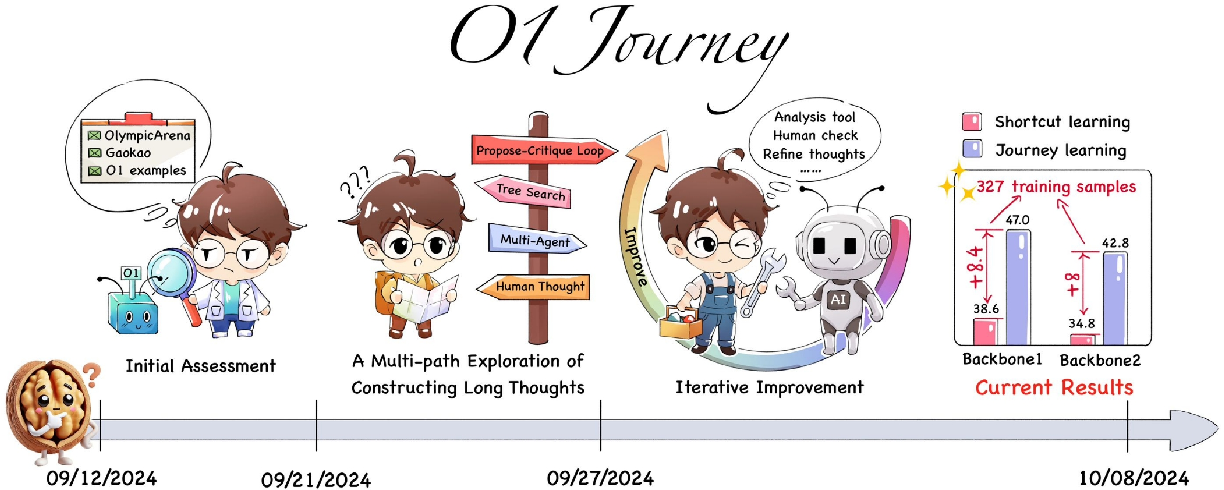
1. Chronological Overview of the O1 Exploration Journey(O1探索之旅的时间线概述)
在“O1探索之旅的时间线概述”这一部分,论文详细描述了研究团队从OpenAI发布O1模型后,到2024年10月期间,对O1技术的探索历程。以下是对该部分的详细解读:

一、研究背景与起始
- OpenAI宣布了O1模型,这是一个据称具有复杂推理能力的突破性语言模型。
- 尽管O1的发布引起了广泛的兴奋和关注,但AI社区却处于一个尴尬的境地:他们知道O1的存在和宣称的能力,但关于其实现细节、训练数据,甚至完整的输出都笼罩在神秘之中。
- 这种缺乏透明度不仅阻碍了技术进步,还引发了关于AI领域科学进步开放性的重要问题。
二、研究团队的探索旅程
- 初始评估与知识获取
- 团队组建与分析
- 长期思考构建尝试
- 训练管道与迭代优化
三、研究成就与未来方向
- 通过这一系列的研究活动,研究团队取得了一些重要的成就,包括提出了“旅程学习”范式等。
- “旅程学习”鼓励模型不仅学习解决问题的捷径,还学习完整的探索过程,包括试错、反思和回溯。
- 此外,研究团队还展望了未来的研究方向,包括继续深入探索O1的工作原理、提高模型的性能以及推动AI研究的开放性和协作性。
四、研究时间线与可视化
- 论文提供了一个详细的时间线图表(Figure 2),该图表概述了从O1发布到2024年10月期间的研究旅程。
- 时间线图表以时间顺序跟踪了研究活动的进展,并在主图中垂直显示了这些活动。
- 图表右侧还展示了训练管道,包括预训练、迭代训练和优化技术的各个阶段。

综上所述,“O1探索之旅的时间线概述”部分详细描述了研究团队对O1技术的探索历程,从初步评估到团队组建,再到长期思考构建尝试和训练管道的迭代优化,最后展望了未来的研究方向。这一部分的解读有助于我们更好地理解研究团队的工作流程和研究重点。

2. Why We Created a Progress Report(我们为何创建进度报告)
在论文的第二部分,作者们详细阐述了他们为何决定创建一个进度报告来记录并分享他们复制OpenAI的O1技术过程中的所有细节,包括成功与失败。这一决策背后有多重深刻的原因,下面将逐一进行详细解读。
2.1 Addressing the Challenges of Modern AI Research(解决现代AI研究的挑战)
- 背景:现代人工智能研究的快速发展带来了全新的研究范式,以长期、基于团队的项目为特点,这些项目经常持续六个月或更长时间。
- 挑战:
- 信息隔阂:长期团队合作的固有封闭性往往导致信息流向更广泛的科学界的速度减慢。
- 研究者倦怠:项目的长期性质经常导致研究者的延迟满足,可能在整个研究过程中产生焦虑和动力下降。
- 贡献识别困难:大型团队项目的复杂性使得个体贡献的识别变得复杂,可能侵蚀了传统的学术激励结构。
- 解决方案:进度报告方法旨在通过增强透明度、促进实时反馈和认可,以及鼓励对长期研究倡议的持续承诺来解决这些新兴挑战。
2.2 Fostering Open Science and Collective Advancement(促进开放科学和集体进步)
- 目标:本报告的主要推动力之一是传播从复制O1模型这一努力中获得的宝贵见解、资源和教训。
- 内容:报告不仅分享了训练好的模型,还全面记录了在整个探索过程中使用的工具、数据集和方法论。
- 教育价值:通过坦诚地分享挫折和失败的尝试,报告提供了通常超越成功故事的教育价值。这种透明度旨在帮助其他研究者避开潜在的陷阱,从而加速整个领域的进步。
- 创新催化:通过阐明思想过程和创新方法,作者们旨在激发社区内的创造力,促进新颖想法和方法论的生成。
2.3 Laying the Foundation for AI in Scientific Discovery(为AI在科学发现中奠定基础)
- 重要性:详细记录科学探索过程具有深远意义,特别是在人工智能能力快速发展的背景下。
- 数据集价值:通过记录整个探索过程,包括成功和失败,作者们正在培养一个独特且宝贵的数据集。
- 科学方法理解:O1模型的成功强调了AI系统学习科学方法论完整过程(包括试错)的重要性。报告不仅捕捉技术细节,还包括决策理由、灵感来源和思想过程,这些“人为因素”对于训练能够进行真正科学发现的AI模型至关重要。
- 跨学科价值:该方法具有跨学科价值,为研究文档和知识共享提供了一个模板,可以促进各科学领域的创新。
2.4 Promoting Responsible AI Development(促进负责任的AI开发)
- 社会责任:在追求技术突破时,作者们始终意识到AI开发可能带来的社会影响和伦理考虑。
- 透明度标准:通过详细记录研究过程和决策制定,作者们建立了一个高标准的透明度,这对于培养公众对AI研究的信任至关重要。
- 伦理整合:报告超越了技术细节,纳入了对潜在社会影响的持续讨论和反思,从而在整个技术开发过程中展示了伦理考虑的整合。
- 文化培育:这种全面方法有助于培养一个更加负责任和注重伦理的AI研究文化。
综上所述,作者们创建进度报告的决策是基于对现代AI研究挑战的深刻认识,以及对促进开放科学、为AI在科学发现中奠定基础,以及促进负责任AI开发的强烈愿望。通过详细记录并分享他们的探索过程,作者们旨在为AI研究和科学探索领域带来一种全新的范式。
3. Journey Learning: A New Paradigm Shift from “Shortcut Learning”(旅程学习:从“捷径学习”到新的范式转变)
一、背景与动机
在传统的机器学习,特别是大型语言模型的训练中,一种被广泛采用的方法是“捷径学习”(Shortcut Learning)。这种方法侧重于快速达到特定的性能指标或完成特定任务,通常依赖于大量的训练数据和相对简单的算法调整。然而,随着AI技术的不断发展,研究者们逐渐意识到“捷径学习”在面临复杂、动态和开放式问题时存在显著局限性。
具体来说,“捷径学习”往往只能捕捉到表面的特征和简单的相关性,而无法深入理解深层的因果关系和基本原理。此外,这种方法还可能导致模型缺乏自我修正机制,难以识别并纠正自身的错误。在推理能力方面,“捷径学习”也表现有限,特别是在处理复杂推理任务时。
二、旅程学习的提出
为了克服“捷径学习”的局限性,研究者们提出了一种新的范式——“旅程学习”(Journey Learning)。这种范式不仅关注学习结果,更重视整个学习和探索过程,包括试错、反思和回溯等步骤。
“旅程学习”鼓励模型像人类一样解决问题,即不仅要知道正确答案,还要理解为什么和如何得出这个答案。通过经历正确和错误的路径,模型能够发展出强大的错误处理和自我修正能力,从而增强对新挑战的适应性。
三、旅程学习的特点与优势
- 学习深度:与“捷径学习”相比,“旅程学习”更深入地探索了深层的因果关系和基本原理。
- 推理能力:它展示了强大的推理能力,能够像人类一样进行复杂推理。
- 自我改进:“旅程学习”模型具备连续自我评估和改进的能力,这是“捷径学习”所缺乏的。
- 创新容量:在面对新问题时,“旅程学习”模型能够生成创新的解决方案,而“捷径学习”则往往挣扎于解决新问题。
- 数据依赖性:“旅程学习”更侧重于数据的质量和学习策略,而不是简单地依赖大量的训练数据。
- 可解释性:“旅程学习”模型能够更好地追踪内部推理过程,从而提高了模型的可解释性。
四、实验结果与验证
论文中通过一系列实验验证了“旅程学习”的有效性。例如,在MATH数据集上,仅使用327个训练样本,“旅程学习”就超越了传统的监督学习,性能提升了超过8%。这一结果表明,“旅程学习”具有极其强大的潜力。
此外,研究者们还指出,“旅程学习”不仅代表了学习方法的革新,更是AI发展范式的转变。它旨在创建能够适应复杂现实世界挑战、具备推理能力和自我改进能力的AI系统。
五、结论与展望
随着“旅程学习”范式的不断发展和完善,我们期待它将在AI研究领域开辟新的可能性。未来的实验将进一步探索偏好学习和强化学习等技术,以进一步提高“旅程学习”模型的性能和应用范围。
综上所述,“旅程学习”作为一种新的范式转变,为AI技术的发展提供了新的思路和方向。通过重视整个学习和探索过程,而不是仅仅追求快速结果和大量数据依赖,“旅程学习”有望推动AI向更加智能、可靠和可解释的方向发展。
4. Exploration Journey(探索之旅)
在论文的“探索之旅”部分,作者们详细描述了他们在实现O1技术过程中的一系列尝试、迭代和深入探索。这部分内容不仅展示了技术实现的复杂性,还体现了“旅程学习”范式的核心价值。

4.1 旅程学习的提出与背景
作者们首先指出,传统的机器学习方法,如监督微调等,可以被视为“捷径学习”。这种范式在特定、定义明确的任务中可能有效,但存在显著局限性。例如,性能提升往往依赖于增加训练数据量,而非改进学习算法本身;在训练数据分布之外的场景中,性能会急剧下降;且这些系统通常缺乏自我纠正能力。
为了克服这些局限性,作者们提出了“旅程学习”这一新的范式。旅程学习旨在探索整个探索路径的监督学习,包括试错和纠正过程。它旨在创建不仅限于狭窄、特定任务的AI系统,而是能够适应、推理的实体,能够处理现实世界挑战的细微差别和复杂性。
4.2 探索之旅的详细描述
在探索之旅中,作者们进行了多次尝试和迭代,以深入理解O1技术的本质。他们描述了几个关键阶段:
- 初步尝试与观察:
- 数据准备与精细调整:
- 性能评估与比较:
- 遇到的挑战与未来方向:
4.3 探索之旅的意义与价值
探索之旅不仅展示了O1技术的实现过程,还体现了“旅程学习”范式的核心价值。通过深入探索未知领域,作者们不仅获得了宝贵的技术见解,还推动了AI技术的范式转变。这种转变有望带来更加能干、适应性强、类人化的AI系统,这些系统能够更好地服务于人类并在各个领域与人类互动。

此外,探索之旅还强调了整个学习和探索过程的重要性。作者们通过记录并分享他们的尝试、迭代和发现,为其他研究人员提供了宝贵的参考和启示。这种开放和透明的态度有助于促进AI领域的合作与交流,共同推动技术的进步与发展。
5. Detailed Event Explanation of Our Research Exploration(研究探索的详细事件解释)
在论文的“研究探索的详细事件解释”部分,作者们提供了对他们在O1复制尝试中所经历的各个关键节点和事件的深入剖析。这一章节是对整个研究过程的详细记录,旨在通过具体的事件和实例来展示他们的研究方法、思路转变、遇到的挑战以及解决方案。以下是对该部分的详细解读:
1. 研究节点概述
作者们首先列出了一系列的研究节点,每个节点都附带了简短的描述和解释资源。这些节点构成了他们研究探索的框架,反映了从初步评价到深入探索、再到最终解决方案的完整过程。
2. 节点详细描述与解释
- 节点1至节点17:每个节点都详细记录了研究过程中的一个关键事件或决策点。这些事件可能包括尝试不同的方法、遇到的技术难题、思路的转变、解决方案的实施等。
- 解释资源:对于每个节点,作者们都提供了相应的解释资源,如参考文献、实验数据、模型输出等,以便读者能够更深入地理解该节点所描述的事件或决策。
3. 研究方法与技术
在详细事件解释中,作者们还展示了他们所采用的研究方法和技术。这包括:
- “旅程学习”范式:鼓励模型不仅学习捷径,而是学习完整的探索过程,包括试错、反思和回溯。这种方法旨在培养模型对问题的深入理解,而不仅仅是找到快速解决问题的方案。
- 推理树的构建与集成:在构建长思维(Long Thought)的过程中,作者们采用了推理树的方法,通过构建包含多个推理步骤的树形结构来模拟人类的思维过程。他们还讨论了如何将推理树集成到长思维中,以实现更复杂的推理能力。
- 奖励模型的构建:为了评估每个推理步骤的正确性,作者们构建了奖励模型。这些模型能够基于模型的输出提供反馈,从而帮助模型在训练过程中不断改进。
4. 遇到的挑战与解决方案
在详细事件解释中,作者们也坦诚地分享了他们在研究过程中遇到的挑战以及解决方案。这些挑战可能包括:
- 技术难题:如如何构建有效的推理树、如何确保奖励模型的准确性等。
- 数据稀缺性:在有限的数据样本下实现模型的有效训练和优化。
- 思维模式的转变:从传统的“捷径学习”转向“旅程学习”,需要改变研究思路和方法。
针对这些挑战,作者们提出了相应的解决方案,如采用更精细的奖励模型、利用迁移学习等方法来弥补数据不足、通过迭代和试错来不断优化模型等。
5. 对未来研究的启示
最后,在详细事件解释中,作者们也展望了他们的研究对未来AI研究的启示。他们强调了“旅程学习”范式在培养模型对问题的深入理解方面的优势,并认为这种方法在未来AI研究中具有广泛的应用前景。同时,他们也提出了未来研究的一些潜在方向,如进一步改进奖励模型、探索更复杂的推理结构等。
综上所述,“研究探索的详细事件解释”部分为读者提供了对作者们在O1复制尝试中所经历的各个关键节点和事件的深入剖析。通过这一部分的解读,读者可以更加深入地理解作者的研究方法、思路转变、遇到的挑战以及解决方案,并对未来AI研究的发展方向有更清晰的认识。
6. Future Plan(未来计划)
在论文的“未来计划”部分,作者们基于当前的研究成果和遇到的挑战,提出了多个关键领域的未来探索和发展方向。以下是对这些未来计划的详细解读:
1. 扩大长期思维整合(Scaling Up Long Thought Integration)
作者们计划继续优化并扩展长期思维整合技术,这是在之前的迭代中已经取得成功的领域。通过不断提升长期思维整合的能力,AI系统可以更有效地处理复杂的问题和推理任务。
2. 长期思维扩展定律实验(Experiments on Long Thought Scaling Laws)
为了更深入地理解长期思维的能力,作者们计划进行一系列实验,探索长期思维扩展的定律。这些实验将有助于揭示AI系统在处理不同规模和复杂度的任务时,其长期思维能力的变化规律。
3. 精细化的思维中心评估(Fine-Grained, Thought-Centric Evaluation)
为了更准确地衡量AI系统生成的长期思维的质量和连贯性,作者们计划开发并实施更复杂的评估方法。这种方法将侧重于精细化的、以思维为中心的评估,从而提供更深入的见解,帮助理解AI系统的推理能力。
4. 人类与AI在高质量思维上的协作(Human-AI Collaboration for Quality Thought)
作者们认为,人类与AI在高质量思维上的协作将是未来发展的重要方向。通过结合人类的创造力和AI的计算能力,可以共同推动科学和技术的发展。
5. 高级推理树的整合(Advanced Integration of Reasoning Trees)
为了从复杂的推理树中导出和整合长期思维,作者们计划探索更高级的算法。这些算法将能够遍历和合成推理树中的信息,从而更有效地利用这些结构进行推理和决策。
6. 训练方法的扩展(Expansion of Training Methodologies)
作者们计划进一步实验和完善训练管道,包括预训练、迭代训练、强化学习、偏好学习和直接偏好优化(DPO)等阶段。通过不断优化训练方法,可以提高AI系统的性能和泛化能力。
7. 持续透明度和资源共享(Continued Transparency and Resource Sharing)
作为对开放科学的承诺,作者们将继续保持透明度和资源共享。他们将发布有价值的资源,包括数据集、模型架构和训练代码等,以促进AI领域的合作和进步。
8. 分析工具的精炼(Refinement of Analysis Tools)
为了更好地解释模型输出、跟踪进度和指导未来研究方向,作者们计划进一步开发和增强分析工具。这些工具将对于理解和复制O1的能力至关重要,同时也有助于推动AI研究方法的边界。
综上所述,作者们的未来计划反映了他们对旅程学习范式的承诺,强调了持续改进、透明探索和协作推进人工智能领域的发展。随着项目的推进,他们将继续适应新的发现和挑战,不断推动AI技术的创新和进步。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![AGENTGYM:在不同环境中发展基于大型语言模型的代理[Evolving Large Language Model-based Agents across Diverse Environments]-AI论文](https://assh83.com/wp-content/uploads/2024/11/3-Figure2-1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)