前旨在对抗检索损坏而设计的RAG方法相比,ASTUTE RAG具有更优越的性能。此外,ASTUTE RAG在不同检索质量水平上始终优于基线。值得注意的是,
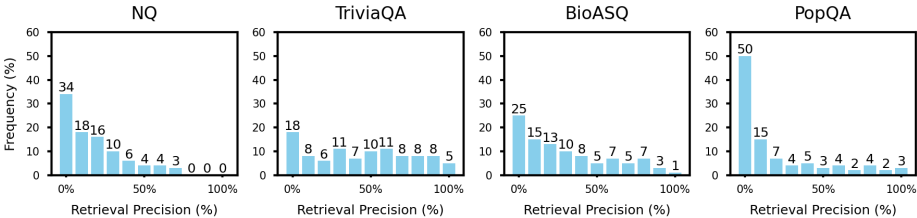
图2| 实际世界RAG中存在检索不完美(检索精度低)的情况。
智能RAG是唯一在所有检索到的段落都无用的最坏情况下,其性能可与传统LLMs使用相当甚至超越的传统LLMs的方法。进一步分析揭示了智能RAG在解决内部和外部知识之间的知识冲突方面的有效性。
总之,我们的核心贡献有三个方面。首先,我们在现实条件下分析了RAG,识别出检索不完美增强是RAG失败的一个重要因素,并指出知识冲突是克服它的主要瓶颈。其次,我们提出了智能RAG,它明确解决了LLM内部和外部知识之间的冲突,从而从RAG失败中恢复过来。第三,对各种LLMs和数据集的实验表明,即使在最具挑战性的场景下,智能RAG的有效性也得到了证明。
2. 检索不完美:RAG的陷阱
为了更好地展示常见的实际世界挑战,并为改进方法论设计提供更好的激励,我们在受控的数据集上评估了检索质量、端到端的RAG性能以及知识冲突。所选数据涵盖了来自NQ(Kwiatkowski等人,2019)、TriviaQA(Joshi等人,2017)、BioASQ(Tsatsaronis等人,2015)和PopQA(Mallen等人,2023)的广泛的一般性问题、特定领域问题和长尾问题。我们的分析基于使用谷歌搜索4作为检索器和网络作为语料库的逼真检索结果。这种设置使我们能够分析现实世界RAG中不完美检索的严重性。总体而言,我们从这些数据集中抽样了1K个短形式QA实例,并将每个实例与10个检索到的段落配对。
不完美检索很常见。我们检查检索到的段落中正确答案的出现情况,以此来近似检索质量。由于我们主要关注提供每个问题正确答案最多变体的短形式QA,通过字符串匹配的近似可以让我们对检索结果的精确程度有一个初步直觉。具体来说,我们将检索精度定义为包含每个实例正确答案的段落的比例:
Retrieval Precision={ number of total retrieved passages}{ number of retrieved passages containing correct answer}
如图2所示,尽管来自不同数据集的实例展示出不同的数据分布,但检索不完美是普遍存在的。具体来说,约20%的总数据在任意检索到的段落中没有提及正确答案,包括NQ中的34%,TriviaQA中的18%,BioASQ中的24%,以及PopQA中的50%。这一发现也与之前关于信息检索的研究结果一致(Thakur等人,2024年),该研究强调正例的数量可能非常有限。
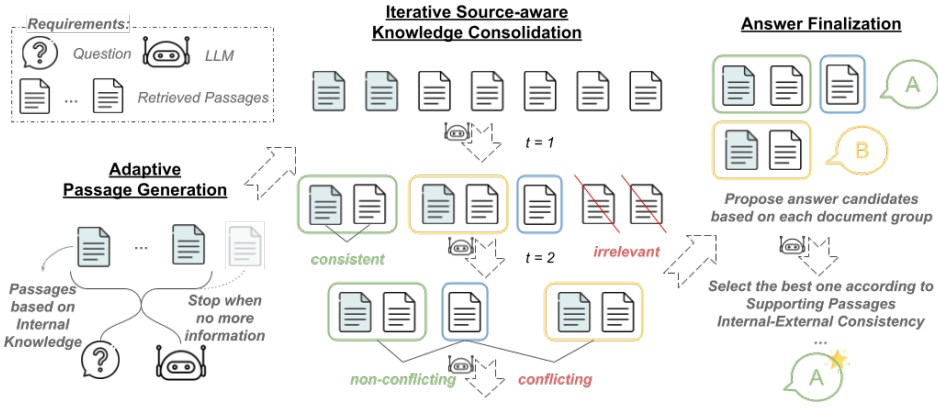
图3| 提出的ASTUTE RAG框架概览。ASTUTE RAG旨在通过采用整合机制来解决外部来源(例如网络、特定领域的语料库、知识库)和LLMs内部知识之间的信息冲突,从而更好地结合这些信息,最终生成质量更好的输出。
不完美的检索会导致RAG失败。我们进一步分析了检索质量和RAG性能之间的关系。我们比较了Claude 3.5 Sonnet在有无RAG情况下的性能,并在图4中报告了检索精确度的结果。一般来说,当检索精确度不低于20%时,RAG是有帮助的。当检索精确度接近0时,带有RAG的模型的性能比没有RAG的要差得多,这表明不完美的检索增强可能是RAG失败的原因。这一发现与Yu等人(2024年)之前的观察一致,即添加更多检索到的段落并不一定导致更好的性能,因为额外的段落可能会降低检索精确度。
在RAG失败中广泛存在知识冲突。我们提供了对LLMs内部知识和外部来源检索到的段落之间知识冲突的深入分析。以Claude 3.5 Sonnet作为LLM,图1显示,整体数据的19.2%展示了知识冲突,其中答案无论是否有RAG都是正确的。在冲突案例中,内部知识正确率为47.4%,而外部知识正确率为剩余的52.6%。这些结果强调了有效结合内部和外部知识以克服仅依赖任一来源的固有限制的重要性。然而,先前的工作(Jin等人,2024年;Tan等人,2024年;Xie等人,2024年)表明,在这种情况下,LLMs可能会基于误导性信息做出响应,而不是对冲突知识的全面理解。
3. ASTUTE RAG:克服陷阱
我们从制定RAG中不完美检索问题开始(第3.1节)。然后我们提供了ASTUTE RAG的概述,旨在克服这个问题(第3.2节)。随后,我们深入探讨ASTUTE RAG的三个主要步骤,包括自适应生成内部知识(第3.3节)、源感知知识巩固(第3.4节)和答案最终化(第3.5节)。
算法1 ASTUTE RAG
要求:查询q,检索到的段落E=[e1,…,en],大型语言模型M,迭代次数t,生成的段落最大数量m^,提示模板pgen,pcon,pans
1:自适应生成段落:I←M(pgen,q,m^)
▹ 第3.3节
2:结合内部和外部段落:D0←E⊕I
3:分配段落来源:S0←[1{d∈E} 对于d∈D0]
4:如果t>1,则
5:对于j=1,…,t−1,对j=1,…,t−1进行
第3.4节
6:巩固知识:⟨Dj+1,Sj+1⟩←M(pcon,q,⟨D0,S0⟩,⟨Dj,Sj⟩)
7:结束
8:最后巩固并回答:a←M(pans,q,⟨D0,S0⟩,⟨Dt−1,St−1⟩)
⊳ 第3.5节
9:否则
10:巩固知识并最终回答:a←M(pans,q,⟨D0,S0⟩)
11:如果结束
12:返回a
3.1. 问题构建
我们的目标是减轻不完美的检索增强效果,解决LLM内部知识与外部来源(如自定义/公共语料库和知识库)之间的知识冲突,并最终从LLM产生更准确和可靠的回答。
给定一组来自外部来源的检索段落E=[e1,…,en],一个预训练的LLM M(通过仅预测的API访问,包括商业黑盒API),以及一个查询q,任务是生成相应的正确答案a∗。值得注意的是,这种设置与之前关于改进检索器、训练LLM或进行自适应检索的工作正交,这些主要是初步步骤。
3.2. 框架概览
ASTUTE RAG旨在更好地利用LLM内部知识和外部语料库的集体知识,以产生更可靠的回答。如图3和算法1所示,ASTUTE RAG从获取LLMs内部知识中最准确、相关且全面的段落集合开始。然后,通过比较生成的段落和检索到的段落,以迭代的方式整合内部和外部知识。最后,比较冲突信息的可靠性,并根据最可靠的知识生成最终输出。
3.3. 内部知识的自适应生成
在第一步中,我们从LLMs中提取内部知识。这种反映广泛预训练和指令调整数据共识的LLM内部知识,可以补充有限检索段落集中缺失的信息,并使LLM内部和外部知识之间实现相互确认。当大多数检索到的段落可能是无关紧要或误导性的时候,这一点尤其宝贵。具体来说,我们引导LLMs基于给定的问题q生成段落,遵循Yu等人(2023a)的方法。虽然Yu等人(2023a)主要关注生成多样化的内部段落,但我们强调生成段落的可信度和可靠性的重要性。为了实现这一目标,我们通过宪法原则和自适应生成增强了原始方法。
受到宪法AI(白等人,2022年)的启发,我们提供了指示在指令pgen中期望的内部段落属性的宪法原则(详见附录A)。为了指导它们的生成,强调生成的段落应该是准确、相关且无幻觉的。此外,我们允许大型语言模型(LLM)在其内部知识中进行自适应段落生成。LLM可以决定自己生成多少段落。我们不是固定生成一定数量的段落,而是要求LLM最多生成m^个段落,每个段落覆盖不同的信息,并直接指示是否有更可靠的信息可用。这种自适应方法允许LLM在内部知识中有用的信息有限时生成较少的段落(甚至根本不生成段落),而在内部知识中有多个可行答案时生成更多段落。在这一步中,LLM根据其内部知识生成m≤m^个段落:
I=[i1,…im]=M(pgen,q,m^).
3.4. 迭代源感知知识整合
在第二步中,我们利用LLM来显式整合其内部知识和外部来源检索到的段落信息。最初,我们将内部和外部知识来源的段落合并为 D0=E⊕I。
我们还通过向LLMs提供每个段落的信息(内部或外部,例如网站)来确保源感知性。源信息(内部或外部,如网站)有助于评估段落的可信度。在这里,我们提供段落源为 S0=[1{d∈E},对于 d∈D0]。
为了整合知识,我们指导LLM(附录A中的 pcon)识别段落之间的一致信息,检测每组一致段落之间的冲突信息,并过滤掉不相关信息。这一步会将输入段落中的不可靠知识重新分组到更少的精炼段落中。重新分组后的段落还将将它们的来源归因于相应的至少一个输入段落。
⟨Dj+1,Sj+1⟩=M(pcon,q,⟨D0,S0⟩,⟨Dj,Sj⟩).
我们发现,在比较冲突知识的可信度以及解决知识冲突方面,这一点尤其有帮助。此外,这个知识巩固过程可以迭代运行t次,以使上下文变得越来越有用。当上下文较长时,用户可以分配更多的迭代次数。
3.5. 答案最终确定
在最后一步中,我们指导LLM(附录A中的pans)基于每组段落(⟨Dt,St⟩)生成一个答案,然后比较它们的可信度,并选择最可靠的答案作为最终答案。这种比较允许LLM在做出最终决策时全面考虑知识来源、跨源确认、频率和信息完整性。值得注意的是,这一步可以合并到最后的知识巩固步骤中,使用综合的指令来减少推断复杂性(预测API调用的数量):
a=M(pans,q,⟨D0,S0⟩,⟨Dt,St⟩).
当t=1时,初始通道将被直接输入模型进行知识巩固和后续回答:a=M(pans,q,⟨D0,S0⟩)。
4. 实验
我们评估ASTUTE RAG在克服不完美检索增强和解决知识冲突方面的有效性。在本节中,我们首先详细介绍实验设置。
| Method | #API Calls | NQ∥ | TriviaQA | BioASQ | PopQA | Overall |
| Cuude 3.5 Sonnet(20240620) | Cuude 3.5 Sonnet(20240620) | Cuude 3.5 Sonnet(20240620) | ||||
| No RAG | 1 | 47.12 | 81.98 | 50.35 | 29.78 | 54.51 |
| RAG | 1 | 44.41 | 76.68 | 58.04 | 35.96 | 55.47 |
| USC(Chen et al.,2024b) | 4 | 48.14 | 80.21 | 61.54 | 37.64 | 58.73 |
| GenRead(Yu et al.,2023a) | 2 | 42.03 | 74.20 | 56.99 | 34.27 | 53.55 |
| RobustRAG(Xiang et al.,2024) | 11 | 47.80 | 78.09 | 56.29 | 37.08 | 56.53 |
| InstructRAG(Wei et al.,2024) | 1 | 47.12 | 83.04 | 58.04 | 41.01 | 58.83 |
| Self-Route(Xu et al., 2024a) | 1-2 | 47.46 | 78.80 | 59.09 | 41.01 | 58.06 |
| ASTUTE RAG(t=1) | 2 | 52.20 | 84.10 | 60.14 | 44.38 | 61.71 |
| ASTUTE RAG(t=2) | 3 | 53.22 | 84.45 | 61.89 | 44.94 | 62.67 |
| ASTUTE RAG(t=3) | 4 | 53.56 | 84.45 | 62.24 | 44.94 | 62.86 |
表1| 在零样本设置下对Claude的主要结果,显示了不同基准方法与AsTUTE RAG的准确性,以及它们在预测API调用次数方面的预测复杂性。最佳分数以粗体显示。
(第4.1节)。然后,我们在多样化数据集上比较了ASTUTE RAG与各种基线的性能(第4.2节)。最后,我们提供了深入的分析(第4.3节)。
4.1. 实验设置
数据集和评价指标。我们在第2节收集的数据上进行实验,这些数据包括NQ、TriviaQA、BioASQ和PopQA的数据。对于这些数据集中的每个实例,我们提供在真实检索设置下收集的10段文章:对于我们基准中的每个问题,我们查询Google Search以检索前三十个结果,并选择前10个可访问网站。从每个检索到的网站中,我们提取与Google Search结果中提供的片段相对应的段落作为检索到的文章。大多数检索结果包含自然噪声,其中包含不相关或误导性的信息。我们不考虑对检索侧的增强,例如查询重写,因为这样的增强通常已经融入商业信息检索系统中。值得注意的是,我们不基于检索结果选择问题或注释答案。这种设置使我们能够分析现实世界RAG中不完美检索的严重性。它区分了我们的基准测试与之前使用合成检索错误或无意中通过有偏的构建协议降低不完美检索频率的基准测试(Chen等人,2024a;Yang等人,2024)。我们还评估了我们的方法在RGB(Chen等人,2024a)上的表现,这是一个评估几种关键RAG能力的RAG诊断基准测试。具体来说,我们选择了关注噪声鲁棒性的RGB英文子集。该基准测试为每个问题提供了正面和负面的语料集。我们选择每个问题五个负面文档作为最坏情况来形成上下文。这些数据集中的所有数据都是短形式的QA。遵循之前的工作(Mallen等人,2023;Wei等人,2024;Xiang等人,2024),如果模型响应包含真实答案,则认为模型响应是正确的。为了提高评估的可靠性,我们引导LLMs将确切答案封装在特殊标记内,并提取它们作为最终响应。
LLMs和RAG的一般设置。我们在两个高级LLMs上进行了实验,包括Gem-ini 1.5 Pro5(gemini-1.5-pro-002)和Claude 3.5 Sonnet6(claude-3-5-sonnet@20240620)。生成温度设置为0,最大输出标记设置为1024,除非另有说明。默认情况下,语料按反向顺序呈现在提示中。
| Method | #API Calls | NQ∥ | TriviaQA | BioASQ | PopQA | Overall |
| Gemini 1.5 Pro(002) | Gemini 1.5 Pro(002) | Gemini 1.5 Pro(002) | ||||
| No RAG | 1 | 44.75 | 80.21 | 45.80 | 25.28 | 51.34 |
| RAG | 1 | 42.71 | 75.97 | 55.24 | 33.71 | 53.65 |
| USC(Chen et al.,2024b) | 4 | 46.44 | 76.68 | 58.39 | 37.64 | 56.43 |
| GenRead(Yu et al.,2023a) | 2 | 45.08 | 77.39 | 54.90 | 34.27 | 54.70 |
| RobustRAG(Xiang et al.,2024)8 | 11 | 34.24 | 67.49 | 44.06 | 32.02 | 45.59 |
| InstructRAG(Wei et al., 2024) | 1 | 46.78 | 80.57 | 54.90 | 34.83 | 56.14 |
| Self-Route(Xu et al., 2024a) | 1-2 | 47.46 | 79.86 | 58.04 | 38.20 | 57.58 |
| ASTUTE RAG(t=1) | 2 | 50.17 | 81.63 | 58.04 | 40.45 | 59.21 |
| ASTUTE RAG(t=2) | 3 | 51.53 | 81.27 | 58.74 | 40.45 | 59.69 |
| ASTUTE RAG(t=3) | 4 | 48.47 | 80.21 | 60.14 | 42.13 | 59.21 |
表2| 在零样本设置下的双子座主要结果,显示了不同基准方法与AsTUTE RAG的准确性,以及它们预测复杂度在预测API调用次数方面的表现。最佳分数以粗体显示。
实验是在零样本设置下进行的,用于受控评估,不提供QA或特定于方法的步骤演示。
基线。我们将ASTUTE RAG与各种旨在增强鲁棒性和代表性推理策略的RAG方法进行了比较,这些策略旨在提高响应的可信度。USC(陈等人,2024b)是一种通用自一致性方法,它给定相同的上下文采样多个LLM响应,并聚合答案。它提供了一个使用额外API调用进行朴素改进的参考。在这个基线中,采样响应的温度设置为0.7。Genread(余等人,2023a)通过增加LLM生成的段落来增强检索到的段落。它提供了一个在没有有效结合内部和外部知识的情况下,在指令中呈现来自内部和外部知识的段落的参考。RobustRAG(向等人,2024)聚合每个独立段落中的答案,以提供可验证的鲁棒性。我们使用关键词聚合变体,因为它被证明是高级LLM上表现最好的变体。InstructRAG(魏等人,2024)指导LLM提供将答案与段落中的信息联系起来的理由。为了公平比较,我们使用了没有训练或上下文学习的指令。Self-Route(徐等人,2024a)自适应地在带有和不带有RAG的LLM之间切换。7 这个基线提供了在LLMs内部和外部知识之间切换的参考。
ASTUTE RAG的实施细节。ASTUTE RAG的即时模板可以在附录A中找到。默认情况下,我们每次查询使用2个API调用,设置t=1以合并知识巩固和答案最终化的即时模板。对于自适应生成内部知识,我们提示LLM生成不超过一个段落。
4.2. 主要结果
表1和表2展示了每个数据集的真实检索增强结果。通过比较RAG和No RAG,我们发现检索到的段落可能并不总是对下游性能有益——在NQ和TriviaQA上,RAG的性能落后于No RAG。我们将这归因于LLM内部知识和检索结果中的噪声误导了LLM。相比之下,在专注于特定领域和长尾问题的BioASQ和PopQA上,RAG显著提高了LLM的性能。然而,由于检索增强不完美,绝对性能仍然不尽如人意。在所有基线中,没有任何单一方法在所有数据集上都始终优于其他方法。这一观察突显了这些基线是为不同的设置量身定制的,可能不具有普遍适用性。例如,在TriviaQA上,InstructRAG更为有效,它在Claude和Gemini两个基线中都取得了最佳性能。相比之下,Self-Route在NQ和BioASQ上的表现都优于InstructRAG。此外,RobustRAG在应用于Gemini和Claude时表现出非常不同的性能。通过深入分析,我们发现带有Gemini的RobustRAG在响应中表现出较高的拒绝率(拒绝回答)。我们将这种不稳定性归因于基线方法设计的不同,这些设计是为不同的场景量身定制的,导致跨数据集的改进不一致。总体而言,InstructRAG和Self-Route在应用于Claude和Gemini时表现出了所有基线中最优的性能。我们还注意到,增加API调用次数并不一定与提高性能相关。
ASTUTE RAG在所有具有不同属性的数据集中始终优于基线。与最佳基线相比,整体改进在Claude上相对为6.85%,在Gemini上为4.13%,并且在特定领域的问题上的改进要高得多。这些结果突显了ASTUTE RAG克服不完美检索增强的有效性。在Claude上,增加知识巩固的迭代次数会导致一致的改进。当t变大时,改进幅度变小。这是因为每次迭代后,知识巩固的剩余改进空间变得更小。在Gemini上,增加t主要有利于BioASQ和PopQA。这两个数据集更多地依赖于外部知识,迭代的知识巩固有助于减轻这些外部信息中的噪声。当t达到3时,NQ和TriviaQA的性能不再进一步改善。我们将这归因于外部知识在这些数据集中作用不那么关键。为了设定一致性和效率,我们将参数设置得较小,限制了内部知识的影响。
4.3. 分析
检索精确度的性能。我们比较了ASTUTE RAG和基线在不同子集上的性能,这些子集按它们的检索精确度划分,使用Claude作为大型语言模型(LLM)对我们的收集数据进行比较。如图4所示,AsTUTE RAG在所有不同检索精确度下都比所有基线表现始终更好,表明它在提高广泛场景下的RAG可信度方面的有效性。值得注意的是,ASTUTE RAG并不牺牲在高检索质量下的性能提升,以换取低检索质量下的改进。当检索质量极低(接近零检索精确度)时,除了提出的ASTUTE RAG之外,所有其他RAG变体都表现不如’无RAG’基线。这一观察结果与RGB上的最坏情况结果一致。它展示了克服不完美检索增强的难度,并验证了ASTUTE RAG在这方面的有效性。
解决知识冲突的有效性。我们将收集的数据分为三个子集,根据Claude的答案,包括有无RAG的情况。两种推理方法的答案可以是正确的、错误的,或者一个正确一个错误。这三个子集代表了内部知识和外部知识之间的三种情况。结果显示在图4中。在冲突子集上,AsTUTE RAG成功选择了大约80%的正确答案,这是解决知识冲突最有效的方法。值得注意的是,As TUTE RAG甚至在内部知识或外部知识单独无法得出正确答案的子集上也能带来性能提升。这表明ASTUTE RAG可以有效地结合来自LLM内部和外部知识的部分正确信息,以解决问题。
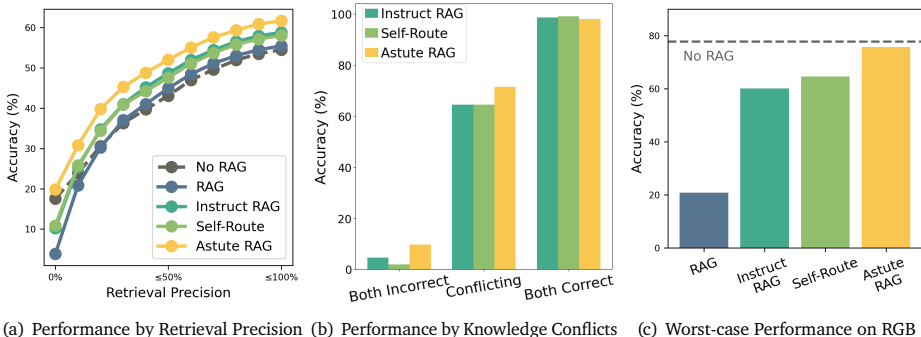
图4| 分析结果。(a) 根据检索精度对不同桶中的Claude性能进行排名。(b) No RAG与RAG之间冲突且一致实例上的Claude性能。(c) RGB上Claude的最坏情况性能,所有检索到的段落都是负面的。ASTUTE RAG的性能接近No RAG,而其他RAG系统则远远落后。
通过跨它们之间的集体信息来达到正确答案。
RGB上的最坏情况性能.. 图4展示了在RGB上所有检索文档都是负面的最坏情况设置下的结果。它展示了ASTUTE RAG和基线RAG方法的噪声鲁棒性。RAG与No RAG之间的性能差距超过50点,突出了不完美检索结果的不利影响,并强调了提供针对最坏情况场景的稳健保障的重要性。虽然基线RAG方法优于原始RAG,但它们仍然明显落后于No RAG。ASTUTE RAG是唯一在最坏情况设置下达到接近No RAG性能的RAG方法,进一步支持其在解决不完美检索增强方面的有效性。
定性研究。在图5中,我们展示了两个代表性的例子,展示了ASTUTE RAG的中间输出。在第一个例子中,没有RAG的LLM生成了一个错误的答案,而RAG返回了一个正确的答案。ASTUTE RAG成功地识别出其生成段落和一个外部段落中的错误信息,避免了Tan等人(2024)的确认偏见。在第二个例子中,仅LLM是正确的,而RAG由于噪声检索结果而错误。专家RAG通过检查其内部知识从噪声检索信息中检测到正确答案。
5. 相关工作
检索增强生成(RAG)旨在解决LLMs固有的知识限制,这些LLMs是从外部信息源(如私有语料库或公共知识库)检索的段落(Borgeaud等人,2022年;Guu等人,2020年;Lewis等人,2020年)。鉴于RAG在各种现实世界应用中的广泛应用,包括风险敏感领域,检索到的段落内噪声信息的负面影响引起了越来越多的关注(Cuconasu等人,2024年)。最近的工作已经从多个角度寻求增强RAG系统对噪声的鲁棒性,包括用噪声上下文训练LLMs(Fang等人,2024年;Pan等人,2024年;Yoran等人,2024年;Yu等人,2023b),训练小模型以过滤掉不相关的段落(Wang等人,2023c;Xu等人,2023年),段落重新排名(Glass等人,2022年;Yu等人,2024年),动态和迭代检索(Asai等人,2023年;Jiang等人,2023年;Yan等人,2024年),查询重写(Ma等人,
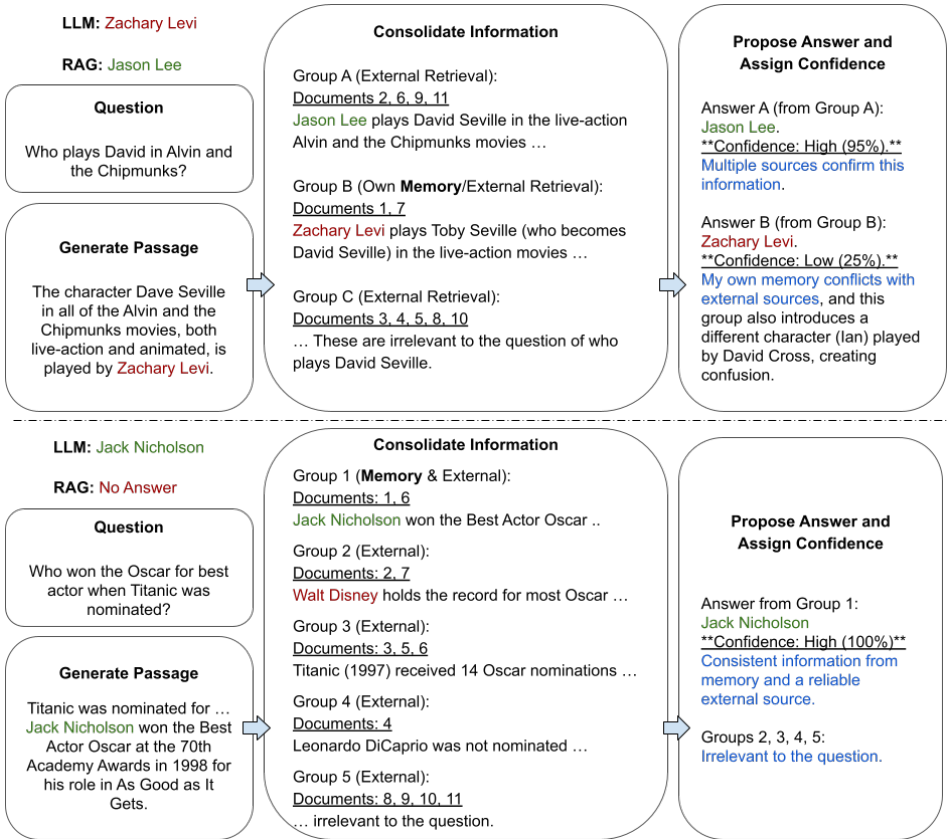
图5| 定性示例。上图:RAG研究所通过外部来源确认内部知识(即生成的段落)中的错误。下图:ASTUTE RAG通过检查其内部知识从嘈杂检索信息中检测到正确答案。标准RAG不提供答案,因为检索到的段落太嘈杂。
2023年),以及推测性起草(Wang等人,2024年)。这些研究关注RAG系统的不同模块或阶段,并且与我们的工作正交。
我们的工作侧重于在检索段落提供后,增强RAG的鲁棒性。在这个主题上,RobustRAG(Xiang等人,2024年)汇总每个独立段落中的答案,以提供可验证的鲁棒性。InstructRAG(Wei等人,2024年)指导LLM提供将答案与段落中的信息联系起来的理由。MADRA(Wang等人,2023b年)应用多智能体辩论来选择有用的证据。然而,这些工作并没有明确纳入内部知识来恢复RAG失败,因此在大多数检索段落都是负面的情况下可能会崩溃。在强调RAG中LLM的内部知识方面,最近的工作探索了使用LLM生成的段落作为上下文(Yu等人,2023a; Zhang等人,2023年),在有无RAG的LLM之间自适应切换(Jeong等人,2024年; Mallen等人,2023年; Xu等人,2024a年),以及通过对比解码结合内部和外部知识答案(Jin等人,2024年; Zhao等人,2024年)。我们专注于一个不需要进一步训练的黑箱设置,直接解决知识冲突,结合双方的有益信息,实现更可靠的答案。
结论
我们的论文研究了不完美检索对RAG系统性能的影响,并将知识冲突识别为关键挑战。为了解决这个问题,我们引入了ASTUTE RAG,这是一种利用大型语言模型(LLMs)内部知识并迭代地通过整合内部和外部知识以源方式改进生成响应的新方法。我们的实证结果表明ASTUTE RAG在减轻不完美检索的负面影响和提高RAG系统的鲁棒性方面是有效的,特别是在外部来源不可靠的挑战性场景中。
在局限性方面,ASTUTE RAG的有效性取决于具有强指令遵循和推理能力的先进LLMs的能力,因此可能适用于较不复杂的LLMs的能力有限。作为未来重要的发展方向,扩展实验设置以包括更长的输出将是重要的,其中不完美检索和知识冲突的挑战可能更加明显。此外,对各种上下文类型影响的全面分析(Balachandran等人,2024年)将增强对所提方法有效性的理解。未来的工作还可以将我们的方法扩展到LLMs和RAG之外,例如在多模态设置中解决知识冲突(Zhu等人,2024年)。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![Exploitation of a Latent Mechanism in GraphContrastive Learning: Representation Scattering[图对比学习中潜在机制的开发:表征散射]-AI论文](https://assh83.com/wp-content/uploads/2024/12/image-11-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)