
模型介绍
我们正在发布 OpenAI o1-mini,这是一种经济高效的推理模型。o1-mini 在 STEM 方面表现出色,尤其是数学和编码——在 AIME 和 Codeforces 等评估基准上的表现几乎与OpenAI o1相当。我们预计,对于需要推理而无需广泛世界知识的应用程序,o1-mini 将是一种更快、经济高效的模型。
今天,我们向5 级 API 用户推出 o1-mini(在新窗口中打开)成本比 OpenAI o1-preview 便宜 80%。ChatGPT Plus、Team、Enterprise 和 Edu 用户可以使用 o1-mini 作为 o1-preview 的替代方案,具有更高的速率限制和更低的延迟(参见模型速度)。
针对 STEM 推理进行优化
大型语言模型(例如 o1)是在大量文本数据集上进行预训练的。虽然这些高容量模型具有广泛的世界知识,但对于实际应用而言,它们可能成本高昂且速度缓慢。相比之下,o1-mini 是一个较小的模型,在预训练期间针对 STEM 推理进行了优化。在使用与 o1 相同的高计算强化学习 (RL) 管道进行训练后,o1-mini 在许多有用的推理任务上实现了相当的性能,同时成本效率显著提高。
在需要智能和推理的基准测试中,o1-mini 的表现优于 o1-preview 和 o1。然而,o1-mini 在需要非 STEM 事实知识的任务上表现较差(参见局限性)。
数学性能与推理成本
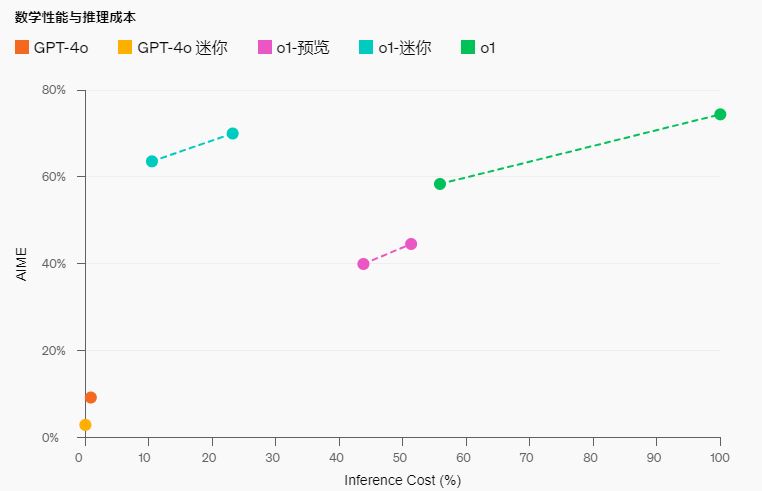
数学:在高中 AIME 数学竞赛中,o1-mini(70.0%)与 o1(74.4%)相当,同时价格便宜得多,且成绩优于 o1-preview(44.6%)。o1-mini 的得分(约 11/15 个问题)大约位列美国高中生前 500 名。
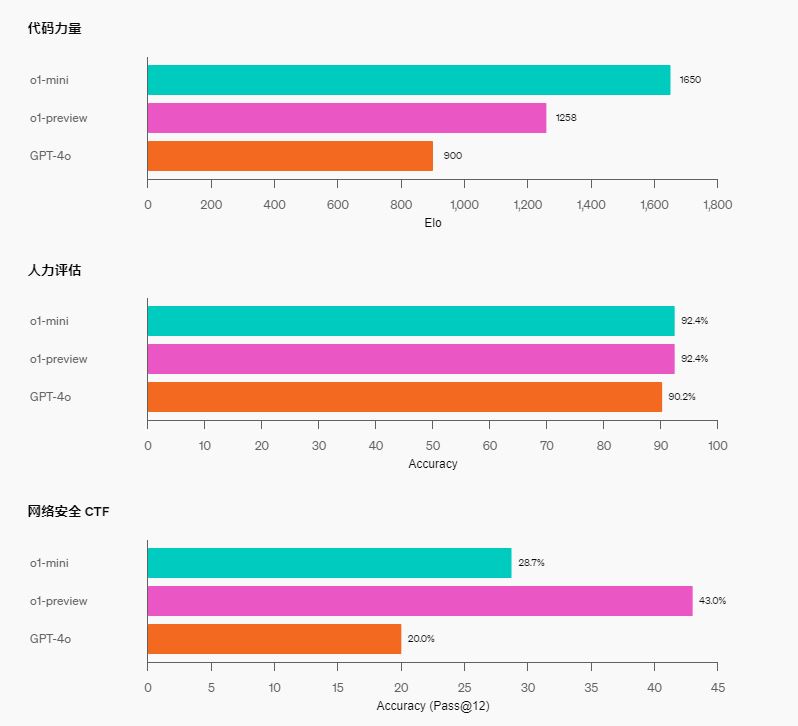
编码:在 Codeforces 竞赛网站上,o1-mini 的 Elo 得分为 1650,与 o1(1673)不相上下,且高于 o1-preview(1258)。这一 Elo 得分使该模型在 Codeforces 平台上竞争的程序员中处于第 86 个百分位左右。o1-mini 在 HumanEval 编码基准和高中级网络安全夺旗挑战赛 (CTF) 中也表现出色。
STEM:在一些需要推理的学术基准上,例如 GPQA(科学)和 MATH-500,o1-mini 的表现优于 GPT-4o。由于缺乏广泛的世界知识,o1-mini 在 MMLU 等任务上的表现不如 GPT-4o,在 GPQA 上落后于 o1-preview。
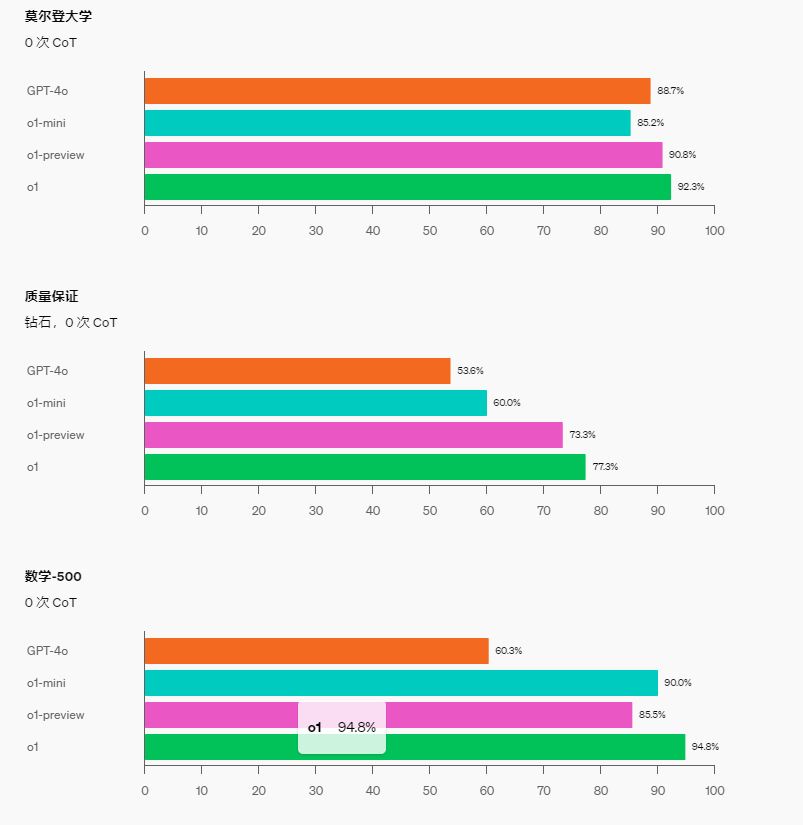
人类偏好评估:我们让人类评分员在各个领域具有挑战性的开放式提示上比较 o1-mini 和 GPT-4o,使用与o1-preview 与 GPT-4o 比较相同的方法。与 o1-preview 类似,在推理能力较强的领域,o1-mini 比 GPT-4o 更受欢迎,但在以语言为中心的领域,o1-mini 并不比 GPT-4o 更受欢迎。

模型速度
举一个具体的例子,我们比较了 GPT-4o、o1-mini 和 o1-preview 对一个单词推理问题的回答。虽然 GPT-4o 回答不正确,但 o1-mini 和 o1-preview 都回答正确,而且 o1-mini 得出答案的速度快了大约 3-5 倍。
安全
o1-mini 使用与 o1-preview 相同的对齐和安全技术进行训练。与 GPT-4o 相比,该模型在 StrongREJECT 数据集的内部版本上的越狱鲁棒性提高了 59%。在部署之前,我们仔细评估了 o1-mini 的安全风险,采用了与 o1-preview 相同的准备、外部红队和安全评估方法。我们将在随附的系统卡中发布这些评估的详细结果。
| 公制 | GPT-4o | o1-迷你 |
|---|---|---|
| % 有害提示下的安全完成拒绝率(标准) | 0.99 | 0.99 |
| % 有害提示的安全完成率(挑战:越狱和极端情况) | 0.714 | 0.932 |
| % 良性边缘情况的遵守情况(“不过分拒绝”) | 0.91 | 0.923 |
| Goodness@0.1 StrongREJECT 越狱评估 ( Souly 等人 2024(在新窗口中打开)) | 0.22 | 0.83 |
| 人工越狱评估 | 0.77 | 0.95 |
局限性和下一步
由于 o1-mini 专注于 STEM 推理能力,其关于日期、传记和琐事等非 STEM 主题的事实知识可与 GPT-4o mini 等小型 LLM 相媲美。我们将在未来版本中改进这些限制,并尝试将模型扩展到 STEM 之外的其他模态和专业。




![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)