大型语言模型(LLMs)已经彻底改变了人工智能领域,并且已经成为许多任务的支柱。目前LLMs的成熟技术是在标记级别处理输入并生成输出。这与人类形成鲜明对比,人类在多个抽象层次上操作,远远超出单个单词,以分析信息并生成创造性内容。在本文中,我们提出了一种尝试性的架构,它基于一种明确的更高层次的语义表示进行操作,我们称之为“概念”。概念不区分语言和模态,代表了一个流程中的高层次想法或行动。因此,我们构建了一个“大型概念模型”。在本研究中,作为可行性的证明,我们假设一个概念对应于一个句子,并使用一个现有的句子嵌入空间——SONAR,该空间支持多达200种语言,涵盖文本和语音两种模态。
大型概念模型被训练以在嵌入空间中进行自回归句子预测。我们探索了多种方法,包括均方误差(MSE)回归、基于扩散的生成变体,以及在量化的SONAR空间中运作的模型。这些探索使用16亿参数的模型和大约1.3万亿标记的训练数据进行。然后我们将一种架构扩展到70亿参数的模型大小和约2.7万亿标记的训练数据。我们对几项生成任务进行了实验评估,包括摘要生成以及一项新的摘要扩展任务。最后,我们展示了我们的模型对许多语言展现出令人印象深刻的零样本泛化性能,超越了同规模现有的大型语言模型(LLM)
1.研究背景
- 研究问题:这篇文章要解决的问题是如何在高层次语义表示空间中进行语言建模,以超越现有的基于令牌级别的自然语言处理(NLP)模型。具体来说,作者提出了一种新的架构,称为“大型概念模型”(LCM),该模型在抽象的概念层次上进行推理和生成。
- 研究难点:该问题的研究难点包括:如何在高层次抽象空间中进行推理,如何实现跨语言和跨模态的可扩展性,以及如何在零样本情况下进行泛化。
- 相关工作:现有的语言模型(LLMs)大多基于Transformer架构,主要在令牌级别上进行操作。尽管LLMs在多项任务上取得了显著进展,但它们缺乏人类智能的关键特征,如显式的推理和规划。

2. 研究方法
这篇论文提出了“大型概念模型”(LCM)用于解决高层次语义表示空间中的语言建模问题。具体来说,
- 概念定义:首先,作者定义了“概念”作为高层次的抽象原子想法,通常对应于文本文档中的一句话或等效的语音表达。
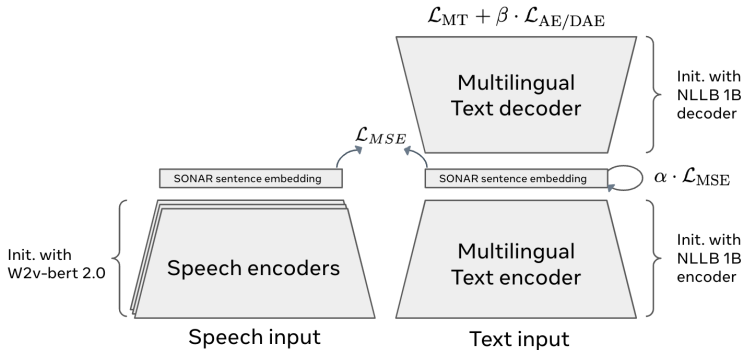
- 句子嵌入空间:LCM使用现有的句子嵌入空间SONAR,该空间支持多达200种语言的文本和语音输入输出。SONAR通过机器翻译、去噪自编码和显式的均方误差损失进行训练。

- 架构设计:LCM的输入首先被分割成句子,每个句子通过SONAR编码为一系列概念(即句子嵌入)。然后,这些概念序列通过LCM生成新的概念序列。最后,生成的概念序列通过SONAR解码为子词序列。LCM的编码器和解码器是固定的,不参与训练。
- 多种架构探索:LCM探索了多种架构,包括均方误差回归、基于扩散的生成变体和量化SONAR空间的模型。这些架构使用1.6B参数的模型和约1.3T令牌的训练数据。
- 扩散模型:扩散模型通过前向噪声过程和反向去噪过程进行生成。前向过程是一个高斯扩散过程,噪声调度函数将时间步映射到对数信噪比水平。反向过程是一个马尔可夫链,学习高斯转移。

3.量化模型:量化模型使用残差向量量化(RVQ)技术对SONAR表示进行离散化,然后在这些离散单元上进行建模。
3.实验设计
- 数据准备:使用SpaCy和Segment Any Text(SAT)工具对长文本进行句子分割,并使用AUTOBLEU评估分割质量。选择SAT Capped方法进行句子分割。

2.预训练:在FINEWEB-EDU数据集上预训练LCM模型,配置为约1.6B可训练参数,使用AdamW优化器和余弦学习率调度器。
3.指令微调:在COSMOPEDIA数据集上对LCM模型进行指令微调,使用ROUGE-L和一致性评分进行评估。
4. 结果与分析
- 预训练评估:扩散模型和量化LCM变体在ROUGE-L、ROUGE-L、ROUGE-L、ROUGE-L、ROUGE-L和ROUGE-L指标上表现相似,但BASE-LCM在这些指标上表现较差。
- 指令微调评估:在COSMOPEDIA数据集上,ONE-TOWER和TWO-TOWER模型的ROUGE-L得分分别为33.40和33.64,显著高于BASE-LCM的23.69。
- 噪声调度比较:宽的正弦噪声调度(δ=3.5, γ=0)在C4和WIKIPEDIA-EN数据集上表现出最高的对比度准确率(CA)。

4. 损失加权策略:与简化目标相比,夹紧信噪比加权策略并未显著提高生成文本的质量,但脆弱性感知加权策略提高了模型的对比度准确率。

5.推理效率:LCM在处理长上下文时表现出更好的可扩展性,其推理计算成本随上下文长度增加而增加。

5. 总体结论
本文提出的“大型概念模型”(LCM)在高层次语义表示空间中进行语言建模,展示了其在零样本情况下的优越泛化性能。LCM在多个生成任务上表现出色,特别是在长上下文和跨语言生成方面。尽管LCM在某些方面仍有改进空间,但其创新性的高层次抽象推理架构为未来的语言建模提供了新的方向。
6. 论文评价
优点与创新
- 高层次抽象:论文提出了一种新的架构,称为“大型概念模型”(LCM),它在高层次的语义表示空间中进行建模,而不是在离散的标记表示上。
- 语言和模态无关:LCM不特定于任何语言或模态,能够在所有支持的语言和模态上进行训练和推理。
- 显式层次结构:LCM具有显式的层次结构,使得长文本的输出更具可读性,并便于用户进行局部交互编辑。
- 处理长上下文和长文本输出:LCM能够处理比传统Transformer模型更长的上下文,并且在大规模数据上进行训练和推理时具有更好的可扩展性。
- 无与伦比的零样本泛化能力:LCM在未见过的语言和模态上也能表现出色,无需额外的数据或微调。
- 模块化和可扩展性:LCM的概念编码器和解码器可以独立开发和优化,新语言或模态可以轻松添加到现有系统中。
- 多种架构探索:论文探索了多种架构,包括基于扩散过程的LCM变体和量化LCM,展示了不同方法的有效性。
- 开源代码:为了促进研究,论文提供了LCM训练代码以及SONAR编码器和解码器的开源实现。
不足与反思
- 嵌入空间的选择:SONAR嵌入空间虽然具有多语言和多模态的良好表示能力,但其训练数据主要来自短句的双语机器翻译数据,这可能影响其在处理长文本和复杂句子时的性能。
- 概念粒度:将概念定义为句子级别存在挑战,因为可能的下一个句子的组合复杂性呈指数增长。未来的研究方向包括更细粒度的文本分割或多模态概念单元的构建。
- 连续与离散:扩散建模在处理连续数据(如图像或语音)方面非常有效,但在文本模态上仍面临挑战。未来可能需要开发更适合文本建模的新表示空间。
- 小规模建模误差:在小规模建模中,可能会出现无法解码为语法和语义正确的句子的预测误差。未来工作将探索更适合句子预测任务的概念嵌入。
- 大规模模型的训练:尽管LCM在7B参数模型上表现出色,但更大规模的模型(超过70B参数)仍需进一步研究和优化。
7. 关键问题及回答
问题1:LCM在实验中使用了哪些句子分割方法?这些方法的效果如何?
LCM在实验中使用了两种句子分割方法:SpaCy和Segment Any Text(SAT)。SpaCy是一个基于规则的多语言NLP工具包,提供了一种基于规则的方法来进行句子分割。SAT则提供了一套模型和适配器,能够在标记级别预测句子边界,特别适用于存在标点符号和首字母大写不规范的情况。实验结果表明,SAT在处理长句子和复杂句子时表现更好,尤其是在句子长度超过250个字符的情况下。为了进一步提高分割质量,实验中对两种方法进行了扩展,加入了最大句子长度的限制。最终,SAT Capped方法在所有句子长度上的平均Auto-BLEU得分略高于SPACy Capped方法,表明SAT在处理长句子和复杂句子时具有更好的鲁棒性。
问题2:LCM在扩散模型中使用了哪些噪声调度策略?这些策略的效果如何?
LCM在扩散模型中使用了三种噪声调度策略:余弦调度、二次调度和S型调度。余弦调度是最常用的调度方式,其特点是噪声水平随时间呈余弦变化。二次调度通过设定不同的方差值来实现噪声水平的线性增加。S型调度则通过一个S型函数来控制噪声水平的变化,具体参数为α和δ。实验结果表明,余弦调度在大多数情况下表现最佳,但在某些情况下,如S型调度(δ=3.5, γ=0)在对比度准确性(CA)上表现更好,尽管其在互信息(MI)上略逊于余弦调度。二次调度(Quadratic-2)在对比度准确性和互信息上表现介于余弦调度和S型调度之间。总体而言,不同的噪声调度策略在不同的任务和指标上有不同的表现,选择合适的调度策略对于模型性能至关重要。
问题3:LCM在长上下文摘要任务上的表现如何?与其他模型相比有何优势?
LCM在长上下文摘要任务上表现出色,特别是在生成更长、更连贯的摘要方面。实验结果显示,LCM在LCFO数据集上的ROUGE-L得分优于其他模型,特别是在5%和10%摘要长度条件下,LCM的ROUGE-L得分分别达到了26.88和29.38,接近GEMMA-7B-IT的29.25和42.85。此外,LCM在源归因(SH-4)和语义覆盖(SH-5)指标上也表现优异,表明其生成的摘要能够更好地反映源文档的内容。与其他模型相比,LCM的优势在于其能够在长上下文中保持较高的连贯性和一致性,同时在生成更长摘要时表现更好。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![MetaMorph: Multimodal Understanding and Generation via Instruction Tuning [元形态:通过指令调优实现多模态理解与生成]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-8-360x180.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)