
0 摘要
以往的语言模型预训练方法均统一地将下一个标记预测损失应用于所有训练标记。挑战这一规范,我们认为“语料库中的并非所有标记对语言模型训练同等重要”。我们的初步分析考察了语言模型的标记级训练动态,揭示了不同标记的不同损失模式。利用这些见解,我们引入了一种新的语言模型,称为RHO-1。与传统的LM学习在语料库中预测每个下一个标记不同,RHO-1采用选择性语言建模(SLM),它选择性地对与期望分布对齐的有用标记进行训练。这种方法涉及使用参考模型对标记进行评分,然后用针对得分较高的标记的集中损失来训练语言模型。在对15亿OpenWebMath语料库进行持续预训练后,RHO-1在9个数学任务中的少量样本准确率上实现了高达30%的绝对提升。经过微调后,RHO-1-1B和7B在MATH数据集上分别取得了40.6%和51.8%的最先进结果,仅用3%的预训练标记就与DeepSeekMath相匹配。此外,当在80亿个通用令牌上进行持续预训练时,RHO-1在15项不同的任务中实现了平均6.8%的增强效果,提高了语言模型预训练的数据效率和性能。
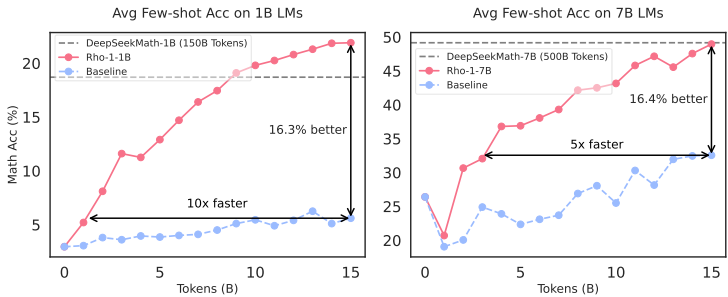
图1:我们持续预训练了1B和7B的大型语言模型(LM),使用了15B的OpenWebMath令牌。RHO-1使用我们提出的选择性语言建模(SLM)进行训练,而基线模型则使用因果语言建模进行训练。SLM在GSM8k和MATH上的平均少样本准确率提高了超过16%,实现了比基线快5-10倍的性能。

图2:上图:即使是经过广泛过滤的预训练语料库也包含词级噪声。左图:之前的因果语言建模(CLM)对所有词进行训练。右图:我们提出的选择性语言建模(SLM)选择性地对这些有用且干净的词应用损失。
1 引言
在大型语言模型中,提高下一个词预测准确率通常需要增加模型参数和数据集大小,这导致了人工智能领域的显著进步[Kaplan等人,2020年;Brown等人,2020年;OpenAI,2023年;Team等人,2023年]。然而,对所有可用数据进行训练并不总是最优或可行的。因此,数据过滤的做法变得至关重要,使用各种启发式和分类器[Brown等人,2020年;Wenzek等人,2019年]来选择训练文档。这些技术显著提高了数据质量并提升了模型性能。
然而,尽管进行了彻底的文档级过滤,高质量的数据集仍然包含许多噪声词,这可能会对训练产生负面影响,如图2(上图)所示。移除这样的词可能会改变文本的含义,而过于严格的过滤可能会排除有用数据[Welbl等人,2021年;Muennighoff等人,2024年]并导致偏见[Dodge等人,2021年;Longpre等人,2023年]。此外,研究表明,网络数据的分布并不自然地与下游应用的最佳分布对齐[Tay等人,2022年;Wettig等人,2023年]。例如,词级语料库可能包含不希望的内容,如幻觉或高度模糊的难以预测的词。将相同的损失应用于所有词可能会导致在非关键词上计算效率低下,可能会限制大型语言模型(LLMs)实现更高级别的智能。
为了探索语言模型如何在词级学习,我们最初检查了训练动态,特别是词级损失在常规预训练期间如何演变。在第2.1节中,我们评估了模型在不同检查点处的词困惑度,并将词分类到不同的类型。我们的发现揭示了显著的损失减少仅限于一组特定的词。许多词是“容易的词”,它们已经被学习过了,而有些是“困难的词”,它们表现出可变的损失并且难以收敛。这些词可能导致大量的无效梯度更新。
基于这些分析,我们引入了RHO-1模型,它们使用一种新颖的选择性语言建模(SLM)目标进行训练。如图2(右侧)所示,这种方法将完整序列输入模型,并选择性地移除不希望的词的损失。详细的流程如图4所示:首先,SLM在高质量语料库上训练一个参考语言模型。该模型建立效用指标来根据期望分布对词进行评分,自然地过滤掉不干净和不相关的词。其次,SLM使用参考模型使用其损失(2.2)对语料库中的每个词进行评分。最终,我们仅在那些在参考模型和训练模型之间表现出高超额损失的标记上训练语言模型,并选择性地学习对下游应用最有利的标记(§2.2)。
我们通过全面的实验表明,SLM显著提高了训练过程中的标记效率,并改善了下游任务的性能。此外,我们的发现表明SLM有效地识别了与目标分布相关的标记,从而提高了使用选定标记训练的模型的基准测试上的困惑度分数。§3.2展示了SLM在

图3:预训练期间四种类别的令牌损失。(a)显示了预训练期间H→H、L→H、H→L和L→L令牌的损失。(b)和(c)分别展示了预训练期间L→L和H→H的令牌损失波动情况。
数学持续预训练:1B和7B RHO-1在GSM8k和MATH数据集上均超过了CLM训练的基线,提高了超过16%。SLM达到了高达10倍的基线准确率,如图1所示。值得注意的是,RHO-1-7B仅使用15B令牌就与DeepSeekMath所需的500B令牌相比,达到了最先进的性能。经过微调后,RHO-1-1B和7B在MATH上的准确率分别为40.6%和51.8%。值得注意的是,RHO-1-1B是第一个达到40%准确率的1B LM,接近早期GPT-4的CoT性能42.5%。§3.3证实了SLM在一般持续预训练中的有效性:使用SLM在80B令牌上训练Tinyllama-1B,在15个基准测试中平均提高了6.8%,在代码和数学任务上取得了超过10%的收益。在§3.4中,我们展示了在没有高质量参考数据的情况下,我们可以使用SLM进行自引用,导致下游任务平均提高了高达3.3%。
2 选择性语言建模
2.1 并非所有令牌都是平等的:令牌损失的训练动态
我们的调查从标准预训练期间单个令牌损失如何演变的关键观察开始。我们继续使用OpenWebMath提供的15B令牌训练Tinyllama-1B,并在每1B令牌后保存检查点。然后我们使用大约32万个标记的验证集来评估这些间隔内的标记级损失。图3(a)揭示了一个显著的模式:标记根据它们的损失轨迹分为四个类别:高损失(H→H)、增加损失(L→H)、减少损失(H→L)和一致的低损失(L→L)。有关这些类别的更多细节,请参见&D.1。我们的分析发现,只有26%的标记显示出显著的损失减少(H→L),而大多数(51%)仍然处于L→L类别,表明它们已经被学习过。有趣的是,11%的标记持续具有挑战性(H→H),这可能是由于高随机不确定性[Hillermeier和Waegeman, 2021]。此外,12%的标记在训练期间经历了意外的损失增加(L→H)。
我们的第二个观察是,许多标记的损失表现出持续的波动,并且抵抗收敛。如图3(b)和(c)所示,许多L→L和H→H标记的损失在训练期间显示出高方差。在§D.2中,我们可视化和分析了这些标记的内容,并发现它们中的许多是嘈杂的,这与我们的假设一致。
因此,我们了解到,在训练期间每个标记相关的损失并不像整体损失那样平滑减少;相反,不同标记之间存在复杂的训练动态。如果我们能在训练期间选择合适的标记供模型关注,我们可能能够稳定模型的训练轨迹并提高其数据效率。
2.2 选择性语言建模
概述
受文档级过滤中参考模型实践的启发,我们提出了一种简单的词级数据选择流程,称为“选择性语言建模(SLM)”。我们的方法包括三个步骤,如图4所示。我们首先在策划的高质量数据集上训练一个参考模型。然后,该模型评估预训练语料库内每个词片的损失。在最后阶段,我们选择性训练语言模型,重点关注具有高

图4:选择性语言建模(SLM)的流程。SLM通过在预训练期间专注于有价值的、干净的标记来优化语言模型性能。它涉及三个步骤:(步骤1)首先,在高质量数据上训练一个参考模型。(步骤2)然后,使用参考模型对语料库中的每个标记的损失进行评分。(步骤3)最后,选择性地对得分较高的标记进行语言模型的训练。
训练模型和参考模型之间的损失过剩。直觉是,损失过剩高的标记更易学习,并且与期望分布更好地对齐,自然排除了那些要么不相关要么质量低的标记。下面,我们将为每一步提供详细的描述。
参考建模 我们首先整理一个高质量的数据集,以反映期望的数据分布。我们使用标准交叉熵损失在整理好的数据上训练一个参考模型(RM)。然后将得到的RM用于评估更大预训练语料库中的标记损失。我们根据RM分配给这个标记的概率计算标记xi的参考损失(LRM)。计算公式如下:
LRM(xi)=−logP(xi∣x<i)(1)
通过评估每个标记的LRM,我们建立了选择性预训练的参考损失,使我们能够专注于语言建模中最有影响力的标记。
选择性预训练请注意,因果语言建模(CLM)采用交叉熵损失:
LCLM(θ)=−N1i=1∑NlogP(xi∣x<i;θ)(2)
在这里,LCLM(θ) 代表由模型 θ 参数化的损失函数。N 是序列的长度,xi 是序列中的第 i 个标记,而 x<i 代表第 i 个标记之前的所有标记。相比之下,选择性语言建模(SLM)通过关注与参考模型相比表现出高超额损失的标记来训练语言模型。标记 xi 的超额损失 (LΔ) 定义为当前训练模型损失 (Lθ) 与参考损失之间的差异:
LΔ(xi)=Lθ(xi)−LRM(xi)(3)
我们引入了一个令牌选择比率k%,它根据它们的超额损失来确定要包含的令牌比例。选定令牌的交叉熵损失计算如下:
LSLM(θ)=−N∗k%1i=1∑NIk%(xi)⋅logP(xi∣x<i;θ)(4)
这里,N∗k% 定义了落在前k%个超额损失中的标记数量。指示函数Ik%(xi)定义为:
Ik%(xi)={10ifxi ranks in the topk% byS(xi)otherwise(5)
表1:数学预训练的少量样本共推理结果。所有模型都使用少量样本进行测试。之前的最佳结果用蓝色突出显示,而我们的最佳结果用紫色表示。*只计算与数学相关的唯一标记。对于RHO-1,我们只计算用于训练的选定标记。我们使用OpenAI的MATH子集[Lightman等人,2023]进行评估,因为一些原始测试样本已被用于PRM800k等公共训练集。SAT只有32个四选问题,所以如果有的话,我们将我们的结果平均到最后三个检查点上。
| Uniq. Train Model |0| Data Toks* Toks | Uniq. Train Model |0| Data Toks* Toks | Uniq. Train Model |0| Data Toks* Toks | Uniq. Train Model |0| Data Toks* Toks | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | GSM8K MATH+ SVAMP ASDiv MAWPS TAB MQA STEM MMLU SAT‡MMLU | AVG |
| 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models | 1-2B Base Models |
| Tinyllama | 1.1B | 2.9 | 3.2 | 11.0 | 18.1 | 20.4 | 12.5 | 14.6 | 16.1 | 21.9 | 13.4 | ||
| Phi-1.5 | 1.3B | 32.4 | 4.2 | 43.4 | 53.1 | 66.2 | 24.4 | 14.3 | 21.8 | 18.8 | 31.0 | ||
| Qwen1.5 | 1.8B | 36.1 | 6.8 | 48.5 | 63.6 | 79.0 | 29.2 | 25.1 | 31.3 | 40.6 | 40.0 | ||
| Gemma | 2.0B | 18.8 | 11.4 | 38.0 | 56.6 | 72.5 | 36.9 | 26.8 | 34.4 | 50.0 | 38.4 | ||
| DeepSeekLLM | 1.3B OWM | 14B | 150B | 11.5 | 8.9 | 29.6 | 31.3 | ||||||
| DeepSeekMath | 1.3B | 120B | 150B | 23.8 | 13.6 | 33.1 | 56.3 | ||||||
| Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B | Continual Continual Pretraining on Tinyllama-1B |
| Tinyllama-CT | 1.1B OWM | 14B | 15B | 6.4 | 2.4 | 21.7 | 36.7 | 47.7 | 17.9 | 13.9 | 23.0 | 25.0 | 21.6 |
| RHO-1-Math | 1.1B OWM | 14B | 9B | 29.8 | 14.0 | 49.2 | 61.4 | 79.8 | 25.8 | 30.4 | 24.7 | 28.1 | 38.1 |
| Δ | -40% | +23.4 | +11.6 | +27.5 | +24.7 | +32.1 | +7.9 | +16.5 | +1.7 | +3.1 | +16.5 | ||
| RHO-1-Math | 1.1B OWM | 14B | 30B | 36.2 | 15.6 | 52.1 | 67.0 | 83.9 | 29.0 | 32.5 | 23.3 | 28.1 | 40.9 |
| ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models | ≥ 7B Base Models |
| LLaMA-2 | 7B | 14.0 | 3.6 | 39.5 | 51.7 | 63.5 | 30.9 | 12.4 | 32.7 | 34.4 | 31.4 | ||
| Mistral | 7B | 41.2 | 11.6 | 64.7 | 68.5 | 87.5 | 52.9 | 33.0 | 49.5 | 59.4 | 52.0 | ||
| Minerva | 8B | 39B | 164B | 16.2 | 14.1 | 35.6 | |||||||
| Minerva | 62B | 39B | 109B | 52.4 | 27.6 | 53.9 | |||||||
| Minerva | 540B | 39B | 26B | 58.8 | 33.6 | 63.9 | |||||||
| LLemma | 7B PPile | 55B | 200B | 38.8 | 17.2 | 56.1 | 69.1 | 82.4 | 48.7 | 41.0 | 45.4 | 59.4 | 50.9 |
| LLemma | 34B PPile | 55B | 50B | 54.2 | 23.0 | 67.9 | 75.7 | 90.1 | 57.0 | 49.8 | 54.7 | 68.8 | 60.1 |
| Intern-Math | 7B | 31B | 125B | 41.8 | 14.4 | 61.6 | 66.8 | 83.7 | 50.0 | 57.3 | 24.8 | 37.5 | 48.7 |
| Intern-Math | 20B | 31B | 125B | 65.4 | 30.0 | 75.7 | 79.3 | 94.0 | 50.9 | 38.5 | 53.1 | 71.9 | 62.1 |
| DeepSeekMath | 7B | 120B | 500B | 64.1 | 34.2 | 74.0 | 83.9 | 92.4 | 63.4 | 62.4 | 56.4 | 84.4 | 68.4 |
| Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B | Continual Pretraining Mistral-7B |
| Mistral-CT | 7B OWM | 14B | 15B | 42.9 | 22.2 | 68.6 | 71.0 | 86.1 | 45.1 | 47.7 | 52.6 | 65.6 | 55.8 |
| RHO-1-Math | 7B OWM | 14B | 10.5B | 66.9 | 31.0 | 77.8 | 79.0 | 93.9 | 49.9 | 58.7 | 54.6 | 84.4 | 66.2 |
| Δ | -30% | +24.0 | +8.8 | +9.2 | +8.0 | +7.8 | +4.8 | +11.0 | +2.0 | +18.8 + | +10.4 |
默认情况下,我们使用 LΔ 作为得分函数S。这确保了损失仅应用于被认为是对语言模型学习最有益的标记。实际上,可以通过按照它们的超额损失对标记进行批量排名,并且只使用前 k% 的标记来进行训练来实现标记选择。这个过程消除了不需要的标记的损失,同时在预训练期间不会产生额外的成本,使我们的方法既高效又易于集成。
3 实验
我们在数学领域和一般领域不断预训练模型,并设计了消融和分析实验来理解SLM的有效性。
3.1 实验设置
参考模型训练为了训练我们的数学参考模型,我们收集了一个包含0.5B个高质量、与数学相关的标记的数据集。这个数据集是GPT[Yu等人,2024年,Huang等人,2024年]和手动策划的数据[Yue等人,2024年,Ni等人,2024年]的合成数据的混合体。对于一般参考模型,我们从开源数据集中编译了一个包含1.9B个标记的语料库,例如Tulu-v2[Ivison等人,2023年]和OpenHermes-2.5[Teknium,2023年]。我们对参考模型训练了3个周期。最大学习率分别设置为1B模型的5e-5和7B模型的1e-5,应用余弦衰减计划。我们将最大序列长度设置为1B模型的2048和7B模型的4096,将这些长度打包成多个样本用于模型输入。在所有主要实验中,我们用相同的基模型初始化了持续预训练模型和参考模型。
表2:数学预训练的工具集成推理结果。
| Model | Size | Tools | SFT Data | GSM8k | MATH | SVAMP | ASDiv | MAWPS | TAB | GSM-H | AVG |
| Used for SFT? | √ | √ | X | X | X | X | AVG | ||||
| Previous Models | Previous Models | Previous Models | Previous Models | Previous Models | Previous Models | Previous Models | Previous Models | Previous Models | Previous Models | Previous Models | Previous Models |
| GPT4-0314 | 92.0 | 42.5 | 93.1 | 91.3 | 97.6 | 67.1 | 64.7 | 78.3 | |||
| GPT4-0314(PAL) | 94.2 | 51.8 | 94.8 | 92.6 | 97.7 | 95.9 | 77.6 | 86.4 | |||
| MAMmoTH | 70B | MI-260k | 76.9 | 41.8 | 82.4 | ||||||
| ToRA | 7B | ToRA-69k | 68.8 | 40.1 | 68.2 | 73.9 | 88.8 | 42.4 | 54.6 | 62.4 | |
| ToRA | 70B | ToRA-69k | 84.3 | 49.7 | 82.7 | 86.8 | 93.8 | 74.0 | 67.2 | 76.9 | |
| DeepSeekMath | 7B | ToRA-69k | 79.8 | 52.0 | 80.1 | 87.1 | 93.8 | 85.8 | 63.1 | 77.4 | |
| Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models | Our Pretrained Models |
| TinyLlama-CT | 1B | √ | ToRA-69k | 51.4 | 38.4 | 53.4 | 66.7 | 81.7 | 20.5 | 42.8 | 50.7 |
| RHO-1-Math | 1B | √ | ToRA-69k | 59.4 | 40.6 | 60.7 | 74.2 | 88.6 | 26.7 | 48.1 | 56.9 |
| Δ | +8.0 | +2.2 | +7.3 | +7.5 | +6.9 | +6.2 | +5.3 | +6.2 | |||
| Mistral-CT | 7B | √ | ToRA-69k | 77.5 | 48.4 | 76.9 | 83.8 | 93.4 | 67.5 | 60.4 | 72.6 |
| RHO-1-Math | 7B | √ | ToRA-69k | 81.3 | 51.8 | 80.8 | 85.5 | 94.5 | 70.1 | 63.1 | 75.3 |
| Δ | +3.8 | +3.4 | +3.9 | +1.7 | +1.1 | +2.6 | +2.7 | +2.7 |
数学推理的预训练语料库,我们利用OpenWebMath(OWM)数据集[Paster等人,2023年],该数据集包含了来自Common Crawl中与数学相关的网页的大约140亿个标记。在一般领域,我们将SlimPajama[Daria等人,2023年]和StarCoderData[Li等人,2023a](均为Tinyllama语料库的一部分)与OpenWebMath结合使用,在总共800亿个标记上进行训练,混合比例为6:3:1。
数学预训练的预训练设置,我们继续对Tinyllama-1.1B模型[Zhang等人,2024年]和Mistral-7B模型[Jiang等人,2023年]进行预训练,学习率分别为8e-5和2e-5。对于1.1B模型,我们在32 x H100 80G GPU上进行训练。这种配置允许我们在大约3.5小时内训练大约150亿个标记,在大约12小时内训练500亿个标记。对于7B模型,在类似硬件条件下训练相同的150亿个标记大约需要18小时。对于一般领域,我们将Tinyllama-1.1B模型的学习率设置为1e-4,并在同一硬件条件下训练80B个标记,这大约需要19小时。批量大小统一设置为两个领域的100万个标记。关于标记选择比例,我们使用Tinyllama-1.1B模型为60%,Mistral-7B模型为70%。
基线设置 我们使用已经通过常规因果语言建模不断预训练的模型(Tinyllama-CT和Mistral-CT)作为基线。此外,我们将RHO-1与包括Gemma[Team等人,2024年]、Qwen1.5[Bai等人]在内的知名和表现最好的基线进行比较。在2023年,Phi-1.5[李等人,2023b]、DeepSeekLLM[DeepSeek-AI,2024]、DeepSeekMath[邵等人,2024]、CodeLlama[罗齐埃等人,2023]、Mistral[江等人,2023]、Minerva[卢科维奇等人,2022]、Tinyllama[张等人,2024]、LLemma[阿泽贝耶夫等人,2023]以及InternLM2-Math[应等人,2024]。对于微调结果,我们还与之前的最佳模型MAmmoTH[Yue等人,2024]和ToRA[Gou等人,2024]进行了比较。
评估设置为了全面评估预训练模型,我们比较了它们在各种任务上的少样本能力和微调性能。我们采用lm-eval-harness3[Gao等人,2023]进行一般任务,并为数学任务开发math评估套件4。我们使用vllm(v0.3.2)[Kwon等人,2023]来加速推理。关于我们评估的更多细节可以在附录E中找到。
3.2 数学预训练结果
少样本共推理结果 我们评估了基于少量样本思维链(CoT)[Wei等人,2022a]示例的基础模型,这些示例遵循以往的工作[Lewkowycz等人,2022,Azerbayev等人,2023,Shao等人,2024]。如表1所示,与直接进行连续预训练相比,RHO-1-Math在1B模型上实现了平均少样本准确率提高了16.5%,在7B模型上提高了10.4%。此外,在OpenWebMath上训练多个周期后,我们发现RHO-1可以将平均少样本准确率进一步提高到40.9%。与在500亿个数学相关令牌上预训练的DeepSeekMath-7B相比,RHO-1-7B仅在150亿个令牌上预训练(选择了10个)。在50亿个令牌中,我们取得了相当的结果,证明了我们的方法的效率。
工具集成的推理结果我们在69k ToRA语料库上微调了RHO-1和基线模型[顾等人,2024年],该语料库包含16k个GPT-4生成的轨迹,采用工具集成的推理格式,以及53k个使用LLama增强答案的样本。如表2所示,RHO-1-1B和RHO-1-7B在MATH数据集上分别达到了最先进的40.6%和51.8%。在某些未见过的任务(例如TabMWP和GSM-Hard)中,RHO-1也展示了一定的泛化能力,在RHO-1-Math-1B上的平均几轮准确率提高了6.2%,在RHO-1-Math-7B上提高了2.7%。

图5:一般预训练结果。我们在80GB通用令牌上持续预训练Tinyllama-1B。Tinyllama-CT使用CLM进行训练,而RHO-1则使用我们提出的SLM进行训练。
3.3 一般预训练结果
我们通过持续训练Tinyllama-1.1B在800亿令牌上确认了SLM在一般预训练中的有效性。图5中展示的结果表明,尽管Tinyllama已经在这些令牌上进行了广泛的训练,但与直接持续预训练相比,应用SLM在15个基准测试中的平均增强达到了6.8%。这种改进在代码和数学任务中尤为明显,超过了10倍。
3.4 自引用结果
在本节中,我们展示了仅使用预训练语料库就可以增强模型预训练的有效性,无需额外的高质量数据。具体来说,我们最初在OpenWebMath(OWM)语料库上训练了参考模型,这是Proof-Pile-2(PPile)的一个子集。我们使用训练好的参考模型评估了OWM和PPile,并选择了用于训练的令牌。在这种情况下,我们假设下游任务相关数据的缺失是常见的现实世界应用情况。我们假设关键因素不是评分期望分布,而是过滤掉噪声令牌。因此,我们采用了两种不同的评分函数,基于参考模型的损失LRM和下一个令牌的信息熵HRM,后者衡量下一个令牌的不确定性。详见附录H。
表3:自引用结果。我们使用OpenWebMath(OWM)来训练参考模型。
| Model | Score Function | Data | Uniq. Toks | Train Toks | GSM8K | MATH | SVAMP | ASDiv | MAWPS | MQA | AVG |
| Tinyllama-CT(RM) | OWM | 14B | 15B | 6.3 | 2.6 | 21.7 | 36.7 | 47.7 | 13.9 | 21.5 | |
| Tinyllama-SLM | OWM | 14B | 10.5B | 6.7 | 4.6 | 23.3 | 40.0 | 54.5 | 14.3 | 23.9 | |
| Tinyllama-SLM | HRM | OWM | 14B | 10.5B | 7.0 | 4.8 | 23.0 | 39.3 | 50.5 | 13.5 | 23.0 |
| Tinyllama-SLM | LRM\cap HRM | OWM | 14B | 9B | 7.1 | 5.0 | 23.5 | 41.2 | 53.8 | 18.0 | 24.8 |
| Tinyllama-CT | PPile | 55B | 52B | 8.0 | 6.6 | 23.8 | 41.0 | 54.7 | 14.2 | 24.7 | |
| Tinyllama-SLM | LRM\cap HRM | PPile | 55B | 36B | 8.6 | 8.4 | 24.4 | 43.6 | 57.9 | 16.1 | 26.5 |

图6:预训练损失和下游损失的动态。(a)和(c)分别代表了SLM在预训练期间,通过SLM和CLM方法选定的/未选定的令牌的损失,而(b)代表了SLM和CLM方法在MetaMath[Yu等人,2024]上的损失。我们通过总共40亿个令牌的预训练过程测试了上述结果。
实验结果显示,如表3所示,仅使用OWM训练的参考模型可以有效地指导模型在同一语料库上进行预训练,平均下游性能提高了+2.4%。仅使用信息熵作为得分函数也带来了类似的改进。此外,我们考虑了在两个得分函数选定的令牌的交集中进行训练,并发现更好的性能,令牌减少了40%,性能提高了+3.3%。此外,尽管仅使用OWM子集来训练参考模型,但SLM在PPile上进行训练仍然实现了1.8%的改进,使用的令牌减少了30%。更多细节,请参阅附录H。
3.5 清除研究与分析
选定的令牌损失与下游性能更吻合 我们利用参考模型来过滤令牌,并评估它们在训练后对验证和下游损失的影响。如图6所示,我们在4B个令牌上进行预训练,并跟踪了不同方法和验证集的损失变化。RHO-1在选定的令牌上的损失减少幅度大于常规预训练。交叉引用图(a)、(b)和(c)显示,选定的标记预训练显著降低了下游损失,而传统预训练对下游损失的影响虽然最初有所减少,但并不明显。因此,我们预期选择标记进行预训练更为高效。
在图7中,我们展示了选定的标记损失与下游任务性能的相关性,遵循类似于最近发现[Gadre等人,2024]的幂律。我们的分析表明,SLM选择的标记积极影响性能,而不选择的标记则有负面影响。因此,减少所有标记的损失对于提高模型性能并不是必要的。有关更多细节,请参阅附录F。
使用SLM选择了哪些标记?我们的目标是分析SLM方法在预训练期间选择的标记,以进一步探索其工作机制。为此,我们使用OpenWebMath可视化了RHO-1训练期间的标记选择过程。在§G.1中,我们用蓝色突出显示了在实际预训练期间保留的标记。我们观察到,大多数选定的标记
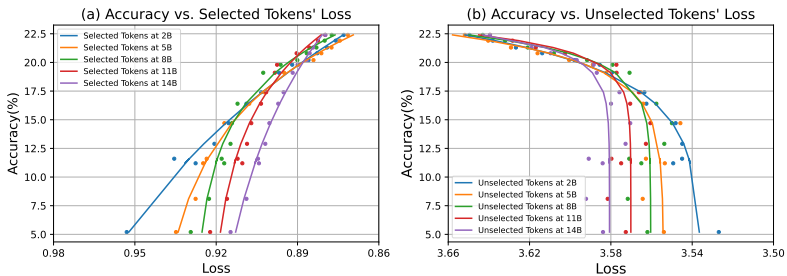
图7:SLM中选定的令牌/未选定的令牌损失与下游任务性能之间的关系。y轴代表GSM8k和MATH的平均少样本准确率。x轴代表相应检查点(2B、5B、8B、11B和14B)上选定的令牌/未选定的令牌的平均损失。

图8:不同检查点选定的令牌的PPL。我们测试了在2B、5B、8B、11B和14B选定的令牌的PPL。
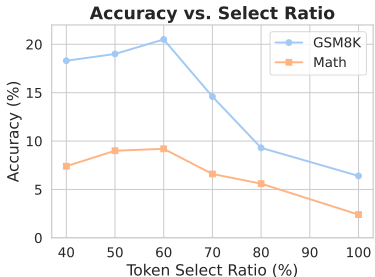
e 9:标记选择比率的影响。我们在5个B个标记上使用SLM目标训练1B个LM。
通过SLM方法与数学密切相关,有效地在原始语料库中与数学内容相关的部分对模型进行训练。
此外,我们研究了训练过程中不同检查点之间标记过滤的差异,并测试了这些标记在不同检查点的困惑度。如图8所示,我们发现后期检查点选择的标记在训练后期倾向于具有更高的困惑度,在前期则困惑度较低。这可能表明模型首先优化具有较大可学习空间的标记,从而提高学习效率。
此外,我们注意到在标记被选中的损失上存在逐样本的“双重下降”[Nakkiran等人,2021],其中选定标记的困惑度最初增加然后减少。这可能是基于超额损失的标记选择效应,针对每个检查点最需要标记的情况。
标记选择比率的影响 我们研究了SLM.Generally,选择比率由启发式规则定义,类似于之前在Masked Language Models(MLMs)训练中采用的方法[Devlin等人,2019年,Liu等人,2019年]。如图9所示,选定的标记适合解释原始标记的大约60%。
4 结论
在本文中,我们提出使用选择性语言建模(SLM)来训练RHO-1,该模型为当前预训练阶段选择更合适的令牌。我们对令牌在预训练过程中的损失进行了详细分析,并发现并非所有令牌在预训练期间都是相等的。我们在数学和一般领域的实验和分析已经证明了SLM方法的有效性,强调了令牌级别在LLM预训练过程中的重要性。未来,如何从令牌级别的角度改进LLMs的预训练,值得深入研究。
致谢
郑昊林和陈林得到了国家关键研发计划(项目编号:2022ZD0160501)、国家自然科学基金(项目编号:62372390、62432011)的支持。顾志斌和杨宇杰得到了深圳市科技计划(项目编号:JCYJ20220818101001004)和平安科技(深圳)有限公司“图神经网络项目”的支持。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)