这是关于调整开源大型语言模型 (LLM) 的三部分系列博文中的第一篇。在这篇文章中,我们将介绍将 LLM 调整为领域数据的各种可用方法。
介绍
大型语言模型 (LLM) 在众多语言任务和自然语言处理 (NLP)基准测试中表现出了卓越的能力。基于这些“通用”模型的产品用例正在不断增加。在这篇博文中,我们将为想要将 LLM 调整并集成到项目中的小型 AI 产品团队提供指导。让我们首先澄清有关 LLM 的(通常令人困惑的)术语,然后简要比较可用的不同调整方法,最后推荐一个分步流程图来确定适合您用例的正确方法。
大语言模型 (LLM) 微调方法
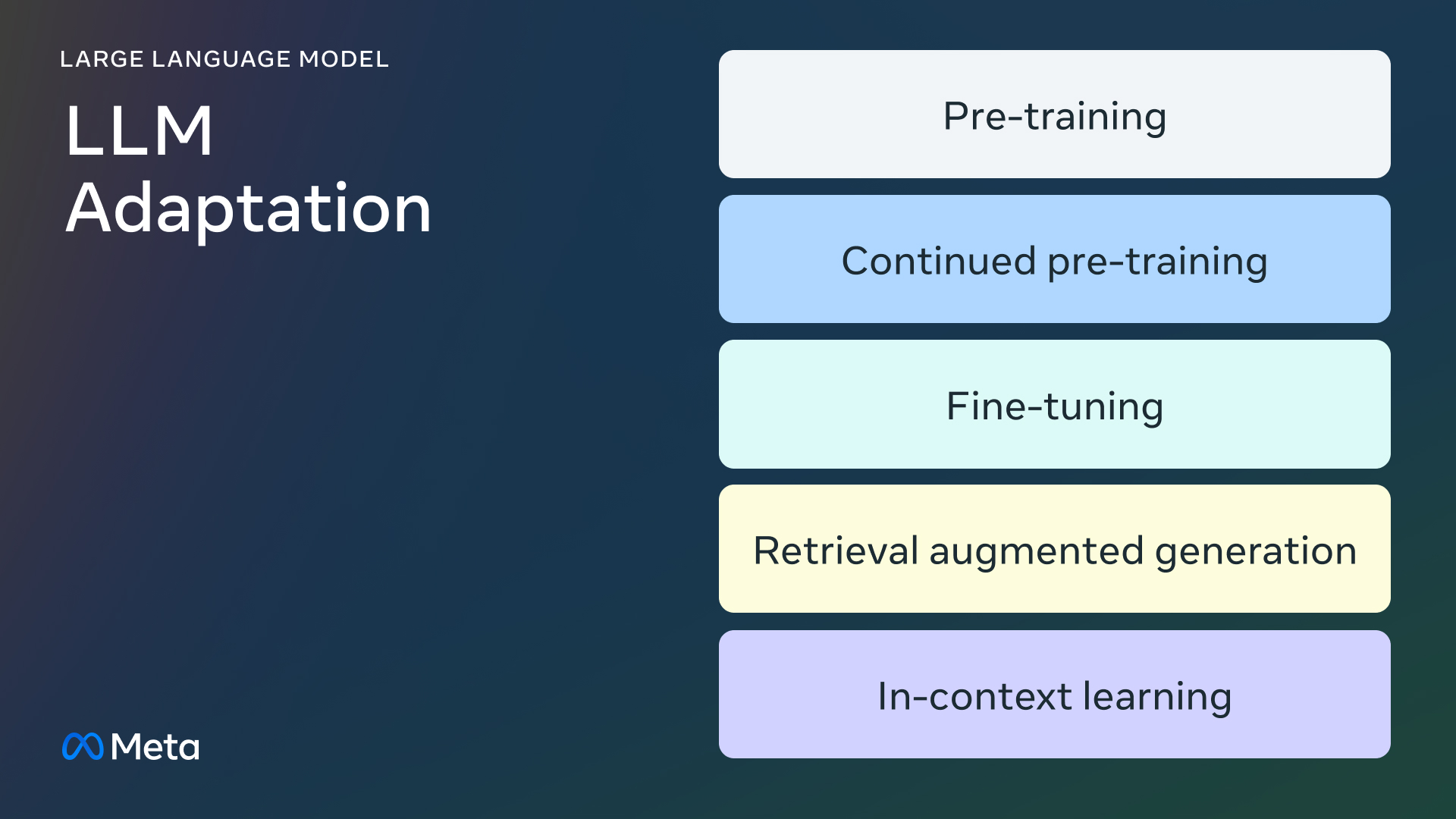
预训练
预训练是使用数万亿个数据标记从头开始训练 LLM 的过程。该模型使用自监督算法进行训练。最常见的是,训练通过自回归预测下一个标记(又称因果语言建模)进行。预训练通常需要数千个 GPU 小时(105 – 107 [源 1,源 2 ]])分布在多个 GPU 上。预训练的输出模型称为基础模型。
继续进行预训练
持续预训练(又称为第二阶段预训练)涉及使用新的、未见过的领域数据进一步训练基础模型。使用与初始预训练相同的自监督算法。通常涉及所有模型权重,并将原始数据的一小部分与新数据混合。
微调
微调是使用带注释的数据集以监督方式或使用基于强化学习的技术调整预训练语言模型的过程。与预训练相比,有两个主要区别:
- 对带注释的数据集(包含正确的标签/答案/偏好)进行监督训练,而不是自监督训练
- 需要更少的代币(数千或数百万,而不是预训练所需的数十亿或数万亿),其主要目的是增强指令遵循、人类协调、任务执行等能力。
可以从两个维度来了解当前的微调状况:改变的参数百分比和由于微调而增加的新功能。
参数改变的百分比
根据改变的参数数量,算法可分为两类:
- 完全微调:顾名思义,这包括改变模型的所有参数,包括对 XLMR 和 BERT 等小型模型(100 – 300M 个参数)进行的传统微调,以及对Llama 2、GPT3(1B+ 个参数)等大型模型进行微调。
- 参数高效微调(PEFT): PEFT 算法不会对所有 LLM 权重进行微调,而是仅微调少量附加参数或更新预训练参数的子集,通常占总参数的 1 – 6%。
添加到基础模型的功能
进行微调的目的是为预训练模型添加功能,例如:指令遵循、人体对齐等。Chat-tuned Llama 2 是一个经过微调的模型的例子,它增加了指令遵循和对齐功能。
检索增强生成 (RAG)
企业还可以通过添加特定领域的知识库来调整 LLM。RAG 本质上是“搜索驱动的 LLM 文本生成”。RAG 于 2020 年推出,它使用动态提示上下文,该上下文使用用户问题检索并注入 LLM 提示中,以引导它使用检索到的内容,而不是其预先训练的(可能已过时的)知识。Chat LangChain是一个流行的 Q/A 聊天机器人,它基于 LangChain 文档,由 RAG 提供支持。
情境学习(ICL)
使用 ICL,我们通过在提示中放置原型示例来调整 LLM。多项研究表明,“通过示例进行演示”是有效的。示例可以包含不同类型的信息:
还有多种其他修改提示的策略,并且“提示工程指南”包含全面的概述。
选择正确的微调方法
要确定上述哪种方法适合特定应用,您应该考虑各种因素:所追求任务所需的模型能力、训练成本、推理成本、数据集类型等。下面的流程图总结了我们的建议,以帮助您选择正确的 LLM 微调方法。

❌ 预训练
预训练是 LLM 训练的重要组成部分,它使用 token 预测变体作为损失函数。其自监督特性允许对大量数据进行训练。例如,Llama 2 是在 2 万亿个 token 上进行训练的。这需要大量的计算基础设施:Llama 2 70B 耗时1,720,320 GPU 小时。因此,对于资源有限的团队,我们不建议将预训练作为 LLM 适应的可行方法。
由于预训练在计算上过于昂贵,因此更新已经预训练过的模型的权重可能是使 LLM 适应特定任务的有效方法。任何更新预训练模型权重的方法都容易受到一种称为灾难性遗忘的现象的影响,该术语指的是模型忘记以前学到的技能和知识。例如,这项研究展示了在医学领域经过微调的模型在遵循指令和常见的 QA 任务方面的性能如何下降。其他研究也表明,通过预训练获得的一般知识可能会在后续的训练中被遗忘。例如,这项研究从领域知识、推理和阅读理解的角度提供了 LLM 中知识遗忘的一些证据。
❌ 持续预训练
考虑到灾难性遗忘,最近的发展表明,持续预训练 (CPT) 可以进一步提高性能,而计算成本仅为预训练的一小部分。CPT 对于那些需要 LLM 掌握新转换技能的任务大有裨益。例如,据报道,持续预训练在增加多语言能力方面取得了成功。
但 CPT 仍然是一个昂贵的过程,需要大量的数据和计算资源。例如,Pythia 套件经历了第二阶段的预训练,最终创建了FinPythia-6.9B。这个专为金融数据设计的模型使用包含 240 亿个 token 的数据集进行了 18 天的 CPT。此外,CPT 也容易发生灾难性遗忘。因此,对于资源有限的团队,我们不建议继续进行预训练作为 LLM 适应的可行方法。
总而言之,使用自监督算法和未注释的数据集来调整 LLM (就像在预训练和持续预训练中所做的那样)需要大量资源和成本,因此不建议作为一种可行的方法。
✅ 完全微调和参数高效微调(PEFT)
与使用未注释的数据集进行预训练相比,使用较小的带注释的数据集进行微调是一种更具成本效益的方法。通过将预训练模型调整为特定任务,微调模型已证明可以在广泛的应用和专业领域(例如法律、医疗或金融)中实现最佳结果。
微调,特别是参数高效微调 (PEFT),只需要预训练/持续预训练所需计算资源的一小部分。因此,对于资源有限的团队来说,这是一种可行的调整 LLM 的方法。在本系列的第 3 部分中,我们将深入探讨微调细节,包括完整微调、PEFT 以及如何进行微调的实用指南。
✅ 检索增强生成 (RAG)
RAG 是 LLM 适应的另一种流行方法。如果您的应用程序需要从动态知识库(例如 QA 机器人)中提取,RAG 可能是一个很好的解决方案。基于 RAG 的系统的复杂性主要在于检索引擎的实现。这种系统中的推理成本可能更昂贵,因为提示包括检索到的文档,并且大多数提供商使用按令牌计费的模型。在本系列的第 2 部分中,我们将更广泛地讨论 RAG 并提供与微调的比较。
✅ 情境学习(ICL)
这是采用 LLM 的最经济的方式。ICL 不需要任何额外的训练数据或计算资源,因此是一种经济高效的方法。但是,与 RAG 类似,推理的成本和延迟可能会随着推理时处理的标记增多而增加。
概括
创建基于 LLM 的系统是迭代的。我们建议从简单的方法开始,逐渐增加复杂性,直到实现目标。上面的流程图概述了这一迭代过程,并为您的 LLM 适应策略奠定了坚实的基础。
致谢
我们要感谢 Suraj Subramanian 和 Varun Vontimitta 对这篇博文的组织和准备提出的建设性反馈。
转载自:https://ai.meta.com/blog/adapting-large-language-models-llms/


![Llama Stack入门安装指南[结合Ollama]-AI大模型](https://assh83.com/wp-content/uploads/2024/09/3541422-0-82720500-1727389966-shutterstock_1175616652-100945248-orig-360x180.webp)


![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)