1 引言(Introduction)
这篇论文的引言部分主要介绍了大规模语言模型(LLMs)评估模型的重要性,并提出了一种创新的自我训练评估器(Self-Taught Evaluator)方法。以下是引言的详细解读:
1.1 背景:
– 现代的大规模语言模型在开发过程的各个阶段,都高度依赖于评估模型(Evaluator)。这些评估模型在训练时作为奖励模型(reward model),用于将模型的行为与人类偏好对齐;在推理时,则替代人类进行评估,判断模型生成的响应质量。
– 当前训练评估器的标准方法是收集大量的人工偏好标注数据。也就是说,研究人员需要人工标注模型生成的响应,以确定哪个响应更好。这类数据成本高昂,尤其是对于复杂任务(例如编码、数学)的专家标注需求。此外,随着新模型性能的提升,基于旧模型响应的标注数据也会过时,变得不再适用。
1.2 现有方法的局限性:
– 收集人工偏好数据的过程非常耗费资源。每个模型生成的响应都需要专家进行仔细的评估,这对于涉及高技术的任务(如编程或复杂的数学推理)特别耗时耗力。
– 更重要的是,随着模型的不断改进和提升,之前基于旧版本模型标注的偏好数据逐渐变得无效或过时。新模型的响应质量可能与旧模型大不相同,因此人工标注的偏好数据不再能准确反映当前模型的表现。
1.3 本文提出的方法
– 为了解决上述问题,论文提出了一种不依赖人工标注数据的自我训练方法(Self-Taught Evaluator)。这个方法的核心在于,完全通过合成数据来改进评估模型,从而不需要收集昂贵的人工偏好标注数据。
– 具体来说,该方法从未标注的数据(unlabeled instructions)出发,通过迭代的自我改进流程,生成对比性模型输出,并训练一个被称为“LLM评判者”(LLM-as-a-Judge)的模型。这个评判者模型能够生成推理链(reasoning traces)并作出最终的评判。
– 每次迭代,评估器会使用改进后的模型预测结果继续自我训练,从而逐步提升评估性能。整个过程中完全不需要人工标注的偏好数据。
1.4 实验结果
– 通过实验,研究人员表明,使用这种自我训练的评估器可以显著提升模型的评估性能。具体来说,论文在使用强大的Llama3-70B-Instruct模型进行实验时,评估准确率从75.4%提升到了88.3%(通过多数投票法进一步提升到88.7%)。
– 这一性能不仅超过了常用的LLM评判者模型(如GPT-4),甚至能够匹敌那些通过标注数据训练的顶尖奖励模型。
总结:
本论文的核心思想是,使用一种无需人工标注的自我训练机制,通过合成的数据迭代改进评估模型。该方法解决了依赖人工标注数据成本高且易过时的问题,同时在多个基准测试上展现了出色的评估性能。这为大规模语言模型的开发和评估工作提供了新的思路。
2 相关工作(Related Work)
在这一章中,论文回顾了与LLM评估相关的几类关键研究方向,具体涵盖了基于LLM的评估器和合成数据的使用。接下来我们详细解读各个部分。

2.1基于LLM的评估器(LLM-based Evaluators)
– 传统的评估基准往往依赖于自动化的评价指标,这些指标需要参考答案来评估(例如蓝色得分用于翻译任务)。然而,对于开放式问题或复杂指令,这些基准存在显著局限性,因为在这类任务中可能存在多个合理答案,无法用固定的标准答案来评估(例如创造性写作、编程)。
– 最近的研究转向了将LLM作为评估器的工作,利用这些模型来评估生成的响应质量。这类方法通常有以下两种形式:
– 一类方法是将LLM作为分类器,直接输出分数(例如Zhu et al., 2023;Wang et al., 2024a)。这种方法可以简化评估过程,但由于是直接给出结果,缺乏解释性。
– 另一类方法是通过“LLM评判者”(LLM-as-a-Judge)的形式进行评估。这种方法生成推理链(chain-of-thought),即模型通过自然语言生成解释的步骤,帮助得出最终评判。这种方式不仅可以做出评判,还能为判断提供合理解释(例如Zheng et al., 2023)。推理链可以增强结果的透明度,使得决策过程更加可解释。
– 尽管LLM评估展示了很大潜力,特别是在替代人类评估方面,但现有的LLM评估器在不同任务上的表现仍然存在很大差异。许多现有方法的评估结果在各个任务上存在显著波动,说明仍需进一步提升评估模型的稳定性和准确性(Bavaresco et al., 2024)。
2.2.合成数据(Synthetic Data)
– 合成数据作为获取训练样本的一种高效方式,近几年得到了广泛应用,尤其是在获取真实数据非常困难的情况下。例如,天气数据的覆盖条件、代码任务等场景中,使用合成数据可以填补数据的不足。
– 合成数据不仅易于定制,还可以根据不同的需求生成特定的评价标准或安全约束。对于模型对齐(model alignment),合成数据可以帮助改进原始模型的能力(例如Yuan et al., 2024;Li et al., 2024a)。
– 在评估场景下,合成数据已经被用于评估诸如事实性、任务安全性、编程以及指令跟随等任务。很多研究已经表明合成数据与真实的人类判断具有很强的相关性,例如用以测量事实性(Wei et al., 2024)、安全性(Perez et al., 2023)等任务的合成数据表现出与人类评估一致的结果。
– 一种相关的方法是通过“最佳-最差对比”(West-of-n)的方式生成合成偏好数据,这类数据通过构建来自模型输出的最佳和最差响应对来提升奖励模型的训练效果。具体到LLM评判者模型,合成的响应对通过模型生成的高质量和低质量响应进行对比,从而训练出更好的评估器模型。
2.3.小结
– 本章回顾了目前基于LLM的评估方法和合成数据在模型训练中的应用。虽然LLM评估已经展示了取代人类评估的潜力,但目前仍存在任务稳定性问题。合成数据作为一种高效、灵活的训练数据源,已经证明了其在多个领域中的有效性,为解决数据稀缺问题提供了可靠的途径。
3. 方法(Method)
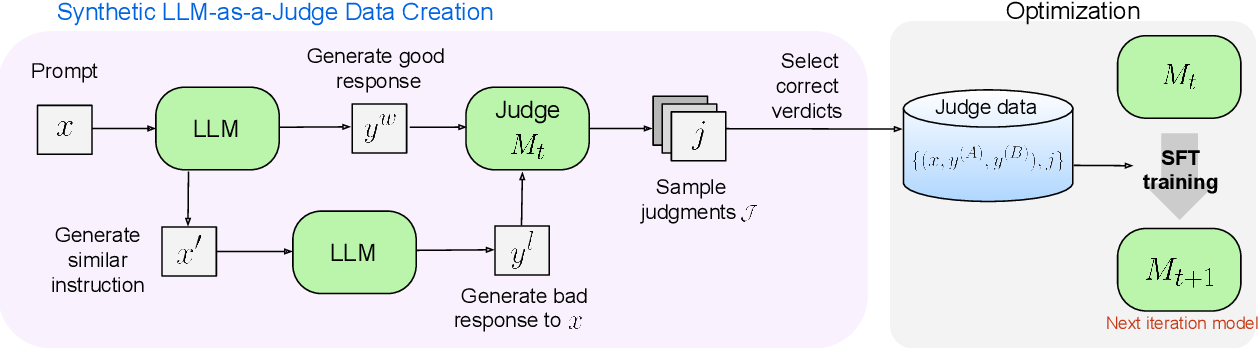
在这一章节,论文详细介绍了如何通过迭代的自我训练来改进评估模型(Self-Taught Evaluator),该方法完全依赖合成数据而非人工标注数据。整个方法分为以下几个步骤,每个步骤逐步构建、训练并优化评估器模型。
3.1 初始化(Initialization)
在开始的阶段,假设我们已经拥有了一个大型的未标注的用户指令集(human-written user instructions)和一个初始的LLM模型(通常是预训练过的,如Llama3-70B-Instruct)。
- 初始模型:我们将使用这个预训练的模型作为评估器的初始模型,称为“种子模型”(seed LLM),其在没有任何额外训练的情况下用于生成初始响应。
- 指令集:输入的指令集包括各种未标注的用户请求,这些指令可能来自实际系统中收集的真实对话数据。每个指令可以是单一问题,或者是用户和模型之间的多轮对话历史。
这个阶段的目标是为下一步创建评估数据做好准备。
3.2 指令选择(Instruction Selection)
由于未标注的指令数据可能质量参差不齐,且涉及不同难度、话题广泛,模型可能无法均衡处理所有类型的任务。因此,需要选择一个平衡且具有挑战性的指令集用于训练。
- LLM分类:通过预先训练好的LLM对指令进行分类(例如,编码、推理、头脑风暴等类别),确保训练集中包含了广泛的任务类型,而非集中于某一特定类型。
- 指令筛选:根据模型能力选择一些高质量的、有挑战性的指令。剔除掉那些噪声较大、或者对于训练评估器帮助不大的指令。
通过这个步骤,研究人员构建了一个精心挑选的训练指令集,确保这些指令能够充分挑战模型并有助于提高其评估能力。
3.3 响应对构造(Response Pair Construction)

在这一步中,研究人员通过合成方法生成一对“好”和“差”的模型响应,创建用于训练的偏好数据。
- 好响应:对于每一个输入指令,首先使用种子LLM生成一个高质量的响应,称为“好响应”(winning response)。
- 差响应:然后通过稍微修改原始指令生成一个“噪声指令”(noisy instruction),并让LLM根据这个噪声指令生成一个“差响应”(losing response)。虽然这个差响应在新指令下看起来合适,但对于原始指令而言却是不正确的。这种生成方式避免了直接让模型生成明显错误的响应,而是通过更细致的方式制造出质量较差的输出。
这一步骤的关键在于,通过生成高质量与低质量的对比响应(preference pairs),创建了用于训练模型的合成偏好数据。每个数据对都标注了哪个响应是优胜的。
3.4 评判注解(Judgment Annotation)
在拥有一对“好”与“差”响应之后,模型作为评估器(LLM-as-a-Judge)来对这些响应进行评估和判断。
- 推理链生成:在判断哪个响应更优之前,评估模型会生成一条推理链(chain-of-thought)。这个推理链是一系列推理步骤,用自然语言描述模型的评估过程,帮助它作出更有解释力的最终判断。
- 多样性采样:对于每一个响应对,模型会采样生成多个不同的推理链和判断结果。然后,通过“拒绝采样”(rejection sampling),排除那些不符合真实情况的判断(即模型判断的优胜响应与之前设定的优胜响应不一致的情况)。
- 选择最终推理:在过滤掉错误的判断后,从剩余的正确判断中随机选择一个作为最终的训练样本。如果没有任何正确的判断,则丢弃该样本。
这一步的目标是生成正确的训练样本,模型通过自我生成的推理链与判断来构建出一个标注好的训练集。
3.5 模型微调(Model Fine-tuning, Iterative Training)
在收集到足够的训练数据后,开始对LLM进行微调。这个过程是迭代进行的,每次迭代模型都会使用更新后的预测结果来进一步优化自身。
- 自我提升:随着模型的改进,每一轮训练之后,它将使用更高质量的判断数据,逐渐扩大训练集的规模。这个过程形成了一个“自动课程”(automatic curriculum),随着模型的能力增强,训练集的质量也随之提高。
- 训练迭代:每一轮的模型训练包括两个步骤:
通过这种迭代优化,评估器模型的能力会不断提高,最终在不依赖人工数据的情况下,达到与使用人工标注数据的顶尖模型相当的性能水平。
总结:
这一章节详细阐述了论文提出的方法,即通过合成数据和自我训练的方式,迭代提升评估模型的能力。核心流程包括从未标注的数据中生成高低质量的响应对,通过LLM作为评判者生成推理链和判断结果,最终利用这些合成数据对模型进行微调。这一创新方法有效解决了对人工标注数据的依赖问题,同时能够随着训练的进行自动提升模型的评估性能。
4. 实验(Experiments)
在这一章节中,论文通过一系列实验验证了自我训练评估器(Self-Taught Evaluator)方法的有效性。实验部分的结构分为三个主要部分:实验设置、使用的数据来源,以及实验的评估方法。接下来我们详细解读每个部分。
4.1 实验设置(Experimental Setup)
训练过程:
- 初始模型:实验从一个预训练的Llama3-70B-Instruct模型开始,作为种子模型(M0)。在每次迭代训练中,当前模型生成合成的偏好数据(即好与差的响应对),并基于这些数据进行微调。
- 迭代过程:实验通过多次迭代训练模型,每一轮训练后,新的模型会生成更高质量的响应对,用于下一轮的训练。迭代次数设定为5轮。模型通过fine-tuning来逐渐改进。
实现细节:
- 使用了fairseq2库来进行指令微调(instruction fine-tuning),并且使用vLLM库来处理推理任务。在训练过程中,负对数似然损失(negative log-likelihood loss)仅应用于模型生成的推理部分,即推理链(reasoning chain)。训练超参数包括学习率、权重衰减、梯度累积等,详见表格中的超参数设置。
指令与响应:
- 指令来源:实验中的指令数据来自于“WildChat”数据集(Zhao et al., 2024),其中包含了大量的人类编写的对话指令。为了挑选适合的高质量指令,研究者使用了Mixtral 22Bx8模型对指令进行了分类,选出了20,582条与推理相关的指令作为训练集。
- 合成响应:针对每条指令,生成一对“优胜”(好响应)和“劣势”(差响应)响应对。这些响应对是通过模型生成的。
评判注解:
- 多样性采样:对于每一个训练样例,研究人员从模型生成的评判结果中随机采样15个不同的判断。通过拒绝采样的方式过滤掉不正确的判断,只保留正确的评判数据。然后,将这些正确的推理链和判断结果作为最终的训练样本。
- 平衡训练集:实验确保训练集中不同偏好标签的样例数量相等,即“响应A更好”和“响应B更好”的例子均衡分布。
多数投票推理(Majority Vote Inference):
- 由于LLM评判者通过生成推理链作出最终判断,论文还提出了一种“多数投票推理”方法。在推理时,通过多次采样(N次),选择最常见的判断作为最终结果。多数投票方法通常能够进一步提升模型的准确性。
4.2 其他数据来源(Other Data Sources)
为了更全面地评估方法的有效性,研究人员还通过其他数据源生成合成的评判数据,并进行了实验对比。这些数据源包括:
- HelpSteer2 数据集:这个数据集包含了关于响应的帮助性、正确性、连贯性、复杂性和冗长度的标注。研究人员使用这些标注生成偏好数据,并通过加权方式得出最终的偏好判断。
- GSM8K(数学推理数据集):这个数据集用于数学推理任务,研究人员从指令跟随模型中多次采样生成优胜响应(winning response),并用不符合真实结果的响应作为差响应。
- WildChat的编码指令:除了推理类指令外,研究人员还使用了WildChat中的编码指令进行实验,生成了编码任务的合成偏好数据。
- hh_rlhf 数据集:这是一个专注于安全性任务的训练数据集,研究人员生成了这些任务的合成评估数据,使用人类标注的偏好作为评判标准。
4.3 评估(Evaluation)
为了评估自我训练评估器的性能,研究人员选择了以下几个基准测试:
- RewardBench:这个基准测试用于评估奖励模型的性能,实验使用该基准测试的标准评估协议来评估不同模型的表现。
- MT-Bench:该测试评估LLM在不同任务中的表现,重点考察模型生成的响应与人类评判的一致性。为了确保结果的公平性,实验只在没有平局(即两个响应同样好的情况)时计算一致性得分。
- HelpSteer2:实验还在HelpSteer2数据集的验证集上评估了模型的准确性,包括优胜响应在不同排序下的表现以及位置一致性准确性(position-consistent accuracy)。
小结:
在这一章节中,论文通过设置详细的实验流程,使用了多个数据源与基准测试评估了自我训练评估器的性能。研究人员不仅验证了自我训练方法在合成数据上的有效性,还通过与人工标注数据和现有评估模型的对比,展示了该方法的强大潜力。
5. 结果(Results)
本章节通过实验结果展示了自我训练评估器(Self-Taught Evaluator)的性能表现。研究人员评估了该模型在多个基准测试上的结果,并与其他现有模型(包括人工标注数据训练的模型)进行了对比。
5.1 奖励基准测试(RewardBench)
主要结果:
- 自我训练评估器在RewardBench测试中的表现显著提升。经过5轮迭代训练后,评估模型的整体准确率从初始的75.4%提高到88.3%,使用32次采样的多数投票(majority vote)方式,模型准确率进一步提升至88.7%。
- 这种表现不仅优于GPT-4等常用的LLM评判者模型,还能够匹敌通过人工标注数据训练的顶尖奖励模型。例如,使用HelpSteer2数据训练的Llama-3-70B评估模型的表现为85.6%,而自我训练评估器不依赖任何人工数据,表现更为出色。
细分类别的结果:
- 实验发现,自我训练评估器在某些任务类型上表现尤为优异,特别是在“聊天困难问题”(Chat Hard)、“安全性问题”(Safety)和“推理问题”(Reasoning)上表现突出,优于其他模型。
- 相比之下,模型在“普通聊天任务”(Chat)上的表现略低于初始模型。这可能是因为训练集中主要关注的是较难的任务,而忽略了简单的任务。
5.2 MT-Bench



一致性评估:
- 在MT-Bench测试中,研究人员评估了模型对不同任务的评判结果与人类评判的一致性。实验结果表明,自我训练评估器在多轮训练后,其与人类评判的一致性逐步提升。
- 第五轮迭代后的模型在非平局任务上与人类评判的一致性达到了78.9%,并且通过多数投票采样后,这一结果提升至79.5%。这个表现与GPT-4模型基本持平,说明自我训练评估器可以与顶尖LLM评判者模型相媲美。
5.3 HelpSteer2
位置一致性与准确性评估:
- HelpSteer2验证集主要评估模型的准确性和位置一致性。实验结果表明,自我训练评估器在逐轮训练后表现显著提升。在第五轮训练后,平均准确率达到了71.0%,位置一致性准确率为60.6%。
- 相比于初始的Llama-3-70B-Instruct模型,自我训练评估器在多个任务上的表现均有提升,尤其在对“正确与错误响应顺序”处理上表现更为稳定。
数据源的对比:
- 实验还比较了使用不同数据源训练的评估器模型在RewardBench上的表现。结果表明,基于推理任务(reasoning-based)的合成数据训练的模型,在推理任务上的表现最好,达到了83.5%的准确率。
- 总体上,所有不同类型的合成数据都能够有效提升模型的性能。不同数据源对特定任务类型的提升效果不一,例如数学数据源对数学类任务有更好的提升,而安全性数据源对安全任务提升明显。
总结:
实验结果总结了以下关键点:
- 自我训练评估器的表现显著提升:通过合成数据的迭代训练,该方法能够在没有人工标注数据的情况下,实现与人工标注数据训练的顶尖模型相当的性能。这在RewardBench和MT-Bench等基准测试中表现得尤为突出。
- 多样性采样与多数投票策略有效:通过采样生成多个推理链和判断结果,并使用多数投票方式,模型的准确性得到了进一步提升。这表明多数投票策略在提升模型评估稳定性方面具有显著效果。
- 自适应提升:随着训练轮次的增加,模型能够生成更高质量的评判数据,且训练数据的数量和质量会自动提升,形成了一个“自动课程”(automatic curriculum),即模型会随着其能力的增强,自动生成更优质的训练数据,从而进一步优化自己。
这一章节的实验结果展示了自我训练评估器的卓越性能,证明了这一方法在没有人工标注数据的情况下,能够匹敌甚至超越依赖人工数据的模型。
6. 消融与分析(Ablations and Analysis)
这一章节旨在通过消融实验和深入分析,探讨自我训练评估器(Self-Taught Evaluator)的有效性,并进一步了解不同训练策略和数据源对模型表现的影响。
6.1 来自其他来源的合成数据(Synthetic Data from Other Sources)

实验目的:
为了评估自我训练评估器在不同任务和数据来源上的表现,研究者使用了多个不同来源的合成数据进行训练,并观察了它们对模型性能的影响。
主要发现:
- 不同数据源(如推理、数学、编程等任务)都对模型性能有不同的提升。
- 在RewardBench测试中,使用“推理类数据源”(reasoning data)训练的模型表现最佳,整体得分为83.5%,在推理相关任务上的表现尤其突出。
- 数学类数据源(GSM8K)对数学任务表现出色,准确率达到了83.0%。
- 另外,安全性数据源对安全类任务有显著提升,表现优于基础模型,说明合成数据在特定任务类型上的效果尤为显著。
结论:
不同的数据源有助于提升特定任务类型的表现。推理类任务的数据源对于复杂推理任务的效果最好,而数学和安全性任务的合成数据对模型在相应领域的表现提升显著。通过选择合适的合成数据,模型可以在不同任务类别上实现针对性的优化。
6.2 合成的糟糕响应生成(Synthetic Bad Response Generation)

实验目的:
为了评估不同的“差响应”生成策略对模型训练效果的影响,研究者进行了消融实验,比较了生成“噪声指令”与直接生成糟糕响应的效果。
实验设计:
- 生成噪声指令:这是主要方法,通过生成与原指令稍有不同的“噪声指令”来生成差响应。
- 直接生成糟糕响应:另一种方法是直接通过提示模型生成错误或较差的响应,不依赖于修改原指令。
结果:
- 直接生成糟糕响应的方式仍然有效,模型在RewardBench上的整体得分为80.7%,但相比通过生成噪声指令的方式略逊一筹(83.8%)。
- 实验表明,生成噪声指令的方式能够更细致地区分出“优胜”与“劣势”响应,并且在训练中效果更好。
结论:
生成“噪声指令”然后生成响应的方式相较于直接生成糟糕响应,更有助于模型理解细微的响应质量差异,因此能够带来更好的训练效果。

6.3 与人工标注数据的比较(Comparison of Synthetic Data with Human Annotated Data)
实验目的:
研究人员将通过合成数据训练的模型与使用人工标注数据训练的模型进行了对比,评估合成数据的有效性。
结果:
- 在RewardBench测试中,使用合成数据训练的自我训练评估器能够达到88.3%的准确率,超过了使用人工标注数据训练的评估器(85.6%)。
- 通过人工数据训练的模型在一些简单任务上的表现略好,但在复杂任务(如推理和安全性任务)上,合成数据训练的模型表现更为出色。
结论:
自我训练评估器通过合成数据迭代训练,在不使用人工标注的情况下,能够达到甚至超越人工数据训练模型的表现,尤其是在复杂任务上。
6.4 从标注数据初始化的迭代训练(Iterative Training by Initializing from Labeled Data)
实验目的:
为了探讨是否可以通过结合人工标注数据和合成数据进一步提升模型性能,研究人员首先使用人工标注数据进行初始模型训练,然后再通过合成数据进行自我训练。
结果:
- 实验表明,虽然这种方法有效,但并未明显优于完全依赖合成数据进行迭代训练的模型。在RewardBench上的表现为87.0%,略低于纯合成数据训练的模型(88.3%)。
结论:
人工标注数据作为初始化阶段的辅助并没有明显优势,合成数据完全可以独立完成训练,并且在某些任务上甚至表现得更好。

6.5 合并合成数据与人工标注偏好数据(Combining Synthetic and Human Labeled Preference Data)

实验目的:
研究人员还实验了合并合成数据和人工标注数据对模型训练效果的影响,尝试通过两者的结合进一步提升模型表现。
结果:
- 不同比例的数据混合(例如1:1,1:5等)均能够带来不错的效果,特别是在某些任务上有小幅提升,但整体表现与完全依赖合成数据的结果相差不大。
- 例如,在RewardBench测试中,1:2比例的合成与人工数据混合训练的模型达到85.8%,仅比纯合成数据略低。
结论:
合并人工标注数据和合成数据虽然能够提升部分任务的表现,但整体表现仍然与合成数据单独训练的模型相差不大。合成数据在训练中展现了极大的潜力,足以独立完成高质量评估器的训练。
6.6 指令复杂度(Instruction Complexity)

分析目的:
研究人员对使用的训练数据集进行了复杂度分析,探讨不同类型指令对模型训练效果的影响。
发现:
- 精选的训练数据集相较于原始数据集,更多涉及逻辑推理和科学类问题,这些问题的复杂度更高,模型在处理这些问题时也展现出了更好的效果。
- 研究发现,较长的指令往往对应较复杂的任务,如长篇的编码指令或长段文本的推理任务。而较短的指令通常对应较简单的任务,如聊天或提取任务。
结论:
更复杂的指令更能充分挑战模型,并在训练过程中帮助模型学习复杂的推理能力。实验选择的高质量指令集在帮助模型提高评估能力方面效果显著。
小结:
本章节的消融实验与分析表明:
- 合成数据在模型训练中能够有效替代人工标注数据,尤其在推理等复杂任务中表现优异。
- 通过生成“噪声指令”来制造差响应的方式比直接生成糟糕响应更为有效。
- 合并人工与合成数据可以提升部分任务表现,但总体效果仍然与合成数据单独训练相当。
- 复杂度较高的指令对模型的训练效果更显著,有助于提升模型的推理能力。
这些实验验证了自我训练评估器方法的有效性,并提供了多种优化策略来提升模型在不同任务上的表现。
7. 结论(Conclusion)
在这一章节,论文总结了研究工作的主要贡献和实验结果,并探讨了自我训练评估器(Self-Taught Evaluator)的广泛影响与潜在应用。以下是详细解读:
主要贡献:
- 提出了一种新的评估器训练方法
论文通过合成数据的方式,提出了一种无需依赖人工标注数据的自我训练评估器方法。这一创新点打破了以往评估模型必须依赖昂贵且耗时的人工偏好数据的限制,显著降低了成本。
- 成功提高了LLM评估器的性能
通过合成数据迭代训练,模型能够在评估任务上逐步提升性能,最终在多个基准测试(如RewardBench和MT-Bench)中,达到了与使用人工标注数据训练的顶尖奖励模型相当的表现,甚至在部分复杂任务上超越了这些模型。
- 不依赖人工标注,表现优异
自我训练评估器在完全不使用人工标注数据的情况下,能够显著提升模型性能,尤其在复杂推理和安全性任务等高难度任务上表现出色。实验结果表明,这一方法的效果与使用人工数据训练的模型相当甚至更优。
实验总结:
- 在RewardBench和MT-Bench上的出色表现
自我训练评估器在RewardBench上的最终得分为88.3%,通过多数投票进一步提升至88.7%,超越了许多现有的评估模型,如GPT-4。在MT-Bench测试中,模型与人类评判的一致性达到了79.5%,表现与GPT-4持平。
- 广泛适应性和通用性
通过实验和消融分析,研究表明,自我训练评估器方法具有很强的适应性,适用于不同的数据来源、任务类型和复杂度。这使得该方法在应用范围上具有很大的灵活性和通用性,适用于多种复杂任务的评估和模型对齐工作。
方法优势:
- 高效的自我改进
论文提出的方法通过合成数据进行迭代训练,逐步提升评估器的能力,并且模型能够自动生成更高质量的训练数据。这种“自我改进”的机制大大减少了对人工干预的依赖,使得模型能够随着时间的推移自动优化自身评估能力。
- 降低成本与时间消耗
使用合成数据代替人工标注数据极大地降低了模型开发和训练的成本。这一方法不仅减少了对专家人工标注的需求,还避免了随着时间推移而导致的标注数据过时的问题。相较于传统方法,这为大规模语言模型的开发与评估提供了更为高效的解决方案。
- 具备扩展性
这一方法展示了强大的扩展性和灵活性,适用于多种任务类型,无论是推理、编程、安全性等不同的场景。模型不仅能够在多个基准测试中表现出色,还能够适应新的任务需求。
未来工作:
- 进一步提升性能
虽然自我训练评估器已经展示出极高的性能,但未来工作可以进一步研究如何在较小规模的模型上实现类似的效果,以及如何提升模型在特定任务(如简单聊天任务)上的表现。
- 扩展单一响应评估
论文目前的评估方法主要聚焦于“成对比较”(pairwise evaluation)任务。未来可以研究如何将该方法应用于单一响应的评估,或生成评分等级的评估方法,例如对每个响应打分而非进行两两比较。
总结:
本章总结了自我训练评估器的创新贡献与优异表现。通过合成数据迭代训练,模型在无需人工标注的情况下,达到了与人工数据训练的顶尖模型相当的性能。研究表明,该方法不仅在成本和效率上具有显著优势,还在复杂任务的评估中展现出强大的适应性和扩展性。这为未来大规模语言模型的评估和开发工作提供了重要的技术手段。
8. 局限性(Limitations)
在这一章节中,论文讨论了自我训练评估器(Self-Taught Evaluator)方法的局限性,分析了其在性能和适用性上的一些不足之处,并提出了未来改进的方向。
主要局限性:
1.推理成本较高
– LLM评判者模型的生成过程较长:与简单输出分数的奖励模型相比,自我训练评估器依赖于LLM-as-a-Judge模型,它需要生成完整的推理链(chain-of-thought)来解释模型的判断。生成推理链会导致更长的输出时间,增加了推理成本,特别是在大规模应用中,这会成为一个瓶颈。
– 推理资源需求大:由于生成推理链需要消耗较多的计算资源,评估复杂任务时的计算成本会明显高于传统只输出分数的评估器模型。因此,在需要高效率推理的场景中,该方法可能不如直接输出分数的模型来得高效。
2.模型规模较大
– 本文的研究使用了大规模的LLM模型(70B参数的Llama3-70B-Instruct),实验主要围绕这种大型模型展开。对于小型或中型LLM,这种自我训练方法的有效性尚未经过充分验证。由于小规模模型可能无法生成足够高质量的推理链和判断结果,未来需要研究如何在更小的模型上实现类似的效果。
3.对初始模型的依赖
– 自我训练评估器依赖于种子模型(seed LLM)的能力,即需要一个初始模型来生成初始的响应对和判断。如果种子模型的能力不足,可能无法生成高质量的初始数据,这将影响后续迭代的效果。
– 换句话说,模型的初始性能对自我训练流程有很大影响。假如初始模型不够强大,那么自我改进的过程可能会面临瓶颈,无法实现预期的性能提升。因此,自我训练评估器的有效性依赖于一个已经相当强的初始模型。
4.只针对成对比较(pairwise evaluation)任务
– 该论文中提出的自我训练评估器主要应用于成对比较任务(即在两个响应之间选择一个优胜者)。然而,评估单个响应的质量(例如给出评分)在实际应用中也是非常重要的任务。然而,论文中没有探索如何将自我训练方法应用于对单个响应进行打分或评级的任务。
– 未来可能需要扩展这一方法,研究如何评估单个响应的质量,而不是仅限于两者之间的相对优劣评估。
5.评估器生成的推理链有可能冗长
– 虽然生成推理链能够提供解释性,帮助模型给出透明的判断过程,但推理链可能在某些情况下显得冗长且复杂。特别是在处理简单任务时,生成详细的推理链可能会显得多余,反而增加不必要的计算负担。
– 这意味着自我训练评估器更适合于复杂或开放性任务,而在一些简单的评估任务中,推理链的生成可能没有那么重要。
未来改进方向:
- 降低推理成本
未来可以探索减少推理链生成的长度或复杂度,以降低模型的推理成本。例如,可以引入更加精简的推理链生成机制,或开发适应不同任务复杂度的评估器,使其能够在简单任务上生成简短推理链,复杂任务上生成详细推理链。
- 适应小规模模型
进一步研究如何在小规模模型上实现类似的自我训练效果,可以通过减少参数量、优化模型结构等方式,让该方法适应资源有限的环境。
- 单一响应的评估
论文中只探讨了成对比较的评估方法,未来可以探索如何通过自我训练方法评估单个响应的质量。例如,开发基于推理链的单响应评分机制,或者结合多种评分标准来提高单响应的评估效果。
总结:
本章节讨论了自我训练评估器方法的几个局限性,主要集中在推理成本、模型规模、初始模型依赖性以及任务类型上的限制。尽管该方法在复杂任务中展现了极大的潜力,但在实际应用中仍面临着性能优化、适应小规模模型、以及扩展到单一响应评估等挑战。未来的研究可以通过降低推理成本、适应更多任务类型和更小规模的模型,进一步提升这一方法的应用价值。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![DeepMind:强化学习处理不正确的合成数据,使大模型数学推理效率提高八倍[RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold]-AI论文](https://assh83.com/wp-content/uploads/2024/10/figure6-75x75.jpg)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)