0.摘要
这两天炸裂朋友圈的OpenAI 草莓大模型 o1 和此前代码能力大幅升级的Claude3.5,业内都猜测经过了自博弈(Self-play)强化学习。强化学习的自博弈方法的核心在于,能够通过自我对弈不断进化。《A Survey on Self-play Methods in Reinforcement Learning》这篇综述文章,将带我们深入了解自博弈方法的理论基础、关键技术以及在多样化场景下的应用实践。综述全面梳理了自博弈方法的研究进展,探讨其在模拟复杂决策过程中的作用,以及在未来发展中可能面临的挑战和机遇。 原文链接: https://arxiv.org/pdf/2408.01072
1. 引言 (Introduction)
自博弈是指智能体与自身的副本或过去版本进行交互的学习过程,最近在强化学习中得到了广泛关注。本文首先澄清了自博弈的相关基础,包括多智能体强化学习框架和基本的博弈论概念。随后提供了统一框架,并将现有的自博弈算法分类到这一框架中。此外,本文还通过展示自博弈在不同场景中的应用来弥合算法与实际应用之间的差距。最后,指出自博弈中的一些开放性问题以及未来的研究方向。该论文为理解自博弈在强化学习中的多样化前景提供了一个重要的指南。

2. 预备知识 (Preliminaries)
2.1 强化学习框架 (Reinforcement Learning Framework)
强化学习通过与环境的交互来优化决策过程,通常使用马尔可夫决策过程(MDP)进行建模。智能体通过观察状态、采取动作并根据奖励进行状态转换来学习最优策略。多智能体强化学习引入了更复杂的动态,尤其是在竞争环境下。自博弈通过智能体与自身或其过去版本进行互动,解决了多智能体环境中的一些难题,如非平稳性和协调问题。

2.2 博弈论概念 (Game Theory Concepts)
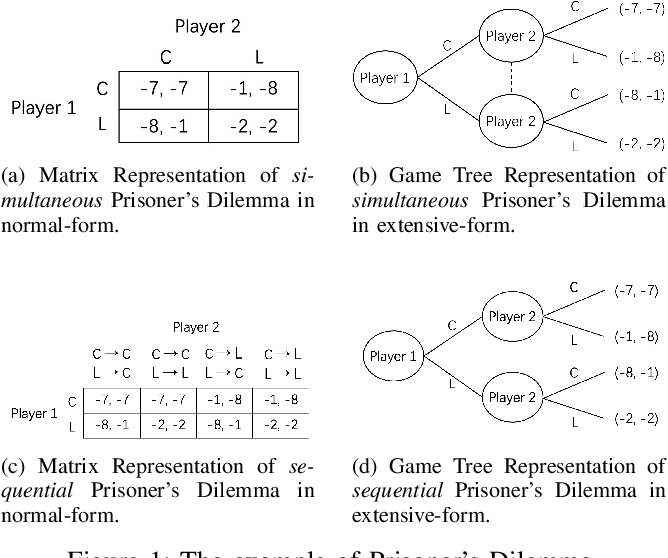
博弈论提供了多智能体互动的数学框架,涵盖了信息完备与不完备、博弈的标准形式与扩展形式,以及纳什均衡等重要概念。例如,围棋属于完美信息博弈,参与者对博弈状态和所有可能的动作有完全了解。纳什均衡用于描述在多个参与者相互博弈时,任何一方都无法通过单方面改变策略来提升自己的收益。
2.3 自博弈评估指标 (Evaluation Metrics in Self-play)
主要介绍了几种用于自博弈的评估指标,包括NASHCONV、Elo、Glicko、WHR和TrueSkill。这些指标可以帮助衡量策略的优劣,特别是NASHCONV,它用于衡量策略与纳什均衡之间的偏差。
3. 算法 (Algorithms)
3.1 框架定义 (Framework Definition)
该部分定义了自博弈的统一框架,并介绍了如何对政策人口进行更新、评估和对手采样策略。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![第3章:使用工具调用强制 JSON结构输出[以提取维基百科页面文章为例]-Claude工具调用教程](https://assh83.com/wp-content/uploads/2024/09/gower-5190799_1280-75x75.jpg)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)