bitnet.cpp 是 1 位 LLM(例如 BitNet b1.58)的官方推理框架。它提供了一套优化的内核,支持在 CPU 上快速无损地推理1.58 位模型(接下来将提供 NPU 和 GPU 支持)。
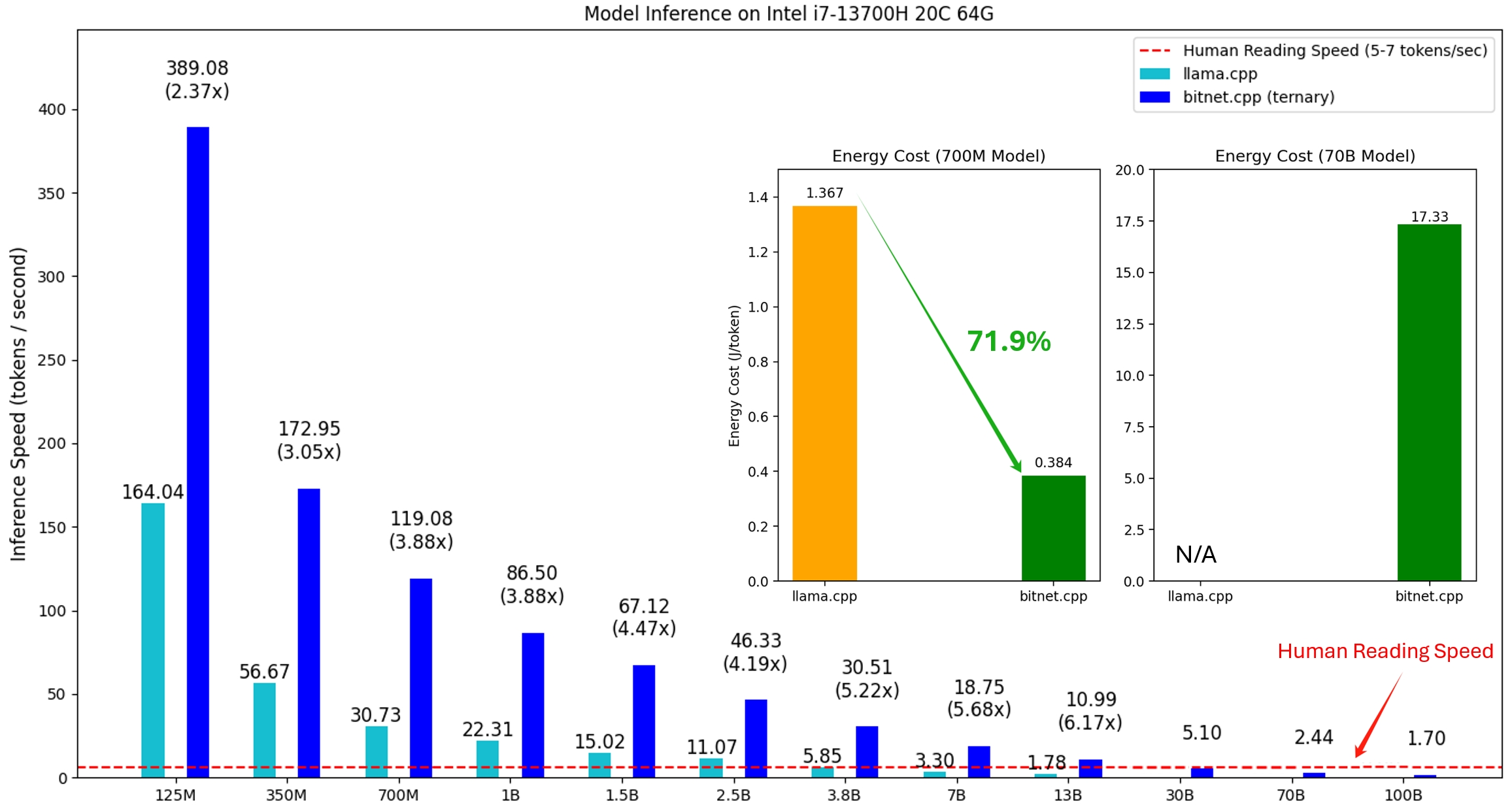
bitnet.cpp 的第一个版本支持在 CPU 上进行推理。bitnet.cpp 在 ARM CPU 上实现了1.37 倍到5.07 倍的加速,较大的模型可获得更大的性能提升。此外,它还将能耗降低了55.4%到70.0%,从而进一步提高了整体效率。在 x86 CPU 上,加速范围从2.37 倍到6.17 倍,能耗降低了71.9%到82.2%。此外,bitnet.cpp 可以在单个 CPU 上运行 100B BitNet b1.58 模型,实现与人类阅读相当的速度(每秒 5-7 个 token),大大增强了在本地设备上运行 LLM 的潜力。更多细节将很快提供。


测试模型是研究环境中使用的虚拟设置,用于展示 bitnet.cpp 的推理性能。
1 演示
bitnet.cpp 在 Apple M2 上运行 BitNet b1.58 3B 模型的演示: 演示.mp4
2 时间线
- 2024年10月17日 bitnet.cpp 1.0 发布。
- 2024 年 2 月 27 日1 位 LLM 时代:所有大型语言模型均为 1.58 位
- 2023 年 10 月 17 日BitNet:为大型语言模型扩展 1 位 Transformer
3 支持的型号
❗️我们使用Hugging Face上现有的 1 位 LLM来展示 bitnet.cpp 的推理能力。这些模型既不是由微软训练的,也不是由微软发布的。我们希望 bitnet.cpp 的发布能够在模型大小和训练 token 方面激发大规模设置中 1 位 LLM 的开发。
| Model | Parameters | CPU | Kernel | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-large | 0.7B | x86 | ✔ | ✘ | ✔ |
| ARM | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| ARM | ✘ | ✔ | ✘ | ||
| Llama3-8B-1.58-100B-tokens | 8.0B | x86 | ✔ | ✘ | ✔ |
| ARM | ✔ | ✔ | ✘ | ||
4 安装
4.1 要求
- python>=3.9
- cmake>=3.22
- clang>=18
- For Windows users, install Visual Studio 2022. In the installer, toggle on at least the following options(this also automatically installs the required additional tools like CMake):
- Desktop-development with C++
- C++-CMake Tools for Windows
- Git for Windows
- C++-Clang Compiler for Windows
- MS-Build Support for LLVM-Toolset (clang)
- For Debian/Ubuntu users, you can download with Automatic installation script
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
- For Windows users, install Visual Studio 2022. In the installer, toggle on at least the following options(this also automatically installs the required additional tools like CMake):
- conda (highly recommend)
4.2 从源代码构建
重要的:如果您使用的是 Windows,请记住始终使用 VS2022 的开发人员命令提示符/PowerShell 执行以下命令
- 克隆仓库
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet- 安装依赖项
# (Recommended) Create a new conda environment
conda create -n bitnet-cpp python=3.9
conda activate bitnet-cpp
pip install -r requirements.txt- 生成项目Build the project
# Download the model from Hugging Face, convert it to quantized gguf format, and build the project
python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s
# Or you can manually download the model and run with local path
huggingface-cli download HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens
python setup_env.py -md models/Llama3-8B-1.58-100B-tokens -q i2_s使用:setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [--log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd]
[--使用预调]
设置运行推理的环境
可选参数:
-h, --help 显示此帮助消息并退出
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens},-hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}
用于推理的模型
--模型目录 MODEL_DIR, -md MODEL_DIR
保存/加载模型的目录
--log-dir 日志目录,-ld 日志目录
保存日志信息的目录
--quant-type {i2_s,tl1},-q {i2_s,tl1}
量化类型
--quant-embd 将嵌入量化为 f16
--use-pretuned, -p 使用预调整的内核参数
5 用法
5.1 基本用法
# Run inference with the quantized model
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?\nAnswer:" -n 6 -temp 0
# Output:
# Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?
# Answer: Mary is in the garden.
用法:run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE]
运行推理
可选参数:
-h, --help 显示此帮助消息并退出
-m 模型, --模型 模型
模型文件路径
-n N_PREDICT,--n-预测 N_PREDICT
生成文本时要预测的标记数量
-p 提示,--prompt 提示
提示生成文本
-t 线程,--threads 线程
要使用的线程数
-c CTX_SIZE,--ctx 大小 CTX_SIZE
提示上下文的大小
-temp 温度,--temperature 温度
温度,控制生成文本随机性的超参数
5.2 基准
我们提供脚本来运行推理基准并给出模型。
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS]
Setup the environment for running the inference
required arguments:
-m MODEL, --model MODEL
Path to the model file.
optional arguments:
-h, --help
Show this help message and exit.
-n N_TOKEN, --n-token N_TOKEN
Number of generated tokens.
-p N_PROMPT, --n-prompt N_PROMPT
Prompt to generate text from.
-t THREADS, --threads THREADS
Number of threads to use.
以下是每个论点的简要解释:
-m,--model:模型文件的路径。这是运行脚本时必须提供的必需参数。-n,--n-token:推理过程中要生成的 token 数量。这是一个可选参数,默认值为 128。-p,--n-prompt:用于生成文本的提示标记数。这是一个可选参数,默认值为 512。-t,--threads:用于运行推理的线程数。这是一个可选参数,默认值为 2。-h,--help:显示帮助消息并退出。使用此参数显示使用信息。
例如:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4 该命令将使用位于的模型运行推理基准/path/to/model,利用 4 个线程从 256 个令牌提示中生成 200 个令牌。
对于任何公共模型都不支持的模型布局,我们提供脚本来生成具有给定模型布局的虚拟模型,并在您的机器上运行基准测试:
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M
# Run benchmark with the generated model, use -m to specify the model path, -p to specify the prompt processed, -n to specify the number of token to generate
python utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128



![AFLOW:自动生成代理工作流程[Automating Agentic Workflow Generation]-AI论文](https://assh83.com/wp-content/uploads/2024/10/4-Figure2-1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)