1. 引言(Introduction)
在引言部分,作者指出当前大型语言模型(LLMs)展现出显著的自然语言处理能力,广泛应用于语言生成、理解和推理等任务中。然而,当面对复杂任务时,这些模型仍然难以提供准确答案。现有的一些研究尝试通过集成方法(如多模型合作框架)来提升模型性能。例如,LLM-Debate方法将多个LLM设定为“辩论”模式,以改进推理准确性。类似地,CoT-SC方法生成多条“思维链”,并选出最具自洽性的答案。然而,这些方法普遍复杂且依赖设计特定的交互机制,无法保证在所有情境下的广泛适用性。
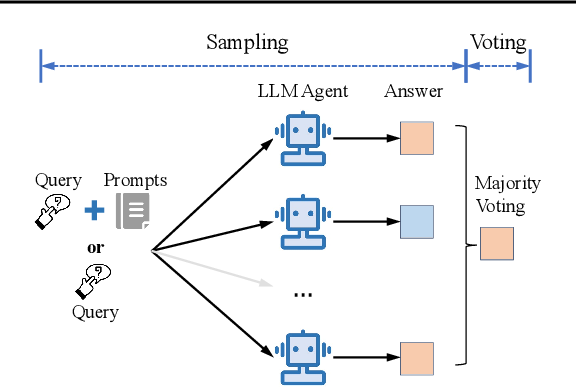
基于此背景,作者提出了一个简单却有效的方法——Agent Forest,该方法通过采样和投票机制实现性能提升。具体来说,作者使用多个语言模型代理(agents)并通过多数投票来决定最终答案,从而改善模型在多种任务中的表现。实验显示,该方法在多种任务上均显著提升了模型的准确性,并且即使简单堆叠多个小模型的效果也能接近或超过大模型的表现。这一方法不仅操作简单,还可作为现有方法的插件进一步提升效果。

此外,作者分析了Agent Forest方法在复杂任务上的优势,指出在解决难度较高的任务时,相比于简单任务,该方法的提升效果更为显著。为此,作者从任务的难度维度上展开了进一步的实验,以探讨该方法在不同任务复杂性下的表现。
2. 相关工作(Related Work)
在相关工作部分,作者将现有研究分为三个主要类别,并简要概述了每个类别中的典型方法:
- LLM自集成(LLM Self-Ensemble)
这一类别研究如何通过一个模型生成多个输出,并通过集成方法得出最终答案。CoT-SC(Chain-of-Thought Self-Consistency)是代表性方法之一,基于多条思维链生成不同推理过程,并通过多数投票选择最终答案。类似地,其他方法如Fu等人(2023)、Li等人(2023)等也扩展了这一思想,集中在推理任务上。与这些方法不同,本文的Agent Forest不仅在推理任务上有效,在生成任务上同样表现良好,同时兼容多种现有方法,如提示词工程和多代理协作。
- 异构LLM集成(Heterogeneous LLM Ensemble)
该类别研究如何通过组合不同类型的LLM模型来提升性能。Wan等人(2024)提出了一种监督的LLM融合框架,能够将多个异构模型集成成单一模型,从而超越单一模型的性能。Jiang等人(2023)提出了类似的框架,但更专注于不同知识领域模型的集成。相比之下,本文的方法无需监督学习或特定的训练数据,且适用范围更广泛。
- 多LLM代理协作(Multiple LLM Agents Collaboration)
该类别研究通过多个模型代理的交互来提升性能。Du等人(2023)、Liang等人(2023)等提出了多代理交互架构,比如静态的“辩论”模式和动态的多轮交互。与之不同,本文更关注于代理数量和性能之间的关系,而非代理交互结构本身。实验结果表明,本文方法可以与这些方法组合使用,进一步增强性能。
综上,作者指出现有方法大多关注复杂交互架构和设计特定的协作框架,然而其通用性有限。本文提出的Agent Forest则在实现简单的同时,能够兼容和提升现有复杂方法的效果。
3. 方法(Method)
在这一部分,作者详细介绍了提出的Agent Forest方法的实现过程。Agent Forest的核心在于通过“采样”和“投票”两个阶段,实现多个语言模型代理的协同,从而得到更高准确度的最终答案。

3.1 方法概述
Agent Forest的方法可以简单分为两个阶段:
- 采样(Sampling):将任务的输入多次输入到一个单一的语言模型或多语言模型的协作框架中,每次生成一个样本答案。
- 投票(Voting):将生成的多个样本答案进行多数投票,选择得票最多的答案作为最终输出。
这一流程类似于经典的“随机森林”(Random Forest),但在这里应用于语言模型代理的集合,因而称为“Agent Forest”。
3.2 采样(Sampling)
采样阶段的具体步骤如下:
- 设定输入任务的查询为x,并设定一个语言模型M。
- 生成N个样本,即通过调用语言模型M对同一输入x进行多次查询,每次返回一个不同的输出样本。每个样本记为s_i = M(x)。
- 将所有生成的样本集合记为S = {s1, s2, …, sN}。
在此阶段,采样可以依赖于单一的模型M或结合现有的其他方法(如提示词工程或多代理协作框架)来生成样本。这意味着,Agent Forest不仅适用于简单的任务,还可以通过整合多种方法来应对更复杂的任务。
3.3 投票(Voting)
投票阶段用于从采样阶段生成的样本中挑选出最佳答案,具体流程如下:
- 初始化相似性分数:对于每个样本,初始化一个相似性分数V(si) = 0,用于记录该样本与其他样本的相似性累计分数。
- 计算相似性:对于每对样本si和sj,若i ≠ j,则计算它们之间的相似性sim(si, sj),并将其加到相应的相似性分数中,即V(si) += sim(si, sj)。
- 选择最终答案:计算所有样本的相似性分数后,选择相似性分数最高的样本作为最终答案,即A = arg max V(si)。
在具体任务中的应用中,相似性度量的方式会有所不同:
- 开放式生成任务(如代码生成):使用BLEU分数来量化生成样本的相似性。
- 封闭式任务(如多项选择题):通过计算样本出现的频率来评估相似性。
通过这种投票方式,Agent Forest能够从多个样本中选出最具代表性的答案,确保结果的准确性和一致性。
3.4 Agent Forest算法
作者在论文中提供了Agent Forest算法的伪代码,总结了以上步骤:
- 初始化一个空集合S用于存放采样结果。
- 对于每个样本进行采样,生成并存储到集合中。
- 对集合中的每个样本计算其相似性得分,基于与其他样本的相似性进行累计。
- 返回相似性得分最高的样本作为最终答案。
这一算法的优势在于其简单性与扩展性:Agent Forest可以在无需设计复杂框架的前提下,轻松实现多个模型的协作。
4. 实验设置(Experimental Setup)
在这一部分,作者详细描述了实验的设置,包括实验所覆盖的任务、采用的语言模型、以及与Agent Forest结合使用的方法。通过这些设置,作者希望全面评估Agent Forest方法在多种任务中的表现、适用性及与现有方法的兼容性。

4.1 任务(Tasks)
作者选择了以下三类任务来评估Agent Forest方法:
- 算术推理(Arithmetic Reasoning)
此类任务主要用于测试模型在数学推理方面的能力。作者选择了GSM8K和MATH数据集进行评估。GSM8K是一个包含简单数学问题的数据集,而MATH数据集则包含更复杂的数学题目,测试模型在高难度数学问题上的表现。
- 通用推理(General Reasoning)
这一任务用于测试模型在一般推理任务上的表现,选用的数据集包括MMLU(大量任务理解)和国际象棋状态跟踪任务(Chess)。MMLU数据集包含广泛的推理任务,而Chess任务则要求模型根据棋局状态进行推理。
- 代码生成(Code Generation)
此类任务用于测试模型在生成代码方面的能力,采用了HumanEval数据集。在HumanEval中,模型需要根据任务生成Python代码,评估其在代码生成任务中的准确性。
4.2 采用的语言模型(Language Models Adopted)
在实验中,作者选择了多个不同规模的语言模型,以验证Agent Forest方法的适用性。所选模型包括:
- Llama2
使用Llama2的两种不同模型规模(13B和70B参数),这两个模型经过对话任务优化,适用于生成和推理任务。
- GPT系列
使用了GPT-3.5-Turbo和GPT-4两个模型进行评估。GPT-3.5-Turbo和GPT-4是OpenAI提供的强大模型,具有较强的生成和推理能力。
通过在这些不同规模的模型上进行测试,作者可以评估Agent Forest方法在模型规模不同的情况下是否具有通用性和适用性。
4.3 与Agent Forest结合使用的方法(Methods Enhanced by Agent Forest)
为了评估Agent Forest方法的兼容性,作者将其与两类方法进行组合:
- 提示词工程(Prompt Engineering)
为了进行全面实验,作者选择了多种提示词工程方法:
这些方法在实验中首先通过单次模型查询生成结果,然后通过增加查询次数和多数投票来选择最一致的答案,最终将结果与Agent Forest方法结合以观察性能提升情况。
- 多LLM代理协作(Multiple LLM Agents Collaboration)
选择了两种多代理协作方法:
在这些方法中,作者通过多次迭代操作生成多个样本,并使用多数投票产生最终答案。通过这些组合实验,作者可以测试Agent Forest方法与现有复杂方法结合使用时的兼容性和提升效果。
4.4 实验设置的细节(Experimental Setup Details)
为了最大化模型性能,实验结果取自10次独立运行的平均值。在每次运行中,代理集的规模会增加至40,以确保实现最大增益。然而,当与LLM-Debate方法结合时,由于其通信架构带来了显著的计算开销,集成规模被限制为10。附录A中提供了详细的实验设置信息。
通过上述实验设置,作者的实验设计覆盖了多种任务、模型规模和方法组合,使得Agent Forest方法的适用性、通用性和扩展性在多方面得以充分验证。
5. 实验结果(Experimental Results)
在这一部分中,作者展示了Agent Forest方法在多种任务上的实验结果,旨在验证其通用性、兼容性及在不同任务复杂度下的效果。实验结果表明,Agent Forest能够在多种任务和模型规模下显著提升模型性能,且能够与现有方法相结合进一步增强效果。

5.1 通用性(Generalizability)
实验结果(表2和图3)表明,Agent Forest方法在增加代理集规模时能有效提升模型的表现。在不同任务中,准确率的提升如下:

- 算术推理任务:在GSM8K数据集上的准确率提升了12%-24%,在MATH数据集上的准确率提升了6%-10%。
- 通用推理任务:在国际象棋状态追踪任务(Chess)上的准确率提升了1%-4%,在MMLU数据集上的准确率提升了5%-11%。
- 代码生成任务:在HumanEval数据集上的准确率提升了4%-9%。

实验结果还显示,简单地增加较小LLM的代理数量可以让它们的表现达到或超过较大模型。例如,增强后的Llama2-13B模型在GSM8K数据集上达到了59%的准确率,超过了Llama2-70B模型的54%。附录B.2提供了更多统计结果。

5.2 兼容性(Compatibility)
实验结果(表3)表明,将Agent Forest与其他方法结合使用时,可以进一步提升模型在各项任务中的表现,即使这些方法的实现机制不同。在不同任务上的组合效果如下:
- 算术推理任务:Agent Forest在GSM8K数据集上提升了10%-21%,在MATH数据集上提升了1%-15%。
- 通用推理任务:在国际象棋状态追踪任务上,组合方法的准确率提升了1%-13%,在MMLU数据集上提升了1%-11%。
- 代码生成任务:在代码生成任务中,与其他方法结合后,准确率提升了2%-7%。
然而,在使用Llama2-13B和Llama2-70B模型时,与Debate方法结合的结果出现了性能下降。这种下降主要是由于辩论过程中生成的噪声干扰了代码逻辑的连贯性,导致了性能退化。所有的准确率曲线展示在附录B.1中。
5.3 有效性(Effectiveness)
从表3的独立实验结果中可以看出,Agent Forest在大多数情况下优于其他独立使用的方法,除了在Llama2-13B和Llama2-70B模型上的国际象棋任务。此外,作者根据表3的数据计算了每种增强方法在不同任务中的平均性能排名(见表4)。结果显示,即便没有附加的提示或复杂的协作框架,Agent Forest在不同模型和任务中都获得了最高的平均排名。

5.4 鲁棒性(Robustness)
作者通过消融实验评估了不同超参数变化对最终性能的影响。实验中,作者分别调整了温度参数(temperature, T)和nucleus概率(p),并在20次独立运行中使用GPT-3.5-Turbo模型进行测试。图4显示,不同超参数设置下,增大代理数量能够稳定提升LLM的性能,这表明Agent Forest方法在不同参数配置下具备良好的鲁棒性。
5.5 Token使用量(Token Usage)
在实验中,作者记录了每种方法的token使用量,单个代理的token使用量在表5中展示。由于Agent Forest通过增加代理数量来提升性能,token使用量会随着代理数量的增大而增加。当需要在特定任务中提升性能时,可以通过更高的token预算来换取更好的性能表现。附录B.3中提供了更多关于token使用量的细节。
综上,实验结果表明,Agent Forest方法在多个任务和模型上均能显著提升性能,且具备较好的兼容性和鲁棒性。此外,该方法在应对复杂任务时效果尤为显著,并且能够与现有方法结合,以进一步增强性能。
6. 理解性能提升(Understanding the Performance Gains)
在本部分中,作者深入分析了Agent Forest方法的性能提升原因,并通过一系列实验研究了任务难度对该方法有效性的影响。研究表明,Agent Forest在任务难度较高的情况下具有更显著的性能增益。作者通过控制实验进一步探讨了任务难度的三维度:内在难度、推理步骤数量、正确答案的先验概率,并总结了每个维度下的性能表现。

6.1 性能增益概述
根据表2的数据,作者发现Agent Forest方法的有效性随任务难度的增加而增强。在GSM8K(简单任务)和MATH(复杂任务)这两个数据集上,较小的Llama2-13B模型在任务难度较高的情况下,其相对性能提升达到了28%-200%,而在较大的GPT-3.5-Turbo模型上,性能提升幅度相对较小(8%-16%)。特别是在MATH数据集(高难度任务)上,增益达到34%-200%,而在GSM8K(低难度任务)上增益仅为16%-69%。
6.2 三个任务难度维度
为了更好地理解任务难度对Agent Forest性能的影响,作者将任务难度分为以下三个独立的维度:
- 内在难度(Inherent Difficulty):任务本身的难易程度。
- 推理步骤数量(Number of Reasoning Steps):解决任务所需的步骤数量。
- 正确答案的先验概率(Prior Probability of the Correct Answer):正确答案出现的概率。

为了更好地探讨这些维度的影响,作者设计了一个数学任务,分别隔离这三个维度,以便单独研究每个维度对性能提升的影响。
6.3 内在难度(Inherent Difficulty)
性质1:性能增益随着内在难度的上升先增加后下降。
通过调节参数I的数值(从10到400),来模拟任务的内在难度。实验结果(图6左)表明,在内在难度较小时,Agent Forest的性能增益随难度上升而增加,但在极端困难的任务(例如I = 400)中,性能增益开始下降。这表明过高的复杂性可能会超出模型的推理能力,从而导致效果的边际收益递减。

6.4 推理步骤数量(Number of Steps)
性质2.1:性能增益随着推理步骤的增加而提升。
在实验中,作者通过调节步骤数量S(从1到8)来研究推理步骤数量的影响。图6中间部分显示,随着步骤数量的增加,Agent Forest的性能增益逐渐增加。此外,作者发现,当增加内在难度(I)和先验概率(K)时,性能增益更加显著。例如,在I = 10和K = 2的情况下增益为4%-18%,而在I = 100和K = 4的情况下增益则增加到16%-48%。
性质2.2:Agent Forest在每个推理步骤上均有提升。
在对每个步骤的细化分析中,作者发现尽管每个步骤的内在难度相同,但前一步骤的累积误差会导致准确率随着步骤增加而下降。然而,Agent Forest方法可以有效缓解随着步骤增加而出现的性能下降问题。基于此性质,作者提出了一种“分步Agent Forest(Step-wise Agent Forest)”方法,在每个推理步骤上使用Agent Forest进一步提升整体性能。
6.5 正确答案的先验概率(Prior Probability)
性质3:性能随着正确答案先验概率的增加而提升。
为了研究先验概率的影响,作者调节参数K(从4到32),调整正确答案的先验概率(1/K)。图6右部分显示,随着先验概率的增大,Agent Forest的性能不断提升。在不同的实验组中(不同的I和S值组合),均显示了先验概率对性能的积极影响。
基于这一性质,作者提出了一种“分层Agent Forest(Hierarchical Agent Forest)”方法,通过将低概率任务分解为多个高概率子任务分层处理,以进一步提升性能。实验表明,采用分层Agent Forest方法能够在成本效益上优化模型的性能。
6.6 进一步优化方法
基于上述性质,作者提出了两种优化方法:
- 分步Agent Forest(Step-wise Agent Forest)
将任务分解为多个步骤,在每一步上使用Agent Forest生成答案,并在多轮迭代中逐步处理每一步的推理任务。实验显示,分步Agent Forest相比标准Agent Forest方法可以在更高难度的任务中获得显著的额外增益,例如在I = 100到I = 400范围内增益达15%-42%。
- 分层Agent Forest(Hierarchical Agent Forest)
基于先验概率的特性,通过将低概率任务分解为多个高概率子任务并分层处理,不同子任务可使用不同的模型完成,从而提高性能。例如,在GPT-3.5-Turbo与GPT-4的异构组合实验中,相比直接使用GPT-4,分层Agent Forest将性能从35%提升至47%,证明在保持高效性的前提下能显著提升性能。
综上,作者通过任务难度的多维度分析,深入理解了Agent Forest方法在不同复杂性任务中的性能提升机制,并提出了两种进一步优化的变体方法,使得Agent Forest在应对复杂任务时具备更强的鲁棒性和效率。
7. 结论与未来工作(Conclusions and Future Work)
在结论与未来工作部分,作者总结了本文的主要贡献,强调了Agent Forest方法的有效性,并提出了未来的研究方向。
7.1 主要结论
作者在本文中首次系统性地研究了通过增加语言模型代理数量来提升模型性能的“扩展规律”(scaling law),并得出以下主要结论:
- 通过增加代理数量即可提高性能
通过简单地增加LLM代理的数量,可以在处理复杂任务时显著提升模型性能,而不需要设计复杂的提示链或多代理协作框架。Agent Forest方法提供了一种简单而有效的解决方案,即使是通过最基本的采样和投票机制也能显著提升准确性。
- 方法的通用性与兼容性
实验结果显示,Agent Forest方法对不同任务和模型规模具有通用性,并且可以与现有的复杂方法(如提示词工程、多代理协作框架等)相结合,进一步提升性能。无论是简单任务还是复杂任务,Agent Forest在多个任务上的表现都验证了其有效性。
- 任务难度与性能增益之间的关联
通过分析任务难度对性能增益的影响,作者发现Agent Forest在任务难度较高的情况下更为有效。作者将任务难度分为三个维度:内在难度、推理步骤数量、正确答案的先验概率,并验证了在高难度任务上,通过调整这些维度,Agent Forest可以获得更大的性能提升。这些实验结果揭示了多代理扩展在更复杂任务上更有潜力的原因。
- 基于性能提升特性的进一步优化
在对性能提升原因进行深入研究的基础上,作者提出了两种优化方法——分步Agent Forest和分层Agent Forest。这两种方法能够在复杂任务中更好地利用多代理系统的优势,进一步提升模型的准确性和鲁棒性,且成本效益更高。
7.2 未来工作
尽管Agent Forest方法在提升性能方面表现出色,但仍存在一些挑战,作者在此提出了未来可能的研究方向:
- 优化采样阶段以减少成本
在当前实验中,Agent Forest方法需要大量的LLM调用,随着代理数量的增加,计算成本也显著提升。未来的研究可以优化采样过程,通过减少重复采样和利用高效采样策略来降低成本。尽管多次调用LLM带来的高成本在现有研究中并不罕见(例如Wang等人,2023;Du等人,2023),但这种成本的上升仍然是应用多代理方法的挑战之一。
- 改进代理的实际效率
当前基准测试中,过于关注准确性往往导致代理在实际应用中效率较低,这一点与Kapoor等人(2024)所提出的观察一致。代理的实际效率可以通过增加有效的保留数据集、标准化评价方法等方式来提高,从而提升Agent Forest在真实世界场景中的效率。
- 在更多任务与场景中的验证
尽管Agent Forest已经展示了良好的通用性,但未来研究可以进一步测试其在更广泛任务和场景中的表现,例如更多的实际应用任务、不同语言任务、以及高交互性任务。这将有助于确认Agent Forest的广泛适用性。
- 与其他复杂协作框架的进一步集成
在本文中,Agent Forest展示了其与其他方法的兼容性,但未来可以进一步探索它与更多复杂协作框架的组合方式,从而在保留其简单性的基础上获得更大性能提升。这可能涉及到探索与其他先进的推理机制或协作系统的融合,以实现更高效的多代理协作。
总之,Agent Forest方法不仅简单高效,而且适用于多种复杂任务和模型,展现出广泛的应用前景。作者相信,随着采样过程的进一步优化和实际效率的提高,Agent Forest方法将能够在更多实际应用中发挥重要作用,为未来多代理系统的研究提供了坚实的基础。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![SynthVLM: High-Efficiency and High-Quality Synthetic Data forVision Language Models[视觉语言模型的高效高质量合成数据]-AI论文](https://assh83.com/wp-content/uploads/2024/11/4-Figure3-1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)