论文的标题是《Advancing LLM Reasoning Generalists with Preference Trees》,主要讨论了如何通过偏好树结构提升大语言模型(LLMs)在推理任务中的表现。以下是论文的目录章节:
1. 引言 (Introduction)
在论文的引言部分,作者们首先指出,当前的对齐技术大大推动了开源大语言模型(LLMs)的发展,使其能够满足用户期望并符合人类价值观。然而,尽管在特定能力(如代码生成、数学问题解决等)上取得了成功,这些模型在处理更为复杂且多样化的推理问题时,仍远不及最先进的专有模型。引言部分提出了两个主要的性能差距原因,并介绍了本文的研究目标,即通过开发更高质量的对齐数据和改进偏好学习技术来缩小这一差距。

1.1 性能差距的原因
作者认为,开源模型在复杂推理任务中表现不佳,主要是由以下两个关键因素导致的:
- 缺乏高质量的对齐数据
:现有的开源模型在复杂推理任务中往往表现不如预期,这是因为缺乏能专门用于训练推理能力的数据集。许多现有数据集可能更侧重于对话或常规任务,而没有为推理任务提供足够的深度和复杂性。
- 偏好学习技术的不足
:虽然偏好学习在模型对齐和提升用户体验中起到了重要作用,但现有的偏好学习方法并没有充分适用于推理任务。这些方法可能在对话中表现良好,但在推理任务中效果并不理想。具体而言,它们在推理过程中没有考虑到多步规划、工具集成、以及与环境和用户的交互能力。
1.2 EURUS模型
为了缩小上述性能差距,作者提出了一套名为EURUS的LLMs,这些模型从Mistral-7B和CodeLLaMA-70B模型微调而来。EURUS在多个复杂推理基准测试上,取得了所有开源模型中最好的整体表现,特别是在大学级别的STEM问题(如TheoremQA)和竞赛级别的编程问题(如LeetCode竞赛)中表现尤为突出。EURUS-70B甚至超过了GPT-3.5 Turbo。
1.3 ULTRAINTERACT数据集
EURUS的强大表现主要归因于其训练数据集ULTRAINTERACT。ULTRAINTERACT是一个专门为复杂推理任务设计的大规模高质量对齐数据集,包含数学、代码生成和逻辑推理问题。每个指令在ULTRAINTERACT中都附带了一个“偏好树”,用于指导模型学习不同的推理路径。这个数据集通过提供多样化的规划策略、与环境的多回合互动轨迹、以及成对的正确与错误示例,帮助模型进行推理过程中的偏好学习和微调。
1.4 偏好学习的新探索
ULTRAINTERACT数据集不仅用于监督微调,还支持偏好学习。作者们深入探索了偏好学习技术在推理任务中的应用,发现某些传统的偏好学习算法在推理任务中的表现并不如在常规对话任务中那样有效。基于这些发现,作者提出了一种新的奖励建模目标,结合ULTRAINTERACT,使得偏好学习在推理任务中表现更加出色。
1.5 本文贡献
引言最后总结了本文的主要贡献:
- 提出并构建了EURUS模型,特别针对推理任务进行了优化,取得了开源模型中的最佳表现。
- 开发了ULTRAINTERACT数据集,专门用于提高LLMs在推理任务中的能力。
- 通过研究现有偏好学习算法在推理任务中的表现,提出了一个新的奖励建模目标,进一步提升了推理任务中的偏好学习效果。
引言部分为论文奠定了研究背景和动机,明确了复杂推理任务中的开源模型与专有模型之间的差距,并介绍了通过新数据集和新方法改进模型的路径。
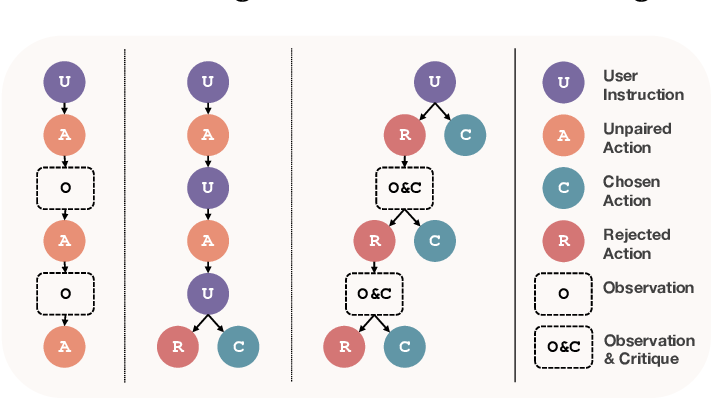
2. ULTRAINTERACT: 推理任务的树状对齐数据
在这个章节,作者详细介绍了ULTRAINTERACT数据集的设计和实现。ULTRAINTERACT是一个专为复杂推理任务设计的大规模、高质量对齐数据集,它通过“偏好树”来增强大语言模型(LLMs)在推理任务中的能力。作者通过这一数据集的设计,旨在解决现有开源模型在推理任务上表现不足的问题。

2.1 指令选择:强调复杂性、质量与多样性
ULTRAINTERACT专注于三类推理任务:数学问题解决、代码生成和逻辑推理。这些任务的复杂性、多样性和数据质量直接影响模型的推理能力。为了保证高质量,数据集选择了GPT-3.5 Turbo等强大模型无法解决的复杂问题,并且限制数据集只包含有真实解决方案的任务。这些高质量的标准能确保模型能够在监督学习和偏好学习中获得明确的监督信号。
作者指出,ULTRAINTERACT中的每个指令不仅仅是单一的指令,而是包含多个不同的推理模式和策略,确保了多样性。例如,数据集包括了不同类型的推理模式(如序列式推理和工具创建),以及明确的步骤和代码执行。通过这样的方法,模型可以学习到多样化的推理路径,并能适应更复杂的推理场景。
2.2 每回合的分解与交互
在处理复杂问题时,模型通常需要通过多次与环境和用户的交互,逐步解决问题。因此,ULTRAINTERACT的数据设计也考虑到了这一点,每个指令都会被模型逐步分解为若干子问题,每个子问题再通过一系列的动作来解决。这些动作可以是代码生成或是文本推理,并且在每个步骤中模型都能与环境进行交互。

ULTRAINTERACT支持的多回合互动使得模型能够学习如何根据环境的反馈不断修正错误和优化推理过程。例如,模型在解决一个数学问题时,首先会通过代码或文本的形式生成初步解答,环境会返回执行结果或错误提示,随后模型通过这些反馈再进行下一步推理,直至问题解决。通过这种方式,模型不仅可以生成解决方案,还能学会在不断优化过程中如何修正错误。
ULTRAINTERACT中每个指令的解答流程被分成若干回合,每个回合模型都需要根据环境反馈进行调整,从而提高推理的准确性和鲁棒性。这个多回合交互机制能够帮助模型更好地适应复杂推理任务,并且更擅长与用户或环境互动。
2.3 偏好树:跨多个回合的偏好学习
ULTRAINTERACT的核心设计之一是使用了偏好树结构。偏好树是指对每个指令,模型的动作被组织为一个二叉树结构,其中每个节点代表一个动作,节点间连接代表了从根到叶的推理路径。根节点是初始指令,叶节点是问题的最终解决方案,整个路径代表了模型推理的完整过程。
- 正确和错误的动作对比
:偏好树的每条路径包含正确的和错误的动作,这些成对的数据能用于偏好学习。模型通过这些成对数据,能够学习到哪些动作是正确的,哪些是错误的,从而更好地优化决策过程。
- 多轮偏好学习
:偏好树不仅适用于单一回合的数据,也适用于多回合的交互。在每一轮交互中,模型会根据环境反馈生成下一步动作,偏好树记录了模型在每一回合中的所有正确和错误的动作。这意味着模型可以根据每一轮的反馈调整推理策略,而不是简单地依赖最终结果。作者指出,这种跨回合的偏好学习能够显著提升模型的推理能力,因为它允许模型根据多个回合的交互学习更优的推理路径。
- 树结构扩展
:在偏好树中,每一个错误的动作都会被扩展到下一回合,模型继续与环境交互,直到找到正确的解决方案。这样一来,偏好树不仅记录了模型的错误和正确选择,还记录了模型在错误选择之后如何改正错误的过程。ULTRAINTERACT允许模型在这个过程中不断扩展其推理能力,从而提高其在复杂问题上的表现。
2.4 数据集规模与统计
为了确保模型能够学习到足够复杂和多样化的推理过程,ULTRAINTERACT包含了大规模的数据集,涵盖了从数学、代码到逻辑推理的多种任务。作者在表格中总结了数据集的具体规模,包括指令数量、回合数量、偏好对数量等信息,展示了ULTRAINTERACT在推理任务中的广泛适用性。

例如:
- 数学任务包含了22,928个指令,每个指令平均包含5个回合的互动。
- 代码生成任务包含了20,463个指令,每个指令平均包含4个回合。
- 逻辑推理任务中包含4,467个指令,主要在两个回合内完成互动。
这些数据为模型提供了充足的多回合交互学习机会,能够帮助模型在不同的推理任务中获得强大的推理和修正能力。
小结
ULTRAINTERACT是一个专门为复杂推理任务设计的数据集,其独特之处在于通过偏好树结构,使模型能够在多回合互动中学习如何推理、修正错误并最终得出正确答案。通过偏好学习,模型能够识别出哪些推理路径是正确的,并通过多轮反馈不断优化自身推理过程。这使得ULTRAINTERACT不仅能用于模型的监督学习,还能显著提升模型的偏好学习效果,特别是在复杂推理任务中的表现。
3. EURUS: 推理中的开源顶尖LLM
在这一章节,作者介绍了EURUS模型的设计和优化过程,特别是如何通过监督微调、偏好学习和奖励建模,使EURUS在复杂推理任务中达到开源模型的顶尖水平。EURUS模型的核心优势在于它能够处理多轮交互、复杂推理任务,并在数学、代码生成、逻辑推理等领域中表现出色。

3.1 监督微调
监督微调(SFT, Supervised Fine-Tuning)是提升语言模型的基本方法之一。EURUS-7B和EURUS-70B模型分别从Mistral-7B和CodeLLaMA-70B基础上进行微调。微调过程中,EURUS模型主要使用ULTRAINTERACT数据集中的正确动作进行训练。
- 选择正确的叶节点
:在微调时,作者发现使用偏好树中的正确动作进行训练效果更佳。因此,模型主要基于每个偏好树的叶节点(即最终的正确答案)进行微调,而忽略了交互历史中的其他信息。这样做可以提高模型在给定指令时生成正确推理路径的能力。
- 多样化数据混合
:为了进一步提升模型的指令跟随能力,EURUS不仅使用了ULTRAINTERACT的数据,还混合了其他数据集,例如UltraChat、ShareGPT2和OpenOrca等。这些数据集增强了模型的泛用性,使其不仅能应对复杂推理任务,还能处理更广泛的自然语言任务。
微调后的EURUS模型在多个推理基准测试中表现出色,并在不同任务中表现出强大的推理和问题解决能力。
3.2 偏好学习
除了监督微调,EURUS还通过偏好学习(Preference Learning)进一步提升模型的推理能力。偏好学习的目的是让模型通过比较不同解答的优劣来优化自身的推理路径。EURUS模型在偏好学习中使用了ULTRAINTERACT的数据,其中包含的多轮交互偏好对帮助模型在复杂任务中选择更优的推理策略。
- 偏好学习算法的选择
:作者探索了三种不同的偏好学习算法:DPO(Direct Preference Optimization)、KTO(Knowledge-Theoretic Optimization)和NCA(Noise Contrastive Alignment)。这些算法旨在通过对比不同的推理路径来优化模型的表现。然而,实验表明,DPO在推理任务中的表现不佳,反而削弱了模型的推理能力。相比之下,KTO和NCA在推理任务上表现更好,尤其是对多轮推理和复杂任务有显著的提升作用。
- 奖励建模的改进
:通过实验,作者发现偏好学习过程中所选取数据的奖励值对推理任务有很大的影响。为了进一步优化偏好学习,作者提出了一种新的奖励建模目标,鼓励模型在训练时选择更高奖励值的解答。这种方式在提高推理任务中的偏好学习效果上尤为有效。
通过偏好学习,EURUS模型能够在面对复杂推理问题时,优化解答路径,逐步提升推理的准确性和效率。
3.3 奖励建模
在偏好学习的基础上,EURUS还使用了一种改进的奖励建模方法来进一步提升推理任务中的表现。奖励建模的目标是通过为模型的每个解答赋予奖励值,让模型能够在解答过程中选择奖励值更高的路径。传统的奖励建模方法如Bradley-Terry模型(BT),主要优化相对奖励值,即比较不同解答的优劣。然而,作者发现,在推理任务中,绝对奖励值的高低对模型的最终表现有着更大的影响。
- 增强的奖励建模目标
:为了解决传统偏好学习算法在推理任务中的不足,作者提出了一种增强的奖励建模目标。新的目标不仅优化解答之间的相对差异,还通过显式地提高正确解答的奖励值来进一步提升模型的推理能力。这种增强的奖励建模方法在EURUS模型的训练中表现出显著的效果,使得模型在推理任务中的偏好学习能力大幅提升。
- EURUS-RM-7B的设计
:基于这个新的奖励建模目标,作者设计了EURUS-RM-7B奖励模型。该模型不仅能够更好地模拟人类在推理任务中的偏好,还能在复杂推理问题中提供更准确的奖励反馈。通过这个奖励模型,EURUS在自动化评估任务和偏好学习任务中表现出色,甚至在一些任务中超越了GPT-4。
小结
EURUS模型通过监督微调、偏好学习和奖励建模的多重优化,成功成为开源大语言模型中推理任务的顶尖模型。其主要优势体现在:
- 监督微调:通过ULTRAINTERACT数据集的正确动作进行训练,增强了模型的推理能力。
- 偏好学习:通过对比不同推理路径,模型学会选择最优解答,进一步提高了推理任务的表现。
- 奖励建模:新的奖励建模方法显著提升了模型在推理任务中的偏好学习效果,使得EURUS在复杂推理任务中的表现超越了现有的开源模型,甚至与GPT-3.5 Turbo相媲美。
EURUS模型的创新不仅在于技术层面的改进,还通过偏好树和多回合互动数据的使用,进一步推动了开源大模型在推理任务中的发展。
4. EURUS-7B与EURUS-70B的评估
在本章节中,作者通过多种基准测试对EURUS-7B和EURUS-70B模型进行评估,并详细分析了这些模型在不同任务中的表现。这些测试涵盖了单轮推理、多轮推理、代码生成、数学推理等复杂任务。通过这些评估,作者证明了EURUS系列模型在推理任务中具有领先的性能,尤其是在与其他开源和专有模型的对比中,表现尤为突出。

4.1 评估设置
为了评估EURUS模型的推理能力,作者设计了多个测试任务,主要包括:
- 单轮推理测试
:包括HumanEval、MBPP、LeetCode等用于代码生成的测试;以及GSM-Plus、MATH、TheoremQA、SVAMP和ASDiv等用于数学推理的测试。在这些任务中,主要使用pass@1的准确率作为评估标准,即模型在第一次尝试中成功解决问题的比例。
- 多轮推理测试
:使用MINT基准评估模型在多轮互动中的表现,特别是关注模型在第五轮中的成功率。这类测试评估了模型在多轮交互过程中是否能够不断优化推理结果,并最终解决问题。
此外,作者还使用了IFEval基准来测试模型的指令跟随能力,并通过prompt-level loose score来评估模型在跟随复杂指令时的表现。
4.2 与基准模型对比
在评估中,EURUS系列模型与多种开源模型和专有模型进行了比较,包括GPT-3.5 Turbo和GPT-4等强大模型。以下是模型对比的主要结果:
- EURUS-7B
:尽管模型规模相对较小,EURUS-7B在多个基准任务中的表现超越了许多比它大的模型。例如,在数学任务MATH、TheoremQA和SVAMP中,EURUS-7B大幅超过了其他开源模型,尤其是在复杂的数学推理任务中表现尤为出色。
- EURUS-70B
:作为更大规模的模型,EURUS-70B在评估中表现尤为强劲,尤其在代码生成和数学推理任务上,超越了GPT-3.5 Turbo。在LeetCode编程挑战和TheoremQA推理任务中,EURUS-70B的表现甚至接近GPT-4。这表明,EURUS通过优化推理能力和使用高质量的对齐数据,成功缩小了与专有模型之间的差距。
4.3 偏好学习的影响
通过ULTRAINTERACT数据集的偏好学习,EURUS系列模型在推理任务中的表现得到了进一步提升。特别是使用了KTO(Knowledge-Theoretic Optimization)和NCA(Noise Contrastive Alignment)这两种偏好学习算法后,EURUS模型在数学和多轮推理任务中的表现显著提高。
- 偏好学习的增益
:偏好学习的效果主要体现在多轮推理任务中,例如在MINT测试中,EURUS-70B模型在第五轮的成功率显著提升,表明模型能够在多轮交互中不断优化推理路径。KTO和NCA算法在这些测试中表现较好,帮助模型更好地适应复杂推理任务,而DPO(Direct Preference Optimization)算法则在推理任务中的效果相对较差。
- 偏好学习与ULTRAINTERACT数据集的结合
:偏好学习的成功不仅归功于算法,还与ULTRAINTERACT数据集的多轮交互数据密切相关。ULTRAINTERACT提供了丰富的多轮交互示例,使得模型在推理任务中能够更好地理解和优化不同回合的推理路径。
4.4 奖励建模的作用
奖励建模在提升EURUS系列模型推理能力方面也发挥了重要作用。通过新的奖励建模目标,模型能够更好地区分不同推理路径的优劣,从而选择更优的解答。这种奖励建模策略使得模型在复杂推理任务中的表现进一步提升。
- 奖励建模对推理任务的提升
:通过奖励建模,EURUS模型能够在推理过程中逐步优化解答,特别是在面对复杂的数学和逻辑推理任务时,这种优势表现得尤为明显。奖励建模结合了ULTRAINTERACT数据集中的多轮交互数据,使得模型在多轮推理中表现尤为出色。
- 新的奖励建模目标
:作者提出的奖励建模目标不仅优化了解答之间的相对奖励,还显式地提高了正确解答的绝对奖励值,从而进一步提高了模型在推理任务中的表现。这种增强的奖励建模策略帮助EURUS-7B和EURUS-70B模型在多项推理任务中获得了顶尖成绩。
4.5 主要评估结果
在评估结果中,EURUS-7B和EURUS-70B分别在多个推理基准测试中表现突出,以下是一些关键结论:
- 单轮推理
:在HumanEval、MBPP、LeetCode等单轮推理任务中,EURUS-7B和EURUS-70B均表现出色,特别是在代码生成任务中表现优于许多比它们规模更大的开源模型。
- 多轮推理
:在MINT多轮推理测试中,EURUS系列模型显示了强大的交互能力,能够通过多轮反馈不断优化推理路径,最终成功解决问题。特别是在复杂的数学推理和编程任务中,EURUS-70B的表现接近甚至超越了GPT-3.5 Turbo。
- 整体表现
:在所有测试中,EURUS-70B凭借其强大的推理能力和偏好学习算法,达到了开源模型中的顶尖水平,甚至与GPT-3.5 Turbo竞争,而EURUS-7B也展现了远超同规模模型的推理能力。
小结
本章节通过详细的基准测试,展示了EURUS-7B和EURUS-70B模型在推理任务中的卓越表现。这些测试涵盖了从代码生成到数学和逻辑推理的多个复杂任务,EURUS系列模型在这些任务中均表现优异。尤其是通过监督微调、偏好学习和奖励建模,EURUS模型在推理能力上得到了显著提升,证明了其在开源模型中的顶尖地位。
5. EURUS-RM-7B的评估
在这一章节,作者重点介绍了EURUS-RM-7B(EURUS Reward Model)的评估过程和结果。EURUS-RM-7B是一种奖励模型,主要通过对模型生成的解答进行评分,从而帮助模型选择最佳推理路径。该评估不仅展示了EURUS-RM-7B在奖励建模任务中的表现,还分析了它在提升大语言模型(LLM)推理能力上的作用。
5.1 评估设置
为了全面评估EURUS-RM-7B的表现,作者设计了多种测试任务,覆盖了不同的推理场景。以下是主要评估基准:
- RewardBench
:这是一个用于评估奖励模型的基准测试,包含多种不同的奖励建模任务,EURUS-RM-7B与其他顶尖的奖励模型进行了对比。RewardBench数据集被分为多个子集,其中最重要的是“Chat-Hard”(复杂聊天任务)和“Reasoning”(推理任务)子集。
- AutoJ
:这是一种基于人类专家评分的评估机制,主要测试奖励模型对代码和数学推理任务的表现。AutoJ能够反映模型的推理能力与人类专家意见的一致性。
- MT-Bench
:这是另一个用于奖励建模的测试,重点评估模型在多个回合中的表现,特别是推理任务中的偏好建模能力。
此外,作者还通过重新排序模型生成的答案来进一步评估EURUS-RM-7B的能力。具体来说,模型会根据EURUS-RM-7B的评分对若干候选答案进行排序,从而测试奖励模型在提升最终模型性能上的效果。
5.2 奖励建模表现
EURUS-RM-7B在RewardBench、AutoJ和MT-Bench中的表现均超越了其他开源模型,并在某些任务上甚至超越了GPT-4。
- RewardBench评估结果
:EURUS-RM-7B在“Chat-Hard”和“Reasoning”子集上表现极为出色,特别是在推理任务上,EURUS-RM-7B获得了比其他模型更高的评分。相比之下,其他奖励模型在复杂聊天任务上表现不佳,而EURUS-RM-7B不仅在推理任务上表现卓越,还能有效应对复杂对话情境。
- AutoJ评估结果
:在AutoJ的代码和数学推理任务中,EURUS-RM-7B显示出比其他奖励模型更好的表现,尤其是在代码生成任务上,EURUS-RM-7B的表现接近甚至超越了GPT-4。AutoJ的评估结果表明,EURUS-RM-7B在与人类专家评分一致性方面非常出色,这意味着它能够很好地判断哪些解答更符合人类的偏好。
- MT-Bench评估结果
:EURUS-RM-7B在MT-Bench的多回合推理任务中也表现优异,它能够有效识别多轮对话中的优劣答案,从而帮助模型选择更优的推理路径。该评估证明了EURUS-RM-7B在复杂推理任务中的奖励建模能力,特别是在多轮交互场景下的表现尤为突出。
5.3 重排序结果分析

除了奖励建模任务,作者还评估了EURUS-RM-7B在提升模型推理能力方面的作用。具体而言,作者使用EURUS-RM-7B对Mistral-7B-Instruct-v0.2模型生成的答案进行重排序,并评估其对不同任务的准确率提升效果。以下是主要结果:
- 代码生成任务
(如HumanEval和MBPP):EURUS-RM-7B显著提升了Mistral-7B的pass@1准确率,特别是在HumanEval任务中,重排序后的答案准确率提高了4-6个百分点。这表明,EURUS-RM-7B能够有效判断代码生成任务中的优劣答案,并通过重排序优化模型的最终解答。
- 数学推理任务
(如GSM8K和MATH):在数学推理任务中,EURUS-RM-7B的重排序能力同样显著提高了模型的表现,特别是在MATH任务中,pass@1准确率提升了5个百分点。这证明EURUS-RM-7B在数学推理任务中的偏好建模能力,能够帮助模型选择更为准确的解答路径。
- 多轮推理任务
:EURUS-RM-7B在MINT等多轮推理任务中的表现同样优异,通过对多轮互动生成的答案进行重排序,模型在第五轮的成功率显著提升,表明EURUS-RM-7B能够帮助模型在复杂推理场景中不断优化解答。
5.4 奖励建模目标的影响
EURUS-RM-7B的成功不仅归功于其数据和算法,还与新的奖励建模目标密切相关。传统的奖励建模目标(如Bradley-Terry模型)主要优化答案之间的相对奖励差异,而EURUS-RM-7B则引入了新的奖励建模目标,旨在提升正确答案的绝对奖励值,并降低错误答案的奖励值。

- 优化绝对奖励值的效果
:通过增强奖励建模目标,EURUS-RM-7B能够更加准确地判断正确答案,从而显著提升模型在推理任务中的表现。这种优化策略尤其适用于推理任务,因为在推理任务中,正确答案的空间比对话任务要更为有限。因此,提升正确答案的奖励值能够更有效地引导模型选择最优推理路径。
- 与偏好学习的结合
:奖励建模目标的改进也为偏好学习提供了更好的基础。通过提升正确答案的奖励,偏好学习算法能够更快、更准确地调整模型的推理路径,从而提高模型在复杂任务中的表现。
小结
EURUS-RM-7B在奖励建模任务中的表现证明了其在推理任务中的强大能力。通过RewardBench、AutoJ和MT-Bench等多个基准测试,EURUS-RM-7B展示了卓越的奖励建模效果,尤其是在推理任务中的表现甚至超过了GPT-4。此外,通过对模型生成的答案进行重排序,EURUS-RM-7B显著提升了代码生成和数学推理任务的准确率。最终,EURUS-RM-7B凭借新的奖励建模目标,进一步推动了开源模型在复杂推理任务中的发展,并成功成为开源领域中的顶尖奖励模型之一。
6. 分析 (Analysis)
在这一章节,作者对EURUS模型在推理任务中的表现进行了深入分析,特别是对偏好学习算法、奖励模式、以及模型训练中的设计选择进行了详细讨论。通过对实验结果和训练过程的深入剖析,作者提供了关于推理任务中偏好学习和奖励建模的关键洞见。

6.1 显式奖励作为偏好的代理?——推理任务中的偏好学习假设
这一部分探讨了偏好学习过程中不同算法的表现差异,特别是DPO(Direct Preference Optimization)、KTO(Knowledge-Theoretic Optimization)和NCA(Noise Contrastive Alignment)三种算法在推理任务中的应用效果。
- DPO在推理任务中的问题
:DPO是一个基于Bradley-Terry模型的偏好学习算法,主要优化不同答案之间的相对差异。尽管DPO在对话类任务中表现良好,但在推理任务中的效果较差,甚至会导致模型性能下降。作者指出,DPO忽略了绝对奖励值的提升,而这一点在推理任务中非常关键。
- 奖励趋势的影响
:作者通过实验发现,DPO在训练过程中,不仅未能有效提高正确答案的奖励值,反而导致了正确答案奖励值的下降。这种趋势对推理任务尤为不利,因为在推理过程中,正确答案空间相对较小,模型需要能够准确地识别并奖励正确的推理路径。因此,DPO算法虽然能够保持奖励差距,但并不能有效提升推理任务中的最终表现。
- KTO与NCA的优势
:相比之下,KTO和NCA在推理任务中表现显著优于DPO。这两种算法不仅优化了相对奖励差异,还成功提升了正确答案的绝对奖励值。在推理任务中,作者发现,奖励值越高,模型在推理任务中的表现越好。因此,KTO和NCA通过提升绝对奖励值,成功改善了推理任务的效果。
- 假设与结论
:作者假设,推理任务中的偏好学习不仅需要优化相对奖励差异,更需要通过显式的奖励建模来提升正确答案的奖励值。这一假设与实验结果相吻合,表明推理任务中更高的奖励值有助于提高模型的推理能力。因此,作者在EURUS模型中引入了增强的奖励建模目标,以提升偏好学习的效果。
6.2 消融研究
在这一部分,作者通过消融研究进一步分析了EURUS模型在推理任务中的表现,并研究了不同训练数据和方法对模型性能的影响。
- 不同数据集的影响
:作者对比了不同数据源对EURUS-7B模型的影响,特别是ULTRAINTERACT数据集与其他开源数据的作用。实验结果表明:
:ULTRAINTERACT数据集通过其设计的分解与交互模式,增强了模型在推理任务中的表现。这一发现与一些其他研究结论一致,即将复杂问题分解为多个步骤,并通过多回合交互进行解决,有助于提升模型的推理和问题解决能力。
- 增强的奖励建模目标
:消融实验还验证了奖励建模目标对模型性能的显著影响。通过对比不同奖励建模方法,作者证明了增强的奖励建模目标(LDR)在推理任务中比传统的Bradley-Terry模型更有效。特别是在推理任务中,直接优化奖励值的提升显著增强了模型的推理能力。
6.3 进一步的分析与结论
在最后的分析中,作者对EURUS模型的整体设计进行了回顾,得出了一些重要的结论:
- 奖励建模与偏好学习相结合的必要性
:在推理任务中,单纯的监督学习并不足以让模型达到最佳推理能力。通过结合偏好学习和奖励建模,EURUS模型能够在复杂推理任务中表现出色,特别是在多轮交互和复杂问题分解中,偏好学习和奖励建模相辅相成,提升了模型的推理路径选择能力。
- 多轮交互数据的重要性
:ULTRAINTERACT数据集中多轮交互的设计为模型提供了丰富的推理路径,这不仅提升了模型的推理能力,还增强了模型在多轮互动中的问题解决能力。与传统的单轮推理任务相比,多轮互动数据能够让模型学会从错误中修正,进而逐步优化答案。
- 推理任务中的算法选择
:通过分析KTO、NCA和DPO三种算法的表现,作者提出,推理任务中的偏好学习需要侧重于优化正确解答的绝对奖励值,而不仅仅是相对奖励差异。KTO和NCA在这方面表现良好,因此在未来的推理任务模型中,这类算法可能更具前景。
小结
本章节深入分析了EURUS模型在推理任务中的表现,重点讨论了奖励建模和偏好学习在推理任务中的重要性。通过对DPO、KTO和NCA算法的对比,作者提出了推理任务中特有的挑战,并指出显式奖励建模目标对推理能力的提升作用。消融研究进一步证明了ULTRAINTERACT数据集和增强奖励建模目标的有效性,这些设计使EURUS模型在复杂推理任务中成为开源模型的领先者。
7. 相关工作 (Related Work)
在这一章节,作者回顾了与EURUS模型相关的现有研究,涵盖了开源大语言模型在推理中的发展、推理任务中的偏好学习、以及复杂推理任务的模型对齐技术。通过回顾这些相关工作,作者展示了EURUS模型在推理任务中的创新点及其相对于现有模型的优势。
7.1 开源大语言模型在推理中的发展
近年来,开源大语言模型(LLMs)在各类推理任务中取得了显著进展,特别是在数学推理、代码生成等领域,一些专门为这些任务优化的开源模型表现出色。以下是一些典型研究的介绍:
- 数学推理模型
:有多个开源LLM专门针对数学推理任务进行了优化。例如,MAmmoTH-7B-Mistral和WizardMath-7B是通过大规模数学数据集进行微调的开源模型,它们在数学问题的解决上取得了不错的成绩。然而,这些模型虽然在特定领域表现出色,但在处理其他类型的推理任务时表现有限。
- 代码生成模型
:另一个推理领域的重点是代码生成任务,尤其是通过LLM自动生成和优化代码。诸如Magicoder-S-DS-6.7B、OpenCodeInterpreter(OpenCI)、以及CodeLLaMA等模型在代码生成任务中表现良好。然而,和数学推理模型一样,这些模型往往专注于某一类任务,在更广泛的推理任务(如多轮互动、逻辑推理)中表现有限。
- 通用推理模型的局限
:目前,开源模型在处理通用推理任务时面临挑战,虽然某些模型(如DeepSeek-LM-67B和QWen1.5-72B-Chat)在对话和某些推理任务上表现良好,但它们与最先进的专有模型(如GPT-4)之间仍存在显著差距。作者指出,现有的开源通用推理模型大多缺乏高质量的对齐数据和优化策略,无法充分应对复杂推理任务中的多样性和复杂性。
7.2 推理任务中的偏好学习
偏好学习(Preference Learning)近年来被广泛应用于模型的对齐和优化,尤其是在模型对用户需求进行调整时,它起到了重要作用。相关研究显示,通过引入人类或AI的偏好信息,偏好学习能够显著提高模型的输出质量。
- 对话中的偏好学习
:在开放领域对话模型中,偏好学习被证明能够有效提升模型的对齐效果。例如,Zephyr(Tunstall等,2023)和Qwen(Bai等,2023)通过偏好学习提高了模型在对话任务中的表现。这些模型使用了Direct Preference Optimization(DPO)等偏好学习方法,在对话任务中表现良好。
- 推理任务中的偏好学习不足
:然而,偏好学习在复杂推理任务中的应用还处于初期阶段。一些研究指出,传统的偏好学习算法(如DPO)虽然在开放式对话中表现出色,但在推理任务中并不适用。特别是,当推理任务需要复杂的规划和多步骤推理时,DPO的效果会显著下降。这是因为DPO只优化相对奖励差异,而忽略了推理任务中特有的绝对奖励值的重要性。
- 新型偏好学习算法
:近年来,针对推理任务的新型偏好学习算法得到了发展。例如,KTO(Ethayarajh等,2024)和NCA(Chen等,2024a)引入了新的优化目标,不仅关注相对奖励差异,还通过增强奖励建模提升了推理任务的表现。这类算法对推理路径的优化能力显著强于传统方法。EURUS通过结合这些先进的偏好学习方法,成功提高了模型在复杂推理任务中的能力。
7.3 复杂推理任务的模型对齐技术
模型对齐技术近年来也取得了显著进展,特别是在推理任务和多轮交互任务中的应用。以下是几项相关工作的回顾:
- 多轮交互推理
:一些研究提出,推理任务的复杂性不仅仅体现在单一的解答过程中,还包括了多轮互动和推理路径的规划。例如,MINT(Wang等,2023b)提出了一种新的基准,用于评估模型在多轮交互中的推理能力。这类基准测试不仅考察模型的初步解答能力,还评估模型在接收到环境反馈后的修正和优化能力。
- 工具使用与推理路径规划
:一些最新的研究尝试通过工具集成来增强模型的推理能力。例如,ToolLLM(Qin等,2023)和Creator(Qian等,2023)提出了通过工具创建和使用来解决复杂问题的策略。这类方法强调了模型在推理过程中如何使用外部工具来辅助解决问题,以及如何规划推理路径。这些技术为模型的推理能力提供了更多的灵活性,使其能够适应更加复杂的任务场景。
- 多回合交互数据集的必要性
:多回合交互和推理路径的分解被证明是提高模型推理能力的有效手段。Wang等(2024)提出,在复杂问题的解决过程中,模型需要学会如何根据环境反馈逐步调整推理路径,而不仅仅是生成一个最终答案。ULTRAINTERACT数据集正是基于这一理念设计的,它通过多回合交互数据,帮助模型逐步修正推理路径,最终得出正确答案。
小结
本章节回顾了与EURUS模型相关的多个研究领域,包括开源推理模型的进展、推理任务中的偏好学习,以及复杂推理任务的模型对齐技术。通过这些回顾,作者展示了EURUS模型相较于现有开源模型的创新之处,尤其是在高质量对齐数据、偏好学习优化和奖励建模方面,EURUS为开源推理模型的发展提供了新的思路和方法。
- EURUS通过结合ULTRAINTERACT数据集和新型偏好学习算法,弥补了现有模型在复杂推理任务中的不足。
- 现有研究虽然在特定领域取得了进展(如数学推理、代码生成),但在通用推理能力上仍有待提高,EURUS通过引入多轮交互和奖励建模技术,成功提升了模型的整体推理能力。
- 偏好学习在推理任务中的应用仍在发展,未来的研究可能会更多关注如何进一步优化推理路径和多回合交互,EURUS模型为这些领域提供了有价值的经验和成果。
参考文献
作者在这一章节引用了多个与推理任务、偏好学习和模型对齐技术相关的研究,展现了当前领域的前沿进展,同时为EURUS模型的发展提供了理论基础。
8. 结论 (Conclusion)
在论文的结论部分,作者总结了他们的工作,并强调了他们在缩小开源大语言模型(LLMs)与专有模型之间推理性能差距方面取得的进展。EURUS模型及其背后的ULTRAINTERACT数据集和偏好学习方法被认为是提升开源推理模型能力的关键创新。以下是结论部分的主要内容:
8.1 缩小开源模型与专有模型之间的性能差距
作者的主要目标是缩小开源LLMs与最先进的专有模型(如GPT-3.5和GPT-4)之间的推理性能差距。尽管开源模型在某些领域(如代码生成、数学推理)取得了一定的进展,但在处理复杂推理任务时,开源模型的整体性能仍远不如专有模型。通过EURUS模型及其相关技术,作者成功推动了开源模型在推理任务中的发展,并显著缩小了这一差距。
EURUS模型表现出强大的推理能力,特别是在数学、逻辑推理和代码生成等复杂任务上,EURUS-70B甚至达到了与GPT-3.5 Turbo相当的水平。这表明,通过高质量的对齐数据和偏好学习,开源模型可以在推理任务中取得重大进展,接近甚至赶超某些专有模型。
8.2 高质量的多轮推理对齐数据集ULTRAINTERACT
EURUS模型的成功主要归功于ULTRAINTERACT,这是一个专门为复杂推理任务设计的大规模、高质量数据集。ULTRAINTERACT的设计特点包括多轮交互、树状偏好结构、以及涵盖数学、代码生成和逻辑推理等任务的广泛数据。这些特点使得模型能够学习到如何在多轮交互中优化推理路径,逐步修正错误并得出正确解答。
ULTRAINTERACT不仅用于监督微调,还用于偏好学习,帮助模型识别正确的推理路径,并通过与环境和反馈的互动,逐步提升其推理能力。ULTRAINTERACT的多样性和复杂性为模型提供了丰富的学习信号,使得EURUS在复杂推理任务中表现出色。
8.3 EURUS系列LLMs的推出与效果
EURUS模型系列,包括EURUS-7B和EURUS-70B,是基于ULTRAINTERACT数据集微调和偏好学习的开源模型。这些模型在多个推理基准测试中取得了开源模型中的领先地位,特别是在代码生成和数学推理任务中表现尤为出色。
EURUS模型的核心优势在于其能够处理多轮交互、复杂推理任务,以及有效集成工具的能力。通过这些特性,EURUS模型在与其他开源模型的对比中显现出显著优势,尤其是其在推理任务中的表现大幅超过了其他同类模型。此外,EURUS-70B的性能甚至接近GPT-3.5 Turbo,这证明了该模型的先进性。
8.4 偏好学习的深入探索
作者还对现有的偏好学习技术进行了深入研究,发现了一些传统偏好学习算法(如DPO)在推理任务中的局限性。尽管DPO在对话任务中表现良好,但在推理任务中效果不佳,甚至会降低模型性能。基于这一发现,作者引入了KTO和NCA等更适合推理任务的偏好学习算法,并提出了一种增强的奖励建模目标,显著提升了模型在推理任务中的表现。
EURUS模型通过这些新的偏好学习方法和奖励建模目标,在推理任务中表现出更强的能力。作者的研究表明,推理任务中的偏好学习需要不仅优化相对奖励差异,还要显式提升正确解答的绝对奖励值,这对复杂推理任务尤为重要。
8.5 对开源推理模型的贡献
总的来说,作者认为他们的工作为开源推理模型的发展做出了重要贡献。通过引入ULTRAINTERACT数据集、EURUS模型系列和改进的偏好学习方法,作者显著提升了开源模型在推理任务中的能力,并缩小了与专有模型之间的性能差距。
EURUS模型的成功展示了高质量对齐数据和偏好学习技术的潜力,证明了开源模型可以在复杂推理任务中取得卓越表现。未来,随着更多高质量数据集和偏好学习方法的引入,开源模型在推理任务中的能力可能会进一步提升,甚至可能在多个领域超越专有模型。
8.6 未来工作展望
尽管EURUS模型取得了显著进展,作者也指出,未来仍有进一步发展的空间。首先,ULTRAINTERACT数据集尽管在推理任务上表现出色,但其在其他任务(如常规对话、跨领域推理)上的表现有待进一步探索。未来的工作可能需要扩展数据集的范围,涵盖更多类型的任务,以提升模型的全能性。
其次,尽管EURUS模型在推理任务中表现出色,但在更复杂的跨领域推理任务中可能仍存在挑战。未来的研究可以尝试引入更多类型的对齐数据和优化算法,进一步增强模型的跨领域推理能力。
最后,作者建议进一步研究偏好学习和奖励建模的优化策略,特别是在推理任务中的具体应用。通过深入探索不同类型推理任务中的偏好学习方法,未来的模型可能能够在推理过程中实现更高效的路径优化,从而提高整体性能。
小结
总结来说,作者在结论部分强调了他们通过EURUS模型和ULTRAINTERACT数据集,在开源推理模型领域取得的重大进展。他们成功提升了开源模型在复杂推理任务中的表现,缩小了与最先进专有模型之间的性能差距。通过引入高质量的对齐数据和新的偏好学习方法,EURUS为未来的开源推理模型发展提供了重要的启示和方向。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![OpenAIo1原理解读:通过想象、探索和批判实现法学硕士的自我提升[Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing]-AI论文](https://assh83.com/wp-content/uploads/2024/10/1-1-1-75x75.jpg)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)