1.摘要
摘要部分,论文提出了一种名为SynthVLM的创新数据合成管道,旨在提升视觉语言模型(VLLM)的数据效率和质量。随着网络图像的大量涌现,如何有效管理和理解大规模图像数据集变得愈加重要,而VLLM的训练需要大量数据,这给效率、数据质量和隐私保护带来了挑战。
SynthVLM与现有方法不同,采用“文本生成图像”的策略,利用先进的扩散模型,从高质量的文本描述中生成高分辨率图像,进而生成精确对齐的图文对。通过这些合成数据,SynthVLM在多个视觉问答任务中实现了最先进的性能,同时保持高质量的对齐效果和语言能力。此外,SynthVLM比传统的基于GPT-4 Vision的图像生成方法效率更高,计算开销显著减少,同时仅使用10万条数据(为官方数据集规模的18%)便达到了优异的效果,且避免了数据隐私问题。
通过纯生成的数据集,SynthVLM不依赖真实数据,有效保护了隐私,并且在多项基准任务上实现了最先进的性能。论文中也提供了代码,以便进一步研究和应用。
2.引言
在引言部分,作者首先阐述了大规模语言模型(LLMs)和多模态大语言模型(MLLMs)近年来的快速发展。伴随着技术进步,数据管理成为这些技术的关键环节,数据的处理、选择与管理被认为对模型性能有显著影响。在多模态语言模型中,视觉语言模型(VLLM)展示了强大的视觉理解和语言处理能力,在图像分类、图像理解、图像字幕生成等传统多模态任务中表现出色。此外,这些模型还在文本丰富的任务中有出色的表现,如视觉问答和图文检索。

尽管现有VLLM的主要研究方向集中在模型架构的改进上,以更好地融合多模态信息,作者强调数据质量对VLLM成功的重要性。部分研究指出,优质的训练数据能够显著提升VLLM的表现。例如,现有的一些研究证明了高质量的数据能够带来更优的视觉问答与字幕生成效果。
在当前的VLLM方法中,数据生成与对齐策略面临以下几个主要问题:
- 数据质量低下
:现有的数据集在多模态对齐方面表现不佳。网络图像通常存在模糊、水印等问题。自动生成的字幕数据经常存在逻辑不一致和语法错误,这些问题会影响VLLM的语言能力。
- 低效性
:低质量数据会导致模型性能的下降,且依赖人工标注的方法成本高,自动化标注方法(如GPT-4 Vision)成本同样昂贵且难以扩展。
- 效率低
:目前的策略通常需要构建大规模的数据集来提高模型性能,容易导致数据冗余。
- 隐私风险
:网络数据存在隐私和安全问题,可能包含个人信息或版权内容,从而带来法律与道德风险。
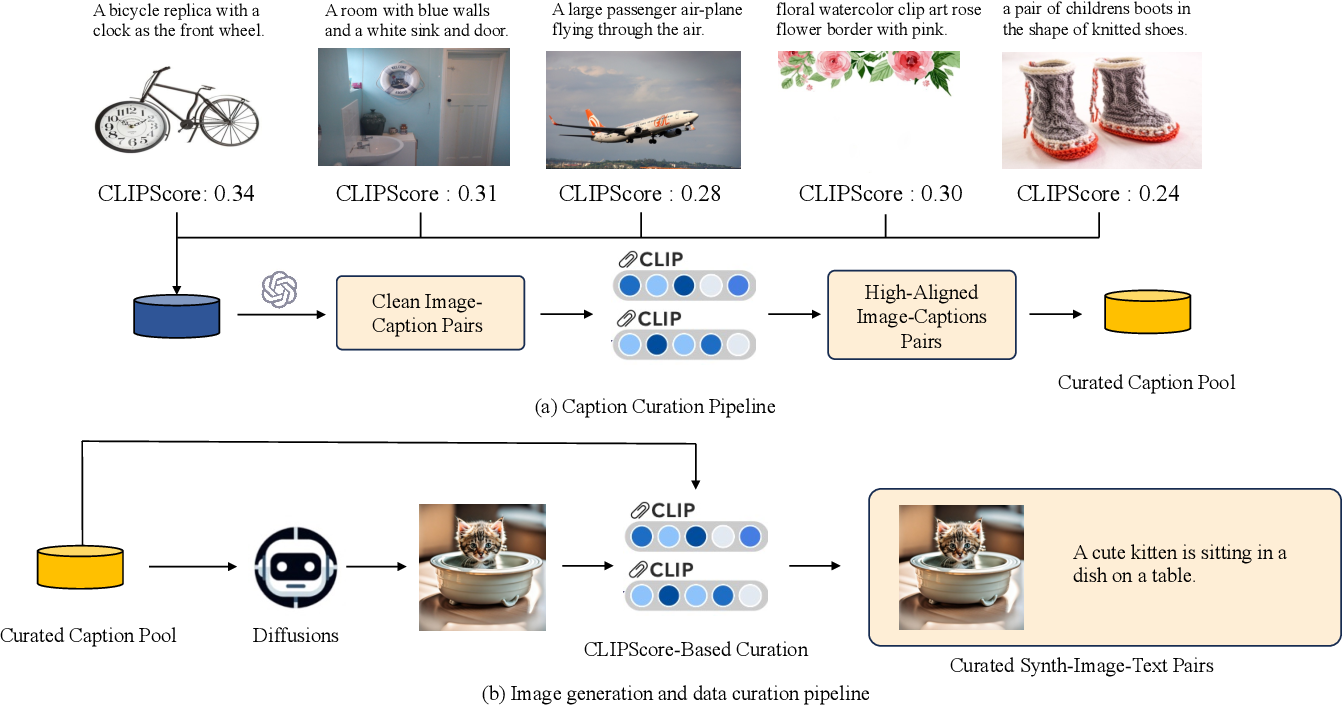
针对这些问题,作者提出了一个全新的数据生成管道:从文本生成图像。该管道首先对高质量的文本描述数据进行筛选,然后通过扩散模型从这些文本描述生成图像,再根据CLIPScore筛选高质量的图文对。生成的图文对在图像和描述之间实现了更高的对齐度。通过100,000条精选数据,SynthVLM在多个基准任务中达到了最先进的性能,且仅使用了官方数据集规模的18%。

本论文的主要贡献包括:
- 新视角
:首次提出了“文本到图像”策略构建高对齐的VLLM训练数据集,且仅使用10万条数据便达到了优异性能。
- 新方法
:提出了一个新的图文对生成管道,确保数据的高质量。
- 最先进性能
:生成的数据在CLIPScore评估中表现出色,且对语言任务和视觉任务均表现优异。
- 数据隐私保护
:通过生成数据,避免了使用真实数据,从而有效保护隐私。
引言部分概述了当前VLLM领域所面临的挑战,并提出SynthVLM的独特数据生成方法及其优越的性能和数据隐私保护效果。

3.相关工作
在相关工作部分,论文总结了SynthVLM相关领域的研究背景,分为四个主要方面:扩散模型、视觉语言模型、数据质量和选择、数据生成。
3.1 扩散模型
扩散模型(Denoising Diffusion Probabilistic Models, DDPMs)是一类生成模型,以生成高质量图像著称。其核心思想是在正向过程中逐渐对输入图像添加高斯噪声,建模数据分布;在反向过程中,模型则通过去噪恢复图像。DDPMs在图像生成、图像翻译、图像修复等任务中取得了优异表现。

论文指出,尽管DDPMs在样本质量和生成效率方面展示了卓越的潜力,但研究者们提出了多种方法进一步提高其效率和样本质量。SynthVLM利用扩散模型来生成高质量的图文对,为视觉语言模型(VLLM)的训练提供了多样且优质的数据,从而提升模型在下游任务(如图像字幕生成和视觉问答)中的表现。

3.2 视觉语言模型
随着大语言模型的进步,集成视觉信息的视觉语言模型(VLLM)成为研究的重点。VLLM结合了视觉编码器和大语言模型,使模型能够更好地处理和理解图像输入,并应用于多种视觉任务。现有的VLLM研究框架(如CLIP、LLaVA、BLIP等)通过对比学习或跨模态注意力等技术,使图像和文本间更好地对齐。
许多研究工作旨在通过改进预训练和微调数据集质量,以提升VLLM的性能。尽管这些改进有助于模态间的对齐,现有方法仍然依赖庞大的数据集,这可能会削弱模型的语言处理能力。论文提出了一种新的数据生成策略,通过高质量的图文对提升VLLM的性能,并在预训练阶段对齐图像和文本模态,从而增强模型的语言能力。
3.3 数据质量和选择
在大语言模型的训练中,数据的质量和数量至关重要。尽管大规模数据可以捕捉复杂的语言模式,低质量数据则可能导致模型学习错误的模式,影响预测精度。
高质量数据的筛选是确保模型性能的关键,现有的研究多使用基于LLM的数据选择方法。例如,有些方法利用DeBERTa等模型对数据评分,以筛选出高质量的数据;另一些方法则通过GPT-4对数据进行重写,提升其复杂性和质量。为提升VLLM的性能,本论文结合了LLM数据选择方法和图文对齐评分(如CLIPScore),以便高效筛选出优质数据。

3.4 数据生成
合成数据的生成是提升大模型性能的重要驱动力,尤其是在获取高质量大规模数据困难的情况下。近年来,生成合成数据的技术取得了显著进展,合成数据不仅可以弥补数据匮乏,还能够在不涉及实际用户数据的情况下,帮助保护隐私。
在VLLM领域,合成数据生成策略仍处于相对早期的阶段。目前的方法主要关注图像和描述的对齐,例如ShareGPT4V通过GPT-4 Vision生成图像的高质量描述。虽然这些方法在提升对齐效果上取得了一定进展,但成本较高,生成的数据对齐效果仍有提升空间。SynthVLM提出了一种新的图文对齐策略,利用文本生成图像,生成的高质量图文对不仅提升了模型的对齐度,还降低了成本与隐私风险。
总结
通过回顾扩散模型、视觉语言模型、数据质量与选择,以及数据生成的研究,作者指出SynthVLM的独特之处:通过文本生成图像来构建VLLM训练数据集,确保数据对齐和隐私保护。相关工作的总结为SynthVLM的创新和有效性奠定了基础。
4.方法
在方法部分,论文详细介绍了SynthVLM的数据生成与选择流程。该部分分为四个小节,分别是:合成数据集构建、合成数据选择、高质量合成数据集的生成、以及SynthVLM的总体框架。
4.1 合成数据集构建
论文首先描述了如何构建用于VLLM训练的合成数据集:
- 数据源选择
:为了确保描述的多样性,SynthVLM结合了人类生成和机器生成的文本描述数据。人类生成的描述数据主要来自LAION、CC和SBU等公开数据集;机器生成的数据则利用BLIP2等技术,从数据集中生成的图像中提取描述。
- 描述筛选
:在生成图像之前,首先筛除质量较低的描述(如含广告信息、语法错误等),通过GPT-3对描述进行质量评估,保留高质量描述。这一步为生成图像提供了基础。
- 图像生成
:通过扩散模型(Stable Diffusion XL, SDXL),从经过筛选的文本描述生成高质量的图像。SDXL的参数设定为60个扩散步,并使用8块A100 GPU,在约一周时间内生成了所有图像。最终,生成的图像分辨率为1024×1024,有效解决了现有数据集分辨率较低的问题。
4.2 合成数据选择
为了进一步确保生成的图文对之间的对齐性,论文在生成图像后引入了数据选择机制:
- CLIPScore 计算
:论文首先对生成的100万对图文对计算CLIPScore。CLIPScore是图像与描述之间的相似度评分,通过衡量描述与图像特征的余弦相似度,来评估图文对的质量。
- 筛选高质量图文对
:在初步评分后,论文选取了评分最高的前10万对图文对作为最终训练集。这个筛选过程保证了图文对的精确匹配,使得最终的数据集具有高度对齐和语义一致的特点。
4.3 高质量合成数据集
通过图像生成和数据选择,SynthVLM构建了一个高质量的合成数据集,并与现有数据集进行对比,突出其优势:

- 图像质量
:生成的数据集在图像质量上大幅提升,提供了1024×1024像素的高分辨率图像。与现有数据集相比,SynthVLM的数据有效避免了模糊、水印等问题,并通过更高的CLIPScore,展示了更优的图文对齐效果。

- 图文对齐
:SynthVLM的数据集在CLIPScore测试中表现优越,超越了COCO-Caption、BLIP-LCS和ShareGPT4V等数据集。通过更精准的图文对齐,数据集具备了更好的图文匹配能力。
- 数据隐私保护
:SynthVLM通过纯合成的图像生成,避免了使用真实图片,保障了数据隐私。该方法在保证数据高质量的同时,满足了隐私合规的需求。

4.4 SynthVLM 总体框架
最后,论文介绍了SynthVLM在VLLM训练中的应用框架,包括两个主要阶段:
- 预训练阶段
:首先使用合成数据对视觉语言模型中的投影层进行预训练,以在图像和文本模态之间实现初步对齐。在此阶段,采用前述生成的10万对高质量图文对数据集。
- 监督微调阶段
:在预训练基础上,结合LLaVA 665k数据集,对投影层和LLM进行进一步训练,提升模型的视觉理解能力。
通过这两个训练阶段,SynthVLM在保持高效和隐私保护的同时,实现了多模态对齐和优异的模型性能。
5.实验
在实验部分,论文通过多个实验验证了SynthVLM方法的有效性和性能优势。该部分分为六个小节,分别是:实验设置、合成数据的性能验证、有效的视觉语言对齐、高效的视觉语言对齐、隐私保护预训练、以及消融实验。
5.1 实验设置
在实验设置部分,作者介绍了所用的数据集、模型、基线方法及评价基准:
- 数据集
:实验中使用了558k的LLaVA预训练数据集、665k的LLaVA微调数据集,以及SynthVLM合成的10万条数据集。
- 模型
:图像生成模型选用SDXL(Stable Diffusion XL),并设置60个生成步数。视觉语言模型的架构基于LLaVA 1.5,采用13亿参数的版本来提高视觉理解能力。视觉编码器选择了CLIP 336,并设置了14块图像补丁,语言模型部分使用了13B参数的Vicuna v1.5。
- 基线方法
:实验中的基线方法为官方LLaVA 1.51模型,该模型采用Vicuna v1.5 7B和13B版本。
- 评价基准
:视觉理解任务使用了SQA_Img、MMVet、VizWiz、VQAv2、GQA、MME和PoPE等基准数据集;纯文本任务则使用了MMLU和SQA,评估模型的语言理解能力。

5.2 合成数据的性能验证
为验证SynthVLM合成数据的性能,作者在基准模型LLaVA 1.5的基础上进行实验:
- 模型对比
:首先,作者在LLaVA 1.5模型基础上加入10万条合成数据进行预训练,之后结合LLaVA 665k数据集进行微调,得到“Synth Select 100k”模型。该模型与基线模型LLaVA 1.5(使用558k数据预训练、665k数据微调)进行比较。
- 性能结果
:实验结果表明,在视觉和语言任务上,Synth Select 100k模型超越了基线模型,特别是在视觉基准SQA_Img、MMVet、VizWiz、VQAv2、GQA等任务中取得了显著优势,展现出较强的视觉语言任务处理能力。

5.3 有效的视觉语言对齐
为了评估模型的模态对齐效果,作者在监督微调阶段使用了纯语言任务:
- 评估方法
:在视觉理解任务训练中,模型的语言能力可能会受到影响。为此,作者选用了MMLU和SQA基准数据集来测试模型的纯语言理解能力,从而间接评价模态对齐的效果。
- 实验结果
:结果显示,Synth Select 100k在所有MMLU和SQA基准数据集上均优于基线模型,证明了合成数据的高效对齐能力。这进一步显示了使用合成数据来进行模态对齐的可行性。
5.4 高效的视觉语言对齐
本小节探讨了SynthVLM在数据利用效率和计算资源方面的优势:
- 计算资源使用
:相比LLaVA基线数据,SynthVLM的数据量减少了81%以上,表明其数据筛选模块显著降低了资源需求,同时在多项基准任务中依旧达到或超过了基线性能。
- 数据利用效率
:通过将传统方法与SynthVLM方法的效率进行比较,结果显示,SynthVLM的数据需求远低于基线方法,而生成的1,000,000对图文对所需的存储量也远小于传统方法的50GB。SynthVLM仅使用330MB的描述数据即生成了庞大的图文对数据集,展示了文本生成图像策略在数据高效生成上的潜力。
5.5 隐私保护预训练
为了探讨SynthVLM在隐私保护方面的优势,作者通过对比生成图像和真实图像,展示了合成数据在隐私保护上的效果:
- 隐私保护实例
:实验中展示了包含人脸的真实图像和不含人脸的合成图像,以及带有车牌的真实图像和隐去车牌信息的合成图像。结果表明,合成数据可以在保持数据统计特征的同时避免个人隐私暴露,确保隐私合规。
- 隐私保护总结
:作者指出,通过扩散模型生成的合成数据可以保护用户隐私,符合隐私保护的需求,这为数据共享、模型训练和分析提供了安全的途径。
5.6 消融实验
消融实验探讨了数据生成和数据选择模块在SynthVLM中的重要性:
- 去除数据生成模块
:在没有数据生成模块的情况下,模型在各项基准上的表现显著下降,表明数据生成模块对维持模型性能至关重要。同时,合成数据的加入为模型构建高质量的模态对齐数据集提供了支持。
- 去除数据选择模块
:当数据选择模块被移除时,模型性能同样出现明显下降。这表明,数据选择模块通过筛选生成数据中的低质量部分,显著提升了模型的最终性能。
- 消融实验总结
:消融实验表明数据生成和数据选择模块对SynthVLM至关重要,为模型设计提供了优化参考。
总结
实验部分的六个小节展示了SynthVLM在性能、对齐效率、隐私保护和资源利用等方面的优越性。通过对比实验和消融分析,论文验证了合成数据在VLLM模型中的有效性,并表明了数据生成与选择策略对提升模型性能的重要性。
6.结论
在结论部分,作者总结了SynthVLM在视觉语言模型(VLLM)训练中的贡献和优势,并提出了未来的可能研究方向。SynthVLM的关键创新点在于其独特的图文对生成策略,这种策略不仅能提高数据质量和对齐效果,还能有效保护隐私,并显著减少计算资源需求。以下是结论部分的要点:
- 数据生成的创新性
:论文首次提出了利用“文本生成图像”的方法来生成VLLM训练数据集,确保生成的数据具有高度的图文对齐性。该策略不仅突破了传统图像描述生成的局限性,而且大大降低了对真实数据的依赖,为数据隐私保护提供了全新思路。
- 卓越的性能和对齐效果
:通过仅使用10万条合成数据,SynthVLM在多个基准任务上实现了与传统方法相媲美甚至超越的表现。这表明合成数据在视觉和语言模态对齐任务中的有效性,展示了合成数据在保持模型性能的同时减少数据规模的潜力。
- 隐私保护优势
:由于SynthVLM完全基于生成的图像和描述,不依赖任何真实图像数据,因而避免了隐私和安全风险。通过生成合成数据,模型可以满足隐私合规的要求,同时在模型训练过程中不会牺牲数据质量。
- 资源效率
:SynthVLM采用高效的筛选机制,在减少了80%以上的数据资源消耗的情况下,依然保持了高性能,证明了其数据生成与选择策略的有效性。这使得该方法特别适合需要高效计算和大规模数据的应用场景。
- 未来展望
:作者认为SynthVLM的成功应用为多模态大语言模型的训练和数据管理开辟了新的路径。未来的研究可以探索如何进一步优化合成数据的生成策略、提升数据对齐的准确性,并将该方法扩展到更多的多模态任务中。
总结而言,SynthVLM在VLLM训练中通过生成高质量、隐私友好的图文对数据,为视觉语言模型的发展提供了一种高效且创新的解决方案。其优异的实验结果和广泛的应用潜力使其在未来的多模态研究中具有重要的借鉴意义。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![预训练代理和世界模型的缩放定律[SCALING LAWS FOR PRE-TRAINING AGENTS AND WORLD MODELS]-AI论文](https://assh83.com/wp-content/uploads/2024/11/16-Table6-1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)