介绍
pip install open-interpreter不工作?阅读我们的设置指南。
interpreterOpen Interpreter 允许 LLM 在本地运行代码(Python、Javascript、Shell 等)。您可以通过安装后运行终端中类似 ChatGPT 的界面与 Open Interpreter 聊天。$ interpreter
这为计算机的通用功能提供了一个自然语言接口:
- 创建和编辑照片、视频、PDF 等。
- 控制 Chrome 浏览器执行研究
- 绘制、清理和分析大型数据集
⚠️注意:在代码运行之前,系统会要求您批准代码。
演示
快速开始
pip install open-interpreter终端
安装后,只需运行 :interpreter
interpreterpython
from interpreter import interpreter
interpreter.chat("Plot AAPL and META's normalized stock prices") # Executes a single command
interpreter.chat() # Starts an interactive chatGitHub 代码空间
按此存储库的 GitHub 页面上的键以创建 codespace。片刻之后,您将收到一个预装了 open-interpreter 的云虚拟机环境。然后,您可以直接开始与它交互并自由确认其对系统命令的执行,而不必担心损坏系统。,
与 ChatGPT 的代码解释器比较
OpenAI 发布的带有 GPT-4 的 Code Interpreter 为使用 ChatGPT 完成实际任务提供了绝佳的机会。
但是,OpenAI 的服务是托管的、闭源的,并且受到严格限制:
- 无法访问 Internet。
- 有限的预安装软件包集。
- 最大上传 100 MB,运行时限制为 120.0 秒。
- 当环境死亡时,状态将被清除(以及任何生成的文件或链接)。
Open Interpreter 通过在本地环境中运行来克服这些限制。它可以完全访问 Internet,不受时间或文件大小的限制,并且可以使用任何包或库。
它将 GPT-4 的 Code Interpreter 的强大功能与本地开发环境的灵活性相结合。
命令
更新:生成器更新 (0.1.5) 引入了流:
message = "What operating system are we on?"
for chunk in interpreter.chat(message, display=False, stream=True):
print(chunk)互动聊天
要在终端中开始交互式聊天,请从命令行运行:interpreter
或者从 .py 文件中:interpreter.chat()
您还可以流式传输每个数据块:
message = "What operating system are we on?"
for chunk in interpreter.chat(message, display=False, stream=True):
print(chunk)程序化聊天
要进行更精确的控制,您可以将消息直接传递给 :.chat(message)
interpreter.chat("Add subtitles to all videos in /videos.")
# ... Streams output to your terminal, completes task ...
interpreter.chat("These look great but can you make the subtitles bigger?")
# 开始新聊天
在 Python 中,Open Interpreter 会记住对话历史记录。如果您想重新开始,您可以重置它:
interpreter.messages = []保存和恢复聊天
interpreter.chat()返回一个 List 消息,该消息可用于恢复与 的对话:interpreter.messages = messages
messages = interpreter.chat("My name is Killian.") # Save messages to 'messages'
interpreter.messages = [] # Reset interpreter ("Killian" will be forgotten)
interpreter.messages = messages # Resume chat from 'messages' ("Killian" will be remembered)自定义系统消息
您可以检查和配置 Open Interpreter 的系统消息,以扩展其功能、修改权限或为其提供更多上下文。
interpreter.system_message += """
Run shell commands with -y so the user doesn't have to confirm them.
"""
print(interpreter.system_message)更改您的语言模型
Open Interpreter 使用 LiteLLM 连接到托管语言模型。
您可以通过设置 model 参数来更改模型:
interpreter --model gpt-3.5-turbo
interpreter --model claude-2
interpreter --model command-nightly在 Python 中,在对象上设置模型:
interpreter.llm.model = "gpt-3.5-turbo"
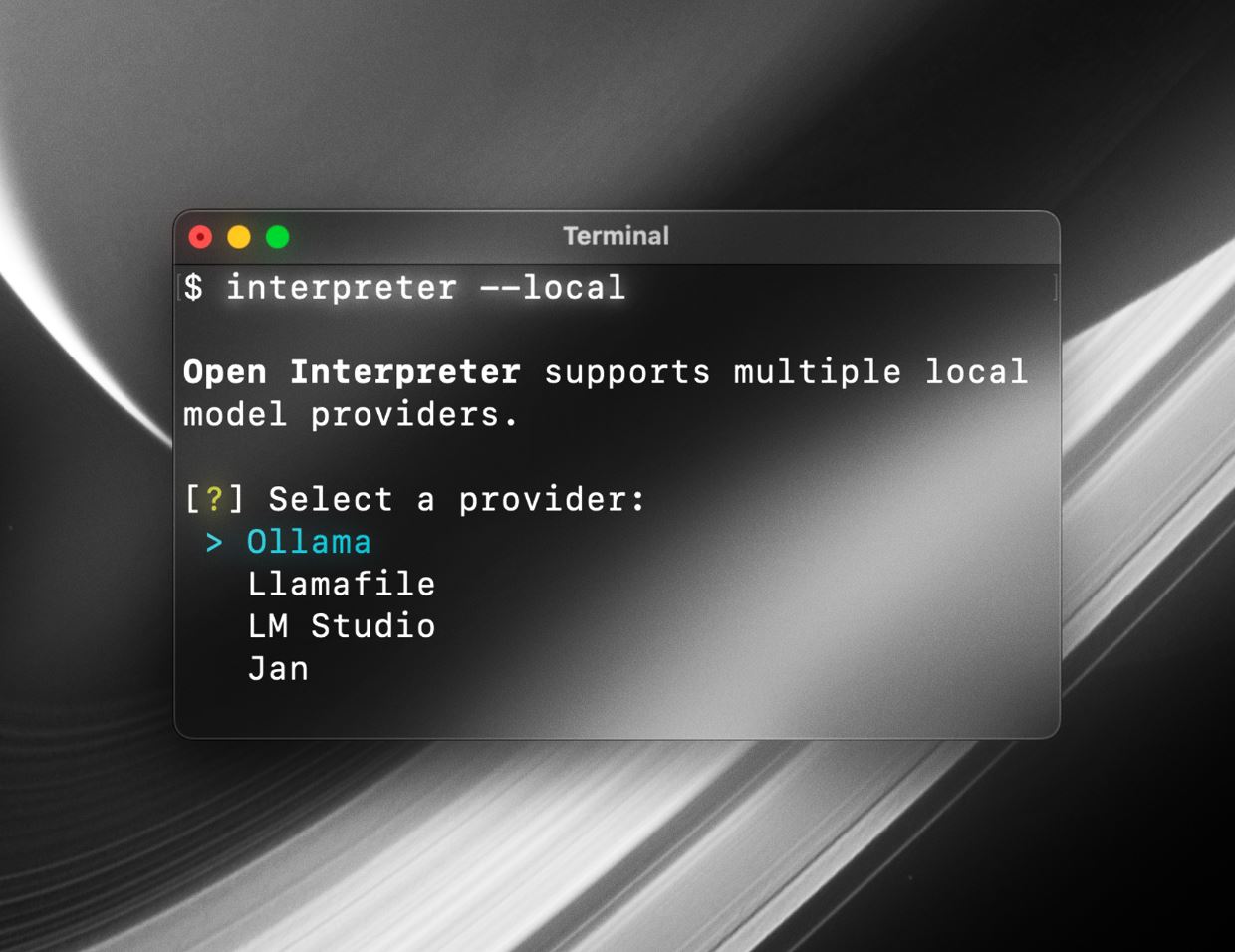
在本地运行 Open Interpreter
终端
Open Interpreter 可以使用兼容 OpenAI 的服务器在本地运行模型。(LM Studio、jan.ai、ollama 等)
只需使用推理服务器的 api_base URL 运行(对于 LM Studio,默认情况下是这样):interpreterhttp://localhost:1234/v1
interpreter --api_base "http://localhost:1234/v1" --api_key "fake_key"或者,您可以使用 Llamafile 而无需安装任何第三方软件,只需运行
interpreter --local有关更详细的指南,请查看 Mike Bird 的此视频
如何在后台运行 LM Studio。
- 下载 https://lmstudio.ai/ 然后启动它。
- 选择一个模型,然后单击 ↓ 下载。
- 单击↔️按钮(下方💬)。
- 在顶部选择您的模型,然后单击 Start Server。
服务器运行后,您可以开始与 Open Interpreter 对话。
注意:本地模式将 u 设置为 3000,将 u 设置为 1000。如果您的模型有不同的要求,请手动设置这些参数(请参阅下文)。
context_windowmax_tokens
python
我们的 Python 包让您可以更好地控制每个设置。要复制并连接到 LM Studio,请使用以下设置:
from interpreter import interpreter
interpreter.offline = True # Disables online features like Open Procedures
interpreter.llm.model = "openai/x" # Tells OI to send messages in OpenAI's format
interpreter.llm.api_key = "fake_key" # LiteLLM, which we use to talk to LM Studio, requires this
interpreter.llm.api_base = "http://localhost:1234/v1" # Point this at any OpenAI compatible server
interpreter.chat()上下文窗口 (Context Window) > 最大令牌数 (Max Tokens)
您可以修改本地运行的模型的 and(在令牌中)。max_tokenscontext_window
对于本地模式,较小的上下文窗口将使用更少的 RAM,因此我们建议尝试更短的窗口 (~1000),如果它失败/很慢。确保小于 。max_tokenscontext_window
interpreter --local --max_tokens 1000 --context_window 3000详细模式
为了帮助您检查 Open Interpreter,我们提供了一个调试模式。--verbose
你可以使用其标志 () 或在聊天中激活详细模式:interpreter --verbose
$ interpreter
...
> %verbose true <- Turns on verbose mode
> %verbose false <- Turns off verbose mode交互模式命令
在交互模式下,您可以使用以下命令来增强您的体验。以下是可用命令的列表:
可用命令:
%verbose [true/false]:切换详细模式。没有参数或有它 进入详细模式。使用它退出详细模式。truefalse%reset:重置当前会话的对话。%undo:从消息历史记录中删除以前的用户消息和 AI 的响应。%tokens [prompt]:(实验性)计算将与下一个提示作为上下文一起发送的令牌,并估算其成本。(可选)计算令牌和估计成本(如果提供)。依赖 LiteLLM 的cost_per_token()方法来估算成本。prompt%help:显示帮助消息。
配置/配置文件
Open Interpreter 允许您使用文件设置默认行为。yaml
这提供了一种灵活的方法来配置解释器,而无需每次都更改命令行参数。
运行以下命令以打开 profiles 目录:
interpreter --profiles您可以在该处添加文件。默认配置文件名为 。yamldefault.yaml
多个配置文件
Open Interpreter 支持多个文件,允许您在配置之间轻松切换:yaml
interpreter --profile my_profile.yaml示例 FastAPI 服务器
生成器更新使 Open Interpreter 可以通过 HTTP REST 端点进行控制:
# server.py
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from interpreter import interpreter
app = FastAPI()
@app.get("/chat")
def chat_endpoint(message: str):
def event_stream():
for result in interpreter.chat(message, stream=True):
yield f"data: {result}\n\n"
return StreamingResponse(event_stream(), media_type="text/event-stream")
@app.get("/history")
def history_endpoint():
return interpreter.messages
pip install fastapi uvicorn
uvicorn server:app --reload您也可以通过简单地运行 来启动与上述服务器相同的服务器。interpreter.server()
人造人
可以在 open-interpreter-termux 存储库中找到在 Android 设备上安装 Open Interpreter 的分步指南。
安全须知
由于生成的代码是在本地环境中执行的,因此它可以与您的文件和系统设置交互,这可能会导致数据丢失或安全风险等意外结果。
⚠️Open Interpreter 将在执行代码之前要求用户确认。
您可以运行 或 设置为绕过此确认,在这种情况下:interpreter -yinterpreter.auto_run = True
- 请求修改文件或系统设置的命令时要小心。
- 像看自动驾驶汽车一样观看 Open Interpreter,并准备好通过关闭终端来结束该过程。
- 考虑在 Google Colab 或 Replit 等受限环境中运行 Open Interpreter。这些环境更加隔离,从而降低了执行任意代码的风险。
对安全模式的实验性支持有助于缓解某些风险。
它是如何工作的?
Open Interpreter 为函数调用语言模型配备了一个函数,该函数接受 (如 “Python” 或 “JavaScript”) 并运行。exec()languagecode
然后,我们将模型的消息、代码和系统的输出作为 Markdown 流式传输到终端。
离线访问文档
无需 Internet 连接,即可随时随地访问完整文档。
Node 是先决条件:
- 版本 18.17.0 或更高版本 18.x.x 。
- 版本 20.3.0 或更高版本的 20.x.x 版本。
- 从 21.0.0 开始的任何版本,未指定上限。
安装 Mintlify:
npm i -g mintlify@latest切换到 docs 目录并运行相应的命令:
# Assuming you're at the project's root directory
cd ./docs
# Run the documentation server
mintlify dev应打开一个新的浏览器窗口。只要文档服务器正在运行,文档就会在 http://localhost:3000 上可用。
网址:https://docs.openinterpreter.com/getting-started/introduction




![思考快与慢的智能体:对话者-推理者架构[Agents Thinking Fast and Slow:A Talker-Reasoner Architecture]-AI论文](https://assh83.com/wp-content/uploads/2024/11/Figure-1-75x75.jpg)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)