0 摘要
图对比学习(GCL)作为一种生成图表示的方法,无需手动注释,已经崭露头角。大多数最先进的GCL方法可以分为三个主要框架:节点区分、群体区分和引导方案,所有这些方法都能达到相当的性能。然而,影响其有效性的底层机制和因素尚未完全理解。在本文中,我们重新审视这些框架,并揭示了一个共同机制——表示散射——显著提高了它们的性能。我们的发现突出了GCL的一个本质特征,并将这些看似不同的方法统一在表示散射的概念下。为了利用这一洞察,我们引入了散射图表示学习(SGRL),这是一个新的框架,它结合了一种新的表示散射机制,旨在通过中心-远离策略增强表示多样性。此外,考虑到图的互连性,我们开发了一种基于拓扑的约束机制,该机制将图的结构属性与表示散射结合起来,以防止过度散射。我们在基准数据集上对SGRL进行了广泛的下游任务评估,证明了其有效性和优越性,超过了现有的GCL方法。我们的发现强调了表示散射在GCL中的重要性,并提供了一个结构化的框架,用于利用这一机制来推进图表示学习。SGRL的代码可在https://github.com/hedongxiao-tju/SGRL上找到。
1 引言
图神经网络(GNNs)在社交网络[1, 2]、生物信息学[3, 4]和欺诈检测[5]等多个领域展示了令人印象深刻的表现。然而,训练GNNs通常需要具有手动标注标签的大型数据集,这既昂贵又劳动密集型[6]。这一限制限制了它们更广泛的应用。为了解决这一挑战,图对比学习(GCL)引起了显著关注[7,8,9,10],专注于从数据本身创建代理任务,以实现GNN编码器的自监督训练[11]。目前,大多数GCL研究[6, 12, 13]集中在增强三个主要框架之一:基于InfoNCE的方法(即节点区分)[14]、类似于DGI的方法(即群体区分)[7],以及类似于BGRL的方法(即引导方案)[10]。
这三个主流的图对比学习框架在处理节点级任务的方法上存在显著差异。基于InfoNCE的方法优先考虑节点级区分[8,9,12],将锚节点视为参考,同时将所有其他节点视为负样本,以增强每个节点表示的独特性。相比之下,类似于DGI的方法采用群体区分范式[6, 7, 15],将所有节点视为来自同一分布的正样本,并将它们与噪声分布区分开来。类似于BGRL的方法[10, 13, 16]采用引导方案,在训练期间消除了负样本的需求,转而专注于对齐正样本。尽管存在这些差异,所有三个框架都展示了相当的性能,这使我们推测它们可能共享一个共同机制。这一想法部分受到之前视觉对比学习研究的启发,这些研究将一致性作为许多对比学习方法的关键因素[17]。然而,一致性仅关注节点实例的判别属性,无法解释这些GCL框架之间共享的潜在因素,这一点在附录A中进一步讨论。
我们对这三个GCL框架进行了详细分析,发现表示散射是其成功的关键共同因素(在第3节)。在第3节中,我们提供了表示散射的正式定义,并检查了每个框架如何实现它。对于DGI框架,我们分析了原始数据和噪声数据的分布,证明了在GNN消息传递[18, 19]之后,噪声数据分布与原始数据的均值分布一致。这表明DGI的目标可以解释为区分原始图内节点的局部语义及其均值,这与表示散射相关联(第3.1节)。在InfoNCE框架中,现有工作已经证明负采样机制有助于实现一致性[17]。我们通过理论证明进一步扩展了这一点,即InfoNCE损失作为表示散射损失的上界(第3.2节)。关于BGRL框架,我们探讨了批量归一化[20]的作用及其与表示散射的联系,表明它作为这一概念的一个具体实例。值得注意的是,移除批量归一化显著降低了BGRL的性能(图2)。我们的发现证实,表示散射是所有三种主流GCL框架中都存在的关键机制。
然而,现有的GCL框架并没有充分利用它们设计中固有的潜在机制,并且在实施表示散射时忽略了图的相互联系性。这种疏忽导致了效率低下和鲁棒性的降低。首先,生成增强视图或计算节点对之间的相似性进行表示散射[7,8,9]会带来显著的计算和内存开销。其次,手动定义的负样本可能导致生成大量的假阴性样本,引入噪声[12],这可能会阻碍模型训练。最后,那些完全依赖正样本[10]的框架通过批量归一化间接实现表示散射,这缺乏明确的散射指导,并可能导致性能不佳。解决这些挑战对于提高GCL方法的效率至关重要。
为了充分有效地利用表示散射,我们提出了散射图表示学习(SGRL)。我们的方法引入了一种表示散射机制(RSM),它将节点表示嵌入到指定的超球体内,使它们远离平均中心。与现有的GCL框架相比,这种方法提供了一个直接的表示散射算法,消除了手动定义的负样本引入的偏差。此外,我们引入了一种基于拓扑的约束机制(TCM),它考虑了图的互连性质。TCM将结构信息派生的表示与散射表示对齐,从而在促进散射的同时保留拓扑信息。通过这些创新,我们旨在提高GCL方法的效率和鲁棒性。我们在本文中做出了以下贡献:
● 我们发现了GCLs中的一个共同表示散射机制,并展示了三个主流GCL框架隐含地利用了这种机制,重要的是可以在表示散射的概念下统一起来。
● 我们展示了现有方法没有充分利用表示散射的固有机制。我们引入了新的SGRL框架,将RSM和TCM整合在一起,产生了一种自适应的散射方法,用于模型训练。
● 我们在基准数据集上尝试了各种下游任务,并证明了SGRL的有效性和效率。
2 预备知识
图数据。我们将图定义为 G=(V,E),其中 V={v1,v2,…,vN} 表示节点集,E⊆V×V 代表边集。节点特征矩阵表示为 X∈RN×D,其中 N 是节点数,D 是特征维度。此外,邻接矩阵表示为 A∈RN×N,其公式为 Aij=1 当边 (vi,vj) 存在于集合 E 中,否则 Aij=。度矩阵表示为 D=diag(d1,d2,…,dN),其中每个元素 di=∑j∈VAij。带有自环的度归一化邻接矩阵表示为 Asym=D−1/2(A+I)D−1/2.
图对比学习。给定图的属性 X 和邻接矩阵 A,GCL 的目标是以自监督的方式训练一个编码器 f(⋅)。学习的编码器 f(⋅) 可以生成表示 H=f(X,A),H∈RN×K,它们都是拓扑解耦且密集的。这些表示可以应用于许多下游任务。
3.图对比学习中的表示散射
我们现在检查那些有助于流行图对比学习(GCL)框架有效性的共享元素。在重新审视三个广泛使用的基线GCL框架后,我们发现它们本质上都利用了表示散射机制,这在它们的成功中起着至关重要的作用。在这里,我们正式定义了表示散射:
定义1.(表示散射) 在一个包含n个向量组成的二维嵌入空间Rd中,考虑一个子空间Sk(1≤k≤d)在Rd中,并且有一个散射中心c。表示散射是一个过程,满足两个约束条件:(i) 中心-距离约束:鼓励节点表示与散射中心c保持一定距离;(ii) 均匀性约束:节点表示在子空间Sk上均匀分布。
根据定义1,要实现表示散射,需要识别出子空间Sk内的一个散射中心c,并同时满足中心-距离和均匀性约束。我们将在下一节中研究它与流行的GCL框架之间的关系。
3.1 类似于DGI的方法
类DGI方法通过随机排列节点来生成负样本。它们使用互信息鉴别器D(·),该鉴别器最大化节点及其源图之间的互信息来训练模型[6, 7, 15]。这里,我们展示了DGI的目标函数是表示散射的一个特例。为了便于证明,我们提出以下假设:
假设1.(a) 带归一化的传播矩阵A定义为A= D^{-1}\hat{A}, 其中\hat{A}=A+ I。(b) DGI通过在保持邻接矩阵A不变的情况下随机洗牌特征矩阵X中的实体来生成损坏的图。(c) 原始数据是类平衡的,即对于任何类别k和j,num(k)= num(j)。
以下结果并不严格要求假设1得到满足。假设1代表了一个常见的场景,并用于简化证明。关于假设1的有效性以及不带假设1的后续结果的证明,可以在附录C中找到。
定理1. 在节点级别上,最小化DGI损失等同于最大化原始图中的局部语义分布与其平均分布之间的Jensen-Shannon(JS)散度。
证明。设pdata表示原始图中所有节点的分布,其特征是均值μ和方差σ²。为了分析节点vi在通过GNN编码器进行嵌入聚合后的局部分布,我们定义pi为节点vi及其一阶邻居的分布,特征是均值μ和方差σ²。我们利用[6]中的一个结论,并引入以下引理:
引理2. 最小化DGI损失,记为L_DGI,等同于最大化原始图G的分布与损坏图tilde_G的分布之间的Jensen-Shannon(JS)散度,即Min(L_DGI)≡Max(JS(G∥tilde_G))。
我们在附录D.1中讨论了引理2。引理2建立了DGI损失与原始图和损坏图分布之间的关系。为了研究原始图和损坏图中表示的分布,我们关注单层GNN的情况,并有以下公式:
H=GNN(A,X)=A~XW′,hi=∑j∈Niαijxj⋅W′=∑j∈Nidi1xj⋅W′,(1)
其中 W′=ξ(W),W∈RD×K,ξ 是一个激活函数,如ReLU[22],以便于理解。Ni 表示节点 vi 的一阶邻居集合,包括 vi 本身。在方程1中,对于节点 vi,在GNN消息传递之后,我们按照以下方式计算聚合表示 hi 的均值和方差:
E[hi]=Ej∈N(i)∑αijxj⋅W′=j∈N(i)∑αijE[xj]⋅W′=j∈N(i)∑αijμi⋅W′,
Var(hi)=Varj∈N(i)∑αijxj⋅W′=j∈N(i)∑αijVar(xj)⋅W′2=σi2j∈N(i)∑αij2⋅W′2.
鉴于 A~ 是一个归一化传播矩阵,对于原始图中的聚合表示 hi,有 ∑j∈N(i)αij=1,表示 hi 的分布均值等于 μi⋅W′。然后我们分析受损图中聚合表示 h^i 的分布。根据假设1,邻接矩阵A保持不变,特征向量 x~i 是从原始图的特征矩阵X中随机选取的,遵循分布 pdata(μ,σ2)。根据方程2,h^i 分布的均值是 μ⋅W′,方差是 σ2∑j∈N(i)αij2⋅W′2。因此,我们有 hi∼pi′(μi⋅W′,σi2⋅W′2) 和 h^i∼pdata′(μ⋅W′,σ2⋅W′2),这直接证明了在节点级别最大化原始图和受损图分布之间的JS散度实际上最大化了节点 vi 的局部语义分布与原始图中节点的平均分布之间的JS散度。
推论3. 将原始图的均值作为中心c,原始表示空间作为一个子空间 Sk,DGI的目标可以是e 如下所述:在子空间Sk内,DGI增加了原始图节点与其中心c之间的距离,实现了表示散射的目标。
推论3首次揭示了,类DGI方法的主要目标是使节点表示远离中心点,以鼓励节点的均匀分布。为了说明这些理论上的洞察,我们进行了实验。如图1(a)和(b)所示,随机初始化的GNN和训练有素的单一图层GNN都证明了它们的训练表示与原始图节点的平均值相距较远。

ts,我们执行了一个vi,展示了扰动负样本的嵌入,ed点表示正节点的嵌入。如模型随机初始化和编码层的(a)和(b)所示,类GI(DGI)风格的方法本质上最大化了节点嵌入和嵌入均值之间的JS散度。
此外,图1(b)和(c)提供了更清晰的证据表明,最小化LDGI等同于最大化正负样本之间的Jensen-Shannon(JS)散度,即最大化原始图中局部语义分布与其均值分布之间的JS散度。然而,逐行洗牌机制可能会引入潜在的干扰。在一个有n个节点的图中,每个节点v在洗牌过程中保留其局部语义分布的概率为1/k,其中k表示不同节点类型的数量,假设类别平衡。尽管如此,扰动的非歧视性质意味着这些未改变的节点仍然可能被错误地分类为负样本。因此,真实的节点表示可能被错误地标记为负样本,导致学习过程中的偏差。图1中描绘的重叠节点直观支持这一观点。
3.2 基于InfoNCE的方法
我们现在展示,在基于InfoNCE的方法中,负采样的机制等同于表示散射。
定理4。设 hˉ=1/n∑i=1nhi,且 sim(⋅) 是余弦相似度函数(此处,hi 代表节点 vi 的编码表示)。对于节点 vi,InfoNCE 损失的下界 LInfoNCE(hi)≥sim(hi,hˉ)+ln(2n)。
详细证明见附录D.3。定理4表明,在最小化 LInfoNCE(hi) 时,节点 v 和平均节点 v,即 sim(h,h) 之间的相似性也被最小化。取所有节点的平均值作为散布中心 c,将超球面作为子空间 Sk,负采样机制等同于表示散布。然而,InfoNCE 损失函数对于表示散布效率低下,因为它需要计算并减少每对负样本的相似性。此外,它不加区分地处理所有负样本,忽略了它们之间的区别,这导致负样本的不适当散布和误报的潜在偏差。因此,许多最近的方法通过手动和直观定义正负样本而增加了额外的计算开销[12,23]。
类似 BGRL 方法
所有类似 BGRL 的方法都包含一个关键组件:批量归一化(BN)。对于特征向量 x 及其对应的批量统计量,均值μ 和方差o2,BN 应用如下:BN(xi)=γ(xi−μ)/σ2+ϵ+β,其中γ和β是可以学习的参数,它们会缩放和移动归一化值,ϵ是一个小的常数,用于数值稳定性。
定理5。通过批量归一化进行数据归一化的过程可以看作是表示散射的一个特例。
详细的证明可以在附录D.2中找到。为了实证评估批量归一化对BGRL的影响,我们比较了四个基准数据集上BGRL和BGRL无BN的情况进行了实验。结果显示在图2中,所有数据集的BGRL准确性都有显著下降,这突出了它在引导框架中的关键作用。虽然BGRL通过批量归一化纳入了表示散射,但其训练过程缺乏明确的指导或专门的机制来有效地管理这种散射。在表示散射阶段没有直接监督可能会导致嵌入空间内表示分布未优化,从而导致性能不佳。
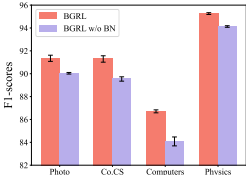
图2:批量正态的影响
总结来说,我们对三种主流GCL框架的分析理论上证明了它们都内在地利用了表示散射,但也未能完全利用这一有效机制。这一分析结果激励我们设计了一种更有效的表示散射方法,专门用于图上的学习。
4 方法论
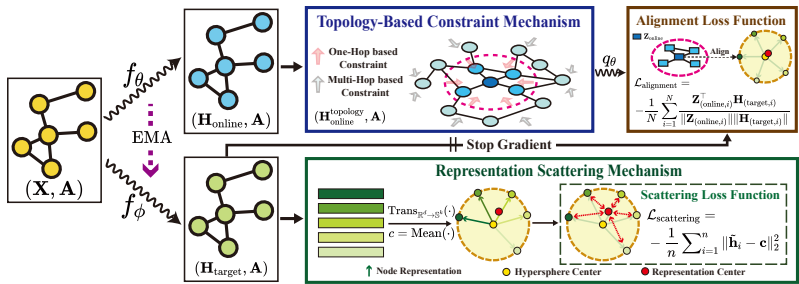
后续章节揭示了在GCL中表示散射的重要性。基于这些发现,我们设计了一种新颖的方法,即散射图表示学习(SGRL),简称为SGRL(见图3)。我们在以下子节中介绍了SGRL的组成部分,并提供了讨论。
4.1 表示散射机制(RSM)
为了解决在三种主流图对比学习框架内应用表示散射的不足,我们设计了RSM来明确指导目标编码器学习散射表示。根据定义1,我们引入了一个子空间Sk和一个散射空间。
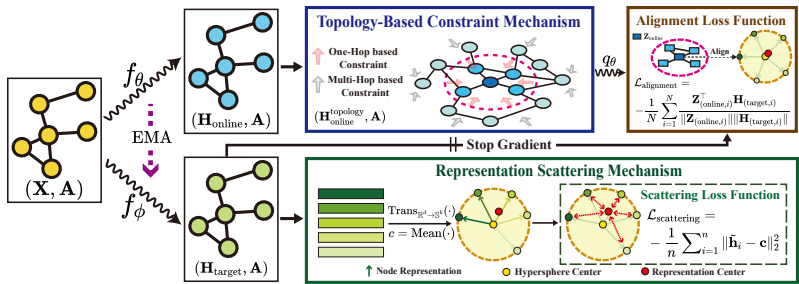
图3:SGRL概述。考虑一个使用两种不同编码器(在线编码器和目标编码器)处理的图G:fθ(⋅)带有参数θ,以及fϕ(⋅)带有ϕ,旨在分别生成节点表示Honline和Htarget。对于Htarget,计算所有节点的平均表示作为散布中心c。通过RSM更新fϕ(⋅)的参数,鼓励节点表示偏离c。在线性上,通过TCM处理以纳入拓扑信息,得到H拓扑。随后,通过预测器qθ嵌入Honlinetopology以预测Htarget,并通过在线反向传播更新fθ(⋅)中的参数,同时停止fϕ(⋅)的梯度。两个通道同时训练。在每个时期的结束时,我们采用指数移动平均(EMA)来更新参数ϕ。最后,通过fθ(⋅)生成的表示被用于各种下游任务。
中心c有效地执行表示散布。对于子空间Sk,引入了一个变换函数Trans(⋅)来转换原始空间Rd中的表示到Sk中。具体来说,我们对矩阵Htarget中的每一行向量hi应用ℓ2归一化:
h~i=TransRd→Sk(hi)=Max(∥hi∥2,ε)hi,Sk={h~i:∥h~i∥2=1},(3)
其中hi是目标编码器生成的节点vi∈V的表示,∥h~i∥2=(∑j=1kh~ij2)21,ϵ是一个小的值以避免除以零。如方程3所定义,所有节点的表示都分布在超球面Sk上。这种映射防止了在空间中任意散布表示,避免了训练过程中的不稳定性和优化困难。
接下来,我们定义散射中心c,并引入一个表示散射损失函数Lscattering在Sk中,以将节点表示从中心c推开,如下公式化:
Lscattering=−n1i=1∑n∥h~i−c∥22,c=n1i=1∑nh~i.(4)
通过方程4,SGRL在整个数据集中实现了表示的均匀性,而不强调局部均匀性。具体来说,RSM使得不同语义的表示能够在超球面上全局分散,同时容纳相同语义的表示在局部聚合。
RSM的讨论。我们现在提供一个理论分析,证明所提出的表示散射机制优于三种图对比学习框架。RSM通过鼓励节点表示与散射中心之间的距离来更有效地实现表示散射,消除了对手动设计的负样本的依赖。大多数传统方法[7,8,9,15]依赖于负样本来间接促进表示散射,这是低效的,并引入了偏差。如第3.1节所讨论的,类DGI的方法旨在最大化原始图的分布与其均值分布之间的Jensen-Shannon(JS)散度。基于此,生成额外的噪声图是低效的。此外,通过随机洗牌生成的某些负样本可能与正样本的分布对齐,导致产生阻碍模型训练的假阴性样本。InfoNCE基础方法将所有节点视为负样本,除了在两个增强视图中的匹配节点。虽然将节点相互推开可以确保每个节点的可区分性,但它也会导致显著的计算开销。此外,由于编码器的消息传递机制与InfoNCE损失函数之间的潜在冲突,许多负样本无法有效地彼此分离[24]。因此,通过采用中心-远离策略,
RSM有效地减少了额外的计算开销,并减轻了由手动设计的负样本引起的偏差。
4.2 基于拓扑的约束机制(TCM)
在通过目标编码器获得散布表示 Htarget=fϕ(A,X) 后,需要考虑不同节点表示的散布程度差异。
考虑图的互连性质,两个在拓扑上相连的节点表示在空间 Sk 中应该更接近。具体来说,对于 ∀vi,vj∈V,hi,hj∈Sk,给定一个阈值 d:∥hi−hj∥22<d,如果 (i,j)∈V 并且 ∥hi−hj∥22>d,如果 (i,j)∈/V。直观地说,为此目的,一种简单的方法是用一阶邻居的聚合表示 Htargettopology 替换单独散布的表示:Htargettopology=AHtarget。然而,尝试考虑拓扑信息并通过相同的编码器实现表示散布可能会导致冲突。
为了解决这个问题,我们提出了基于拓扑的约束机制(TCM)。具体来说,我们通过让在线编码器生成拓扑聚合表示而不是目标来分离约束过程和散射过程。在线编码器通过将原始表示Honline与其k阶邻居的拓扑聚合表示A^kHonline求和来增强其表示,这可以描述为:
Honlinetopology=A^kHonline+Honline,
其中k代表邻居的顺序,A^=A+I是带有自环的邻接矩阵。通过分离散射和约束,SGRL可以有效地在表示散射和拓扑聚合之间自适应地实现平衡,而不是经验性地设置散射距离。接下来,拓扑表示Honlinetopology被输入到预测器qθ(⋅)中,以生成预测表示Zonline=qθ(Honlinetopology)。我们的目标是使预测拓扑表示Zonline与散射表示Htarget紧密对齐,增强模型捕捉图的基本语义细节的有效性。基于此,对齐损失Lalignment定义如下:
Lalignment=−N1i=1∑NZ(online,i)H(target,i)Z(online,i)⊤H(target,i),(6)
其中 Z在线 和 H目标 分别代表预测和散射表示。在此过程中,在线编码器的参数 θ 被更新,目标编码器的参数 ϕ 停止梯度传播。与直接对齐受限和散射表示相比,这个预测目标可以作为一个缓冲区,允许在线编码器自适应学习散射表示和拓扑信息。此外,为了使目标编码器在表示散射的过程中考虑拓扑语义信息,而不仅仅关注散射,我们在每个训练周期结束时采用指数移动平均:
ϕ←τϕ+(1−τ)θ
其中 τ 是目标衰减率,τ∈[0,1]。方程7有效地缓解了RSM和TCM之间的对抗性相互作用,同时也促进了拓扑信息整合到表示散射过程中。此外,RSM增强了表示的可区分性,而TCM则将拓扑信息整合到表示中。这两种机制之间的相互作用有效地模仿了数据增强的作用,即训练编码器学习数据的不变性以应对扰动。因此,SGRL避免了显式设计数据增强策略的需要,这导致了额外的计算开销和对增强技术选择的严重依赖。
5 实验
我们在五个最广泛使用的基准数据集上评估了SGRL,包括Amazon-Photo(Photo)和Amazon-Computers(Computers)[25]、WikiCS[26]、Coauthor-CS(Co.CS)和Coauthor-Physics(Co.Physics)[27]。这些数据集的详细信息在附录B.2中。我们将SGRL与四种类型的方法进行了比较:(1) 三个主流基线:GRACE[8]、DGI[7]和BGRL[10]。(2) 六种最近先进的算法:GCA[9]、ProGCL[12]、AFGRL[13]、iGCL[28]、GBT[29]、MVGRL[15]。(3) 两种经典的图表示学习方法:Node2vec[30]和Deepwalk[31]。(4) 半监督训练基线GCN[18]。我们利用在线编码器生成的表示进行下游任务。对于节点分类,我们遵循[10]中的评估方案。我们仅使用逻辑回归损失(带有L2正则化和没有任何梯度反向传播到图编码器网络的表示)训练了一个简单的线性模型。具体来说,我们使用了10%的数据来训练下游分类器,并在剩余的90%数据上测试了分类器。我们运行了SGRL 20次,并在此报告F1分数的平均值和标准差。对于节点聚类,我们采用了[13]中的评估方法。测试是在每个时代学习的表示上进行的,最佳性能在下文报告。实验的更多细节可以在附录B中找到。
表1:节点分类的性能。OOM表示在24GB RTX 3090上的内存溢出。X,A,Y表示数据集中的节点属性、邻接矩阵和标签。最佳结果以粗体显示。
| Method | Available Data | WikiCS | Computers | Photo | Co.CS | Co.Physics |
| Raw Features | X | 71.98±0.00 | 73.81±0.00 | 78.53±0.00 | 90.37±0.00 | 93.58±0.00 |
| Node2vec | A | 71.79±0.05 | 84.39±0.08 | 89.67±0.12 | 85.08±0.03 | 91.19±0.04 |
| DeepWalk | 74.35±0.06 | 85.68±0.06 | 89.44±0.11 | 84.61±0.22 | 91.77±0.15 | |
| GRACE | X,A | 77.97±0.63 | 86.50±0.33 | 92.46±0.18 | 92.17±0.04 | OOM |
| DGI | X,A | 75.35±0.14 | 83.95±0.47 | 91.61±0.22 | 92.15±0.63 | 94.51±0.52 |
| BGRL | X,A | 76.86±0.74 | 89.69±0.37 | 93.07±0.38 | 92.59±0.14 | 95.48±0.08 |
| GBT | X,A | 76.65±0.62 | 88.14±0.33 | 92.63±0.44 | 92.95±0.17 | 95.07±0.17 |
| MVGRL | X,A | 77.52±0.08 | 87.52±0.11 | 91.74±0.07 | 92.11±0.12 | 95.33±0.03 |
| GCA | X,A | 77.94±0.67 | 87.32±0.50 | 92.39±0.33 | 92.84±0.15 | OOM |
| ProGCL | X,A | 78.45±0.04 | 89.55±0.16 | 93.64±0.13 | 93.67±0.12 | OOM |
| AFGRL | X,A | 77.62±0.49 | 89.88±0.33 | 93.22±0.28 | 93.27±0.17 | 95.69±0.10 |
| iGCL | X,A | 78.83±0.08 | 89.41±0.06 | 93.02±0.06 | 93.52±0.04 | 94.77±0.20 |
| SGRL(Ours) | X,A | 79.40±0.10 | 90.23±0.03 | 93.95±0.03 | 94.15±0.04 | 96.23±0.01 |
| Supervised GCN | X,A,Y | 77.19±0.12 | 86.51±0.54 | 92.42±0.22 | 93.03±0.31 | 95.65±0.16 |
5.1 性能分析
总体评估。表1展示了所有方法在节点分类任务上的F1分数和同型度的平均值和标准差。从原始论文或[13]中报告了一些现有方法的统计数据。如表所示,所提出的SGRL在测试的所有五个数据集上都表现出优越的性能,达到了最高的准确率。与三个基线BGRL、GRACE和DGI相比,我们的新方法分别提高了1.23%、2.14%和3.26%,显示出SGRL在更有效地利用表示散射方面的有效性。此外,我们观察到SGRL的表现优于像GCA、AFGRL和iGCL这样的方法,这些方法专注于改进数据增强。
图2:在NMI新颖性方面对聚类的性能。最佳结果以粗体显示,最差结果以下划线显示。
| GRACE | DGI | BGRL | SGRL | ||
| WikiCS | NMI | 0.4282 | 0.4312 | 0.3969 | 0.4188 |
| WikiCS | Hom. | 0.4423 | 0.4498 | 0.4156 | 0.4369 |
| Amazon-Computers | NMI | 0.4793 | 0.4630 | 0.5364 | 0.5380 |
| Amazon-Computers | Hom. | 0.5222 | 0.4836 | 0.5869 | 0.5705 |
| Amazon-Photo | NMI | 0.6513 | 0.5487 | 0.6841 | 0.6788 |
| Amazon-Photo | Hom. | 0.6657 | 0.5557 | 0.7004 | 0.6786 |
| Co-CS | NMI | 0.7562 | 0.7162 | 0.7732 | 0.7961 |
| Co-CS | Hom. | 0.7909 | 0.7428 | 0.8041 | 0.8216 |
| Co-Physics | NMI | OOM | 0.6540 | 0.5568 | 0.7232 |
| Co-Physics | Hom. | OOM | 0.6868 | 0.6018 | 0.7366 |
这证明了使用基于表示散射和拓扑聚合的图对比框架,而不是使用数据增强,可以有效地提高性能。SGRL还优于高级负采样方法ProGCL。我们将此归因于SGRL的表示散射,它没有明确定义负样本,从而比手动定义的负样本实现了更好的性能。在使用[13]方案评估节点聚类任务时,可以观察到SGRL在大多数数据集上都能达到最佳或第二好的准确率。尽管SGRL试图使节点表示分散,这似乎不适合聚类任务,但它仍然能够提供有竞争力的性能。这证明了TCM可以在表示散射过程中保留原始图的拓扑信息,确保在保持图结构的同时,不丢失任何拓扑信息。

图4:CS数据集中节点的t-SNE嵌入。
通过执行表示散射,它保持了节点的局部结构和全局语义一致性。
可视化。为了更直观地展示SGRL学习到的表示的优势,我们使用t-SNE[32]来可视化来自Co-CS数据集的学习到的表示。每个点代表一个节点,颜色表示节点的标签。如图4所示,SGRL与其他三种方法相比显示出更清晰的类别边界,表明RSM实现了更好的散射。此外,我们在SGRL中观察到更好的类内聚类。这突出显示了SGRL,它不需要手动定义的负样本,防止了类内节点的不适当距离。它实现了全局散射和局部语义聚合,证明了基于拓扑约束的自适应散射方法的有效性。
表3:节点分类的消融研究。最佳结果以粗体显示。
| Variant | WikiCS | Amazon-Computers | Amazon-Photo | Co-CS | Co-Physics |
| SGRL w/o RSM and TCM | 76.86±0.74 | 89.69±0.37 | 93.07±0.38 | 92.59±0.14 | 95.48±0.08 |
| SGRL w/o TCM | 78.55±0.08 | 89.54±0.10 | 93.58±0.05 | 94.08±0.03 | 96.19±0.04 |
| SGRL w/o EMA | 79.36±0.08 | 90.03±0.07 | 93.92±0.02 | 93.89±0.07 | 96.16±0.07 |
| SGRL(Ours) | 79.40±0.13 | 90.23±0.03 | 93.95±0.03 | 94.15±0.04 | 96.23±0.01 |
5.2 模型分析
超参数分析。在本小节中,我们研究了SGRL中超参数k的敏感性,如方程5所示。参数k代表聚合邻居的数量级,直接影响拓扑约束的强度。在我们的实验中,我们将k调整在0,1,2,···,7的范围内,以评估不同约束强度对SGRL的影响。结果显示在图5中:当k= 0时,即“无TCM的SGRL”,缺乏拓扑约束会导致模型性能下降。随着k的增加,TCM的约束能力逐渐增强,模型性能对于k的变化表现出单峰形状。这表明弱拓扑无法保持足够的拓扑信息用于自适应表示散射,而强拓扑则可以。
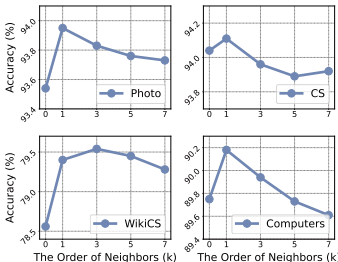
图5:k拓扑的超参数分析可能会过度限制表示的散射,这与第3节和第4节提出的观点一致。
消融研究。为了验证SGRL每个组件的有效性,我们对五个数据集进行了消融研究。如表3所示,“无TCM和有TCM的SGRL”在四个数据集上展示了显著的性能提升,仅添加RSM时,即“无TCM的SGRL”,证实了其有效性。我们观察到,在计算机数据集上性能略有下降,我们认为这是由于表示散射期间缺乏约束导致的过度散射。此外,SGRL与“无TCM的SGRL”的比较显示,SGRL在所有五个数据集上都实现了提高的准确性,特别是在计算机数据集上。这表明TCM有效地限制了散射,实现了自适应表示散射,验证了我们第4.2节的观点。最后,我们对EMA进行了消融研究。鉴于RSM和TCM之间的潜在对抗关系,我们采用了EMA来平衡这种效应。表3中的实验结果突出了整合EMA以减轻RSM和TCM之间对抗性相互作用的必要性。
6 结论
在本文中,我们对图对比学习(GCL)做出了两个重大贡献,这是一个活跃研究的主题,在多个领域都有众多应用。首先,通过对三种流行的GCL框架的全面分析,我们发现了一个共同的潜在机制——表示散射——这是这些不同对比方法的基础。这一发现突出了GCL的一个本质特征,并在表示散射的概念下统一了这些看似不同的框架。尽管这些方法很受欢迎,但现有的方法并没有充分利用这一机制,留下了表示散射的潜力尚未充分发挥。
然而,直接将表示散射应用于GCL提出了技术挑战。我们的第二个贡献通过引入表示散射机制(RSM)和基于拓扑的约束机制(TCM),解决了这个问题,并将其整合到一种名为散射图表示学习(SGRL)的新型GCL方法中。在SGRL中,我们有效地使用指数移动平均(EMA)策略平衡了RSM和TCM之间的对抗关系。在基准数据集上的广泛实验结果验证了我们提出方法的有效性。未来的工作将进一步探索表示散射超出GCL的更广泛含义,这些内容在附录F和G中讨论。
致谢
本项工作得到了国家自然科学基金(项目编号:62422210、U22B2036、62276187)、国家杰出青年科学基金(项目编号:62276187)的支持。62025602)、XPLORER奖、香港RGC主题战略目标基金(STG1/M-501/23-N)、香港全球STEM教授计划和香港赛马会慈善信托

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![NeurIPS2024:Not All Tokens Are What You Need for Pretraining[并非所有token都是你进行预训练所需要的]-AI论文](https://assh83.com/wp-content/uploads/2024/12/image-21-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)