本文介绍了一种自我对弈的相互推理方法 rStar,该方法无需微调或高级模型即可显著提高小型语言模型 (SLM) 的推理能力。rStar 将推理分解为自我对弈的相互生成-判别过程。首先,目标 SLM 使用一组丰富的类似人类的推理动作增强蒙特卡洛树搜索 (MCTS),以构建更高质量的推理轨迹。接下来,另一个具有与目标 SLM 类似功能的 SLM 充当鉴别器来验证目标 SLM 生成的每条轨迹。相互同意的推理轨迹被认为是相互一致的,因此更有可能是正确的。在五个 SLM 上进行的大量实验表明,rStar 可以有效解决各种推理问题,包括 GSM8K、GSM-Hard、MATH、SVAMP 和 StrategyQA。值得注意的是,rStar 将 LLaMA2-7B 的 GSM8K 准确率从 12.51% 提高到 63.91%,将 Mistral-7B 的准确率从 36.46% 提高到 81.88%,将 LLaMA3-8B-Instruct 的准确率从 74.53% 提高到 91.13%。代码可在此 https URL上获取。
摘要
- 引言
在引言部分,论文介绍了现有的大型语言模型(LLMs)在复杂推理任务中的挑战,例如当前顶尖模型在数据集GSM8K上的表现有限。论文引入了一种新方法——rStar,通过自我博弈和互相推理来提升小型语言模型(SLMs)的推理能力,而无需进行微调或依赖更强大的模型。这种方法的核心是将推理分解为生成-判别过程,通过两个SLMs的合作来增强推理准确度。
- 相关工作
本章探讨了目前推理语言模型的现状,重点介绍了如何通过提示增强推理能力的方法,例如“思维链”(Chain-of-Thought)。此外,作者还讨论了自我改进技术以及采样推理路径和答案验证等方法的最新研究进展。
- 方法论
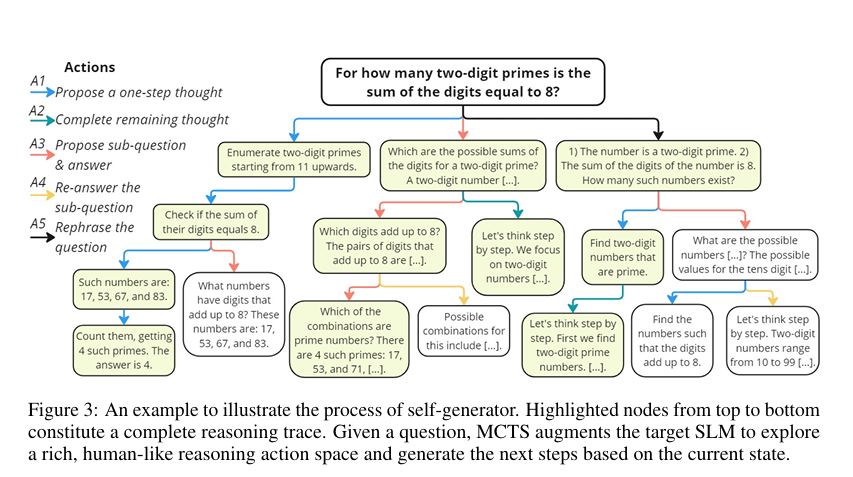
在该部分,论文详细介绍了rStar方法的机制。rStar将推理任务分解为多个子任务,每个子任务通过蒙特卡罗树搜索(MCTS)算法逐步生成。SLM通过执行多个类似人类推理的动作来生成高质量的推理路径,然后另一个SLM作为判别器,对生成的路径进行无监督反馈
- 实验
本章展示了该方法在多个推理数据集上的实验结果。rStar在五个不同的推理任务中大幅提升了SLM的推理表现。例如,rStar在GSM8K数据集上将LLaMA2-7B模型的准确率从12.51%提升至63.91%。
- 讨论
在该部分,作者对rStar方法的各个组件进行了详细的消融实验,验证了其生成器和判别器的有效性。并且进一步探讨了在不同推理任务中,rStar相较于现有方法的优势。
- 结论
论文总结了rStar的贡献,强调了该方法在不进行微调的情况下显著提升小型模型推理能力的潜力,并展示了它如何为未来的推理任务提供新思路。
引言
尽管大型语言模型(LLMs)在许多任务上取得了成功,但它们在处理复杂推理任务时仍面临重大挑战。例如,当前最先进的模型如Mistral-7B,即使使用“思维链”(Chain-of-Thought, CoT)技术,也只能在GSM8K数据集上达到36.5%的准确率(Jiang et al., 2023)。虽然微调被证明是一种有效的提升推理能力的方法,但大多数LLMs依赖于由更强大的模型(如GPT-4)提炼或合成的微调数据(Wang et al., 2024a; Gou et al., 2023)。然而,学术界也在积极研究一种互补且更具挑战性的途径:无需依赖更强大的教师LLM来提升推理能力。

一个有前途的改进推理的范式是利用LLM内部的知识(Wang et al., 2023; Hao et al., 2023; Madaan et al., 2024)。例如,RAP(Hao et al., 2023)采用了一种自我探索的解决方案,通过自我奖励的反馈来逐步提升LLM的推理性能。不幸的是,研究表明,这种范式通常会遇到两个根本性问题。
首先,LLM在推理过程中往往难以有效探索解空间。即使经过多次尝试,自动探索往往仍陷入低质量的推理步骤。例如,实验表明,使用RAP在GSM8K上自我探索32轮后,LLaMA2-7B生成的轨迹中只有24%是正确的。其次,即使自我探索能够找到高质量的推理步骤,SLM(小型语言模型)也难以判断哪些推理步骤质量较高,或者最终的答案是否正确,因此很难有效地指导自我探索。研究发现,简单的基于奖励的自我探索指导,往往其结果并不比随机猜测好(详见附录A.1)。
更麻烦的是,以上两个问题在小型版本的LLM中,即SLM中更为突出,因其能力较弱。例如,虽然GPT-4能够通过自我修正改进其输出(Madaan et al., 2024; Wu et al., 2024; Zhou et al., 2024),但这些方法在SLM中不太有效,甚至可能导致性能下降(Forsman, 2024)。这种现象大大阻碍了神经语言模型的推广和应用。
本文介绍了一种名为“自我博弈互相推理”(Self-play Mutual Reasoning,简称rStar)的方法,这种新方法可以在不进行微调或不依赖更强大的模型的情况下,提升SLM的推理能力。为了解决上述挑战,rStar将推理过程解耦为自我博弈的生成-判别过程,如图2所示。具体来说,rStar方法具有以下特点:
- 首先,虽然它依赖传统的蒙特卡罗树搜索(MCTS)来生成SLM的推理步骤,rStar主张在自我探索中加入更多模拟人类推理行为的新动作,如分解问题、提出新的子问题或重述问题。这种方式使得SLM在自我探索中能够生成高质量的候选推理轨迹。
- 其次,为了有效地引导对生成的推理轨迹的探索,rStar增强了MCTS流程,提出了一种新的判别机制,称为“互相一致性”。rStar使用一个具有相似能力的第二个SLM作为判别器,基于部分提示对每个候选推理轨迹进行无监督反馈,并通过判断两者是否达成一致来确认推理轨迹的质量。达成一致的推理轨迹被认为质量较高,从而更有可能是正确的。
广泛的实验表明,rStar可以显著提升SLM在各种推理任务中的性能。例如,在GSM8K上,rStar将LLaMA2-7B的准确率从12.51%提升至63.91%。这种方法不仅无需微调,而且匹配或超越了通过微调获得的性能提升。
方法论
本章详细介绍了rStar方法的原理和实施过程。rStar通过自我博弈和互相验证的方法,将推理问题分解为生成和判别两个主要过程,从而提高小型语言模型(SLMs)的推理能力。

问题的形式化
为了让SLMs解决推理问题,我们将推理问题定义为多步推理生成任务,即将问题分解为多个更简单的子任务。与传统的“思维链”(CoT)推理方法相比,这种方式更有效,因为对SLMs来说,逐步生成单一的推理步骤比在一次推理中生成完整的推理步骤更容易。我们采用蒙特卡罗树搜索(MCTS)算法来增强目标SLM的能力,使其能够自我生成多步推理解决方案。
形式上,对于一个给定问题 ( x ) 和一个目标SLM ( M ),MCTS将目标SLM与一个搜索树 ( T ) 结合起来逐步构建。根节点代表问题 ( x ),每条边代表一个动作 ( a ),每个子节点代表一个由SLM在相应动作下生成的中间步骤 ( s )。从根节点到叶节点(即终止节点,记为 ( s_d ))的一条路径构成了一个候选解决方案轨迹 ( t = x \oplus s_1 \oplus s_2 \oplus … \oplus s_d )。我们从搜索树 ( T ) 中提取出一组解决方案轨迹 ( T = {t_1, t_2, …, t_n} ),我们的目标是找到能为给定问题生成正确答案的轨迹。
SLM自我改进中的挑战
MCTS使SLMs能够探索并评估多个潜在的解决方案。理想情况下,SLM可以通过平衡新可能性的探索与高回报动作的利用,逐步优化其推理步骤,最终生成正确的推理轨迹。然而,SLMs的能力有限,传统的MCTS改进效果微乎其微。首先,巨大的解空间使得SLMs难以生成有效的解决方案。现有的MCTS方法(如Hao等,2023;Kang等,2024)采用单一动作类型,限制了其生成更好轨迹的有效性。尽管像自我一致性(Self-Consistency, SC)这样的随机采样方法保证了轨迹的多样性,但SLMs往往生成低质量的解决方案,需要多次尝试才能找到正确解,增加了推理成本。
其次,准确地对每个动作进行奖励也是一项挑战。没有真实标签的情况下,很难验证每个中间步骤 ( s_i ) 和最终答案是否正确。自我一致性中的多数投票要求大部分轨迹都是正确的,这对于SLMs来说往往难以实现。像RAP这样的方法使用自我奖励机制,但我们的研究表明,SLMs在自我奖励方面的表现近乎随机(详见附录A.1)。虽然训练奖励模型可以解决这个问题,但采集训练数据并推广到不同任务仍面临困难。
利用MCTS生成推理轨迹

MCTS生成的核心在于动作空间,它定义了树探索的范围。大多数MCTS方法使用单一动作类型来构建树。例如,在RAP中,动作是提出下一个子问题;而在AlphaMath(Chen等,2024a)和MindStar(Kang等,2024)中,动作是生成下一步推理步骤。然而,依赖单一动作类型容易导致探索空间的效率低下。
为了应对这一问题,我们借鉴了人类处理推理问题的方式。不同的人会使用不同的动作来解决问题:一些人会将问题分解为子问题,另一些人则会直接解决,还有一些人可能会重新表述问题以专注于关键条件。基于人类的推理过程,我们引入了一个包含五个动作的更丰富的动作集,以最大限度地发挥SLM在复杂推理问题上的潜力:
- A1:提出一个单步思考
- A2:提出剩余的思考步骤
- A3:提出下一个子问题并给出答案
- A4:再次回答子问题
- A5:重述问题或子问题

实验设置
模型与数据集
rStar方法适用于多种语言模型和推理任务。实验中评估了五个SLM,包括Phi3-mini、LLaMA2-7B、Mistral-7B、LLaMA3-8B等。测试的数据集包含了四个数学推理任务(GSM8K、GSM-Hard、MATH、SVAMP)和一个常识推理任务(StrategyQA)(2408.06195v1)。
实施细节
实验中,目标SLM通过rStar方法进行了32轮蒙特卡罗树搜索(MCTS)推理生成。所有任务的搜索深度为5(MATH数据集除外,深度为8)。判别阶段使用Phi3-mini-4k模型作为判别器,提供无监督的推理路径反馈。对于生成的每条推理轨迹,rStar随机分割其推理步骤,并将前一部分提供给判别模型,以完成剩余的步骤(2408.06195v1)。
主要结果
与基线模型的对比
rStar在各类推理任务中的表现优于现有方法,包括单轮推理(如Zero-shot CoT和Few-shot CoT)和多轮推理(如自我一致性和RAP)。例如,在GSM8K数据集上,rStar将LLaMA2-7B模型的准确率从12.51%提升到63.91%,显著高于其他自我改进方法(2408.06195v1)。
对不同推理任务的影响
rStar不仅在数学推理任务上表现出色,还在常识推理任务StrategyQA上展现了优异的性能。相比之下,其他方法在逻辑推理任务上的表现较差,尤其是自我一致性方法在多个数学任务中表现不错,但在StrategyQA上的效果不佳(2408.06195v1)。

消融实验
在不同轮次的效果
实验显示,即使在仅进行两轮推理时,rStar也能显著提高SLM的推理准确性。此外,随着推理轮次的增加,推理准确性逐渐提升(2408.06195v1)。
生成器与判别器的有效性
rStar的生成器和判别器都对推理性能提升起到了关键作用。消融实验表明,rStar的生成器比RAP和其他方法的生成器更加有效,而rStar的判别器在验证生成的推理路径时也优于其他方法,如多数投票和自我验证(2408.06195v1)。
总结
rStar通过自我博弈和互相验证的方法,大幅提升了SLM在推理任务中的性能。与现有的推理改进方法相比,rStar不仅适用于多种推理任务,而且无需微调模型即可取得显著的性能提升。这些实验结果表明,小型语言模型在推理任务中的潜力尚未被完全发掘。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)