1. Introduction
在本章中,论文介绍了当前AI领域的一个重要趋势,即通过增加模型参数、数据集规模和计算量来提升人工智能模型的性能。特别是在机器人、电子游戏等领域,研究人员发现,通过对离线数据集的生成学习目标(即预训练)来进行模仿学习(模仿人类行为)或构建世界模型,可以显著提升具身智能体的表现。

主要研究背景
近年来,AI的发展在很大程度上依赖于扩大模型规模和训练数据集的规模。这种“更大即更好”的方法促进了深度学习的进步,并逐渐催生了一个新的研究子领域——扩展科学(Scaling Science)。扩展科学关注于:
- 增加计算投资带来的收益:即随着计算资源的投入增加,模型的性能将如何提升。
- 模型和数据集规模的平衡:研究如何在固定的计算资源下,合理地分配模型规模与数据量,以获得最佳效果。
在大语言模型(LLMs)中,研究者已经发现,损失函数与关键扩展因素之间的关系可以用幂律关系精确描述。例如,Kaplan等人(2020)发现模型损失与最优模型大小之间存在幂律关系。随后,更多研究关注在模型规模和数据集规模之间的权衡,例如Hoffmann等人(2022)提出的结论显示模型和数据集规模应按比例增长,以达到最佳效果。而在推理计算方面(例如如何在推理过程中合理控制计算量),Sardana和Frankle(2023)也进行了详细分析。
扩展法则在具身AI领域的应用
相比之下,具身AI的扩展法则研究尚未取得与LLMs相同的进展。最近的研究表明,在模仿学习和世界建模的任务中,增大模型和数据集规模可以使智能体变得更为强大,但大多数研究只是在不同的模型大小上做了一些消融实验来展示规模的优势,而没有更精确地探讨扩展规律。
为弥补这一不足,本论文试图在具身AI领域中进一步研究扩展法则,重点关注两个预训练目标:
- 行为克隆(Behavior Cloning,BC):基于离线数据集预测人类的行为,以便直接生成一个可执行的策略。
- 世界建模(World Modeling,WM):通过预测环境的状态变化来构建世界模型,使智能体能够对环境有更深刻的理解,进而用于规划或决策。
研究目标与贡献
本研究的目标是探索规模对这两个预训练任务的影响,进一步揭示与大语言模型相似的幂律规律在世界建模和模仿学习中的出现。研究还发现,模型扩展的最佳系数会受到分词器、任务类型和架构的影响,这对于在具身AI中确定模型与数据集的最佳比例具有重要意义。
总结来说,本论文的贡献在于:
- 发现与LLMs中相似的扩展法则也适用于具身AI中的世界建模任务。
- 阐明了在不同分词压缩率和架构下,模型和数据集的最佳平衡关系,这为具身AI的模型和数据集设计提供了理论依据。
2. Related Work
本章综述了扩展法则(Scaling Laws)研究的起源与发展,重点介绍了在大语言模型(LLMs)、实体智能体(Embodied AI)和其他相关领域中的研究进展。

扩展法则的起源
扩展法则在工程和物理科学中通常指两个变量间的幂律关系,早期主要用于描述地质、天文等自然现象中的规模不变性。具体到深度学习领域,研究者注意到某些变量(如模型大小和损失)之间也可能存在类似的幂律关系。Hestness等人(2017)和Rosenfeld等人(2019)在深度学习模型中观察到这些规律,但Kaplan等人(2020)的研究首次系统性地分析了大语言模型中的扩展法则,并推广了其应用。
大语言模型中的扩展法则
大语言模型的实际应用价值推动了扩展法则在该领域的研究。Hoffmann等人(2022)进行了更精确的模型与数据集规模权衡分析,指出模型和数据集的规模应当同比例扩大,挑战了Kaplan等人提出的以模型扩展为优先的结论。后续研究在扩展系数的计算方法、优化策略、超参数的影响以及重复数据训练等方面做了进一步探索。例如,Sardana和Frankle(2023)提出应在推理计算预算中加入模型扩展的影响,而Muennighoff等人(2024)分析了多次重复数据训练对数据充足条件的影响。此外,Hutter(2021)和Maloney等人(2022)也尝试从理论角度解释为何扩展法则在深度学习中能如此有效。
实体智能体中的扩展法则
与大语言模型相比,具身AI的扩展法则研究尚不完善。早期的研究主要集中于通过大规模强化学习(RL)训练超越人类水平的智能体,如Silver等人(2017)的AlphaGo和Berner等人(2019)的Dota 2智能体。Neumann和Gros(2022)在自我对弈的RL中观察到某些变量间的幂律关系,而Hilton等人(2023)则发现,奖励信号并不总是符合幂律关系,必须经过特定转换才能生成一致的扩展法则。
受到大语言模型扩展效应的启发,具身AI领域的研究开始探索在离线数据集上进行大规模生成预训练的有效性。这类研究包括在电子游戏(如Baker等人,2022)、机器人学(如Brohan等人,2022,2023)以及多领域任务(Reed等人,2022)中应用行为克隆目标,或是利用世界建模目标(如Hu等人,2023)。这些研究通常通过增大模型规模来证明规模对具体任务的提升效果,但多以任务完成率等下游指标为主,缺乏对模型和数据集规模平衡的深入探讨。
本研究的差异
论文提出,为了更系统地研究具身AI的规模效应,应优先考虑在离线数据集上使用生成预训练损失(而非任务完成率等下游指标)作为中间信号来衡量模型扩展效果。这种方法比直接观察下游任务表现更清晰,能更好地分析扩展法则的影响。目前,具身AI领域中很少有工作采取这一策略。Tuyls等人(2023)在附录A中介绍的行为克隆任务的预训练损失与计算量关系研究提供了有价值的初步探索,而本研究则进一步扩展了世界建模和行为克隆任务的扩展法则分析。
图像与视频建模中的扩展法则
在其他模态的自回归建模中,也观察到了扩展法则。例如,Henighan等人(2020)发现视频数据建模中模型和数据集的最佳扩展比例与大语言模型相近,且不受分词器影响。然而,本研究在具身AI中采用了更新的方法,发现分词器的压缩率对扩展法则具有显著影响。此外,Tian等人(2024)在图像建模中也观察到了扩展法则的出现。
综上所述,尽管扩展法则在各个领域得到广泛研究,本论文在具身AI领域中的生成预训练任务上提出了一种新的视角,即关注生成损失而非下游任务表现。这一做法简化了分析过程,为具身AI的模型规模扩展提供了理论支持和实践指导。
3. Methodology
本章详细介绍了本文研究的实验方法,包括任务设置、模型架构、数据集以及扩展法则分析的方法。
3.1 任务 (Tasks)
论文关注的主要任务有两个:
- 世界建模 (World Modeling, WM)
:预测未来的观察状态,即通过先前的观察和动作预测下一时刻的环境状态。此任务让智能体更深入理解环境的运作机制,可用于规划或动态式强化学习(Dyna-style RL)。
公式表示为:

其中,(o_t) 表示观察状态,(a_t) 表示动作。
- 行为克隆 (Behavior Cloning, BC)
:预测离线数据集中演示者的行为,从而生成一个可以直接用于行动的策略。通过对历史观察和动作的预测来克隆行为。
公式表示为:
行为克隆适用于基于模仿学习的智能体,可以直接用于环境中执行,或进一步进行微调。
本研究聚焦于对生成预训练的全面建模,研究如何在生成此类条件概率分布时应用扩展法则,留待未来研究的任务包括表示学习或奖励为核心的模型。
3.2 模型架构 (Architectures)
论文主要采用GPT-2风格的自回归Transformer作为核心模型,并设计了两种输入图像观察的不同方式:
- 离散表示架构(Tokenized Architecture)
- 图像观察被分解为多个离散token,由预训练的VQGAN编码器将图像转换为离散表示,形成特定的图像token。
- 离散动作映射到不重叠的词汇表空间。
- 将序列表示为一个连续的离散token序列,即图像和动作交替出现。Transformer通过最大化图像token(世界建模任务)或动作token(行为克隆任务)的似然估计来训练。
- 这种离散表示架构在世界建模和行为克隆任务中广泛应用。
- 连续表示架构(CNN Architecture)
- 将图像输入至一个小型的CNN网络,获得一个单一的连续嵌入表示。
- 动作维度独立预测,即假设条件概率可以分解成各个动作维度的独立概率。
- 每次预测动作时只需前向传递一次Transformer,大幅降低计算复杂度。
- 这种连续表示架构常用于处理高频度的行为预测任务,如复杂的电子游戏控制场景。
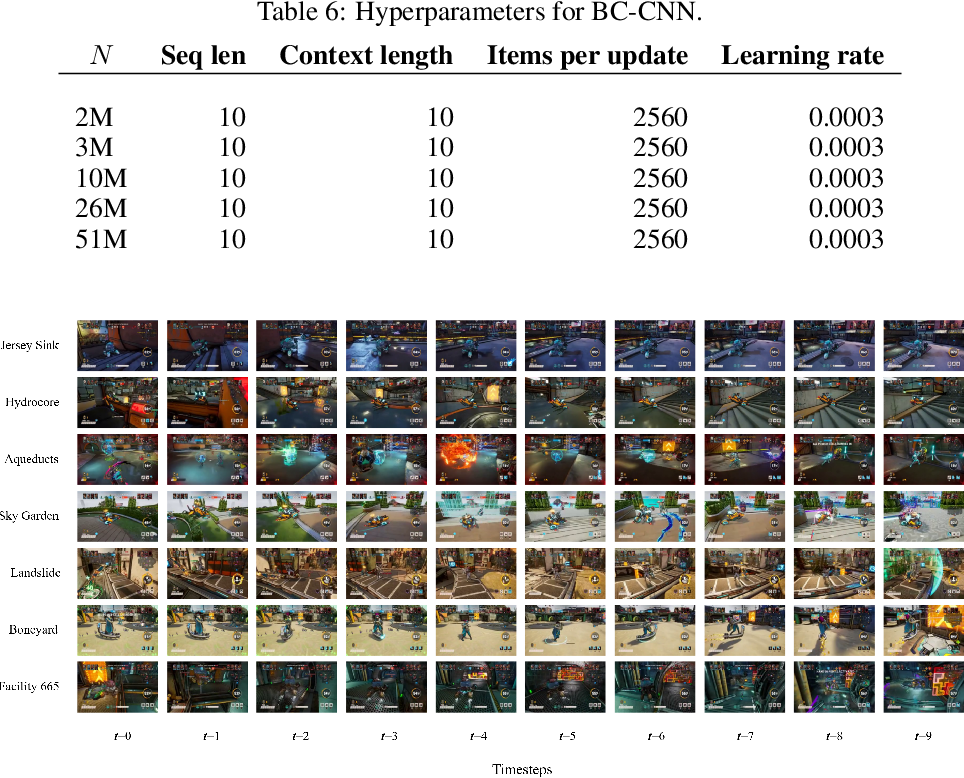
3.3 数据集 (Datasets)
为了能够清晰地研究扩展法则对预训练损失的影响,论文选择了一个高度多样且规模庞大的数据集。数据集来源于多人对战游戏Bleeding Edge,其特点如下:
- 数据规模:数据集包含了8.6年的人类游戏数据,足够大,模型可以仅经过少量训练迭代就能够学习到数据的多样性,避免重复数据对模型学习的干扰。
- 多样性:游戏包含不同的地图、角色和技能,智能体在每局游戏中面临不同的战术选择和对手行为,数据包含了丰富的策略和细粒度控制信息。
论文根据不同实验设计了两种版本的数据集:
- 7个地图数据集:包含了8.6年的游戏数据,覆盖了所有地图。
- Sky Garden地图子集:从7个地图中选取了单一地图Sky Garden的数据,包含约1.1年的人类游戏数据,用于某些特定实验。
3.4 扩展法则分析方法 (Scaling Analysis Methodology)
在扩展法则分析中,研究关注以下几个变量:
- 模型规模(Model Size, (N):可训练参数的总数量。
- 数据集规模(Dataset Size, (D):Transformer在训练过程中见到的输入总量。
- 计算量(Compute, (C):训练所需的浮点操作数(FLOPs),采用的近似计算公式为 (C = 6ND)。
- 损失(Loss, (L):标准的分类交叉熵损失,用于评估模型的预测准确性。
在此基础上,论文定义了每个变量的“计算最优”版本。以损失为例,计算最优损失表示在给定的计算预算下可以达到的最小损失:

对应的最优模型和数据集规模定义为在此计算预算下实现最小损失的配置:

论文提出了两种拟合方法来估计这些计算最优的关系:
- Frontier Fit(前沿拟合):对达到高效前沿的模型进行拟合,得到最优模型和数据规模的幂律关系。此方法不假设训练曲线的具体形式,因此适用于预算较大的模型。
- Parametric Fit(参数拟合):当前沿拟合不可用时,使用参数拟合,根据训练曲线拟合损失的参数化形式,从而估计扩展系数。此方法假设特定的训练曲线形式,适用于预算较小的模型。
训练细节:为减少多次训练的冗余,论文采取每个模型一个固定学习率的训练方式,使得每个模型仅需进行一次训练。这种方法有效降低了计算资源的消耗,同时确保了结果的计算一致性。
通过以上方法,论文能够系统性地分析在具身AI中的生成预训练损失如何随着模型规模和数据集规模的扩展而变化,从而为具身AI领域的扩展法则研究提供坚实的实验基础。
4. Scaling Analysis in Embodied AI
本章通过对世界建模和行为克隆任务的实验,详细分析了具身AI中的扩展法则。作者研究了模型规模、数据集规模和计算量对生成预训练损失的影响,并尝试通过扩展法则解释具身AI中如何实现计算最优。
4.1 世界建模任务中的扩展分析 (Scaling Analysis in World Modeling)
在世界建模任务中,作者对两种不同的分词器(VQGAN编码产生的256个token和540个token)的设置进行了扩展法则的实验,结果如下:

- WM-Token-256(256个token设置)
- 研究发现,模型规模和数据集规模的最优系数均接近0.5,这与LLMs中的扩展法则一致,表明随着计算量增加,模型和数据集的规模应同比例扩大。
- 该结果显示,增加模型规模和数据集规模的比例应保持一致,以达到最佳的训练效果。

- WM-Token-540(540个token设置
- 采用更多token表示图像时,最佳模型规模系数增加至0.62,而数据集规模系数减少至0.37。这表明,当图像的分词率(tokenization rate)提高时,模型的扩展更倾向于增加模型规模,而不是数据集规模。
- 这种现象表明分词器的压缩率对最优模型大小与数据集大小的平衡有显著影响。分词器压缩率越高(即每个图像的token数减少),需要更大的数据集规模;而压缩率低的分词器则需要更大的模型规模来处理细化的信息。

这些发现表明在世界建模任务中,分词器的选择会显著影响扩展策略。高分辨率分词器(更多token)倾向于增大模型规模,而低分辨率分词器则需要增大数据集规模。
4.2 行为克隆任务中的扩展分析 (Scaling Analysis in Behavior Cloning)
在行为克隆任务中,作者比较了两种架构(基于Token的离散输入和基于CNN的连续输入)的扩展法则。

- BC-Token(基于token的行为克隆)
- 尽管行为克隆和世界建模任务在架构和数据集上相似,但BC-Token的最优扩展系数偏向于增加数据集规模(Noptimal = 0.32, Doptimal = 0.68),与WM-Token-540相比有明显差异。
- 在相同计算预算下,BC-Token模型的计算最优模型规模显著小于WM-Token。例如,当计算预算为10^18 FLOPs时,BC-Token-540的计算最优模型规模为2M和11M参数,而WM-Token-540的为27M和110M参数。
- 由于行为克隆任务的损失函数收敛速度较慢,导致前沿拟合法难以应用,因此该实验主要采用参数拟合法。
- BC-CNN(基于CNN的行为克隆)
- 当采用CNN架构将图像输入作为连续嵌入向量时,扩展法则系数偏向于增加模型规模(Noptimal = 0.66, Doptimal = 0.34),这一结果更接近于LLMs和WM-Token中的扩展系数。
- 这一结果表明,模型架构的选择对行为克隆任务的扩展法则影响显著。基于token的离散输入更依赖于数据集规模,而基于CNN的连续输入则更依赖于模型规模。
这些结果说明行为克隆任务中,模型架构的设计对扩展法则的影响较大。在token架构中,数据集规模的增加更重要,而在CNN架构中,模型规模的增加更重要。
4.3 世界建模任务中的外推实验 (Extrapolation in World Modeling)

为了验证扩展法则的外推能力,作者在WM-Token-256设置下进行了大规模模型实验:
- 训练一个894M参数的WM-Token-256模型,其计算量比之前的实验多一个数量级。
- 实验结果显示,该模型的学习曲线和之前扩展法则的预测曲线非常一致,验证了扩展法则在大规模计算下的准确性。
- 该实验表明,通过扩展法则可以有效预测在更大规模模型和计算量下的最佳配置,这为进一步优化超大模型的训练提供了理论依据。
小结
本章研究表明:
- 分词器和架构的选择对模型扩展法则有显著影响。在分词器的压缩率较高或采用token架构时,数据集规模的扩展更为重要;而在分词器压缩率较低或采用CNN架构时,模型规模的扩展更为重要。
- 扩展法则的外推性得到验证,表明在无限数据和足够计算资源的条件下,扩展法则可以帮助预测更大规模下的最佳模型配置。
这些研究结果为具身AI中模型和数据的最佳扩展策略提供了参考,使得在不同任务和架构下可以更有效地利用计算资源。
5. Further Analysis
本章对之前实验中观察到的扩展法则现象进行了深入探讨,并分析了三大关键问题,以解释不同任务和架构下扩展系数的差异。

5.1 问题一:为什么 BC-Token 与 WM-Token 的训练曲线表现不同?(Q1: BC-Token vs. WM-Token)
在相同架构和数据集的情况下,BC-Token 和 WM-Token 的训练曲线表现差异明显。作者提出了两种可能的解释:
- 稀疏的损失信号
:在BC-Token任务中,单个观察-动作对的离散token总数为(dz + da)。对于WM-Token的大分词器设置,世界建模任务获得的监督比例约为97%(来自图像的token),而行为克隆任务的监督比例仅为3%(来自动作的token)。因此,WM-Token在每次训练中获取了更丰富的监督信号,而BC-Token的监督较稀疏。
- 粗粒度的标签
:在WM-Token中,每个token代表特定颜色或图像纹理等细节,提供了细粒度监督,而在BC-Token中,动作可能因上下文不同而具有多种含义(如“前进”可以指逃跑、追击或导航),标签更具抽象性。因此,BC-Token的监督信号更模糊,需要更大的数据集来捕捉复杂的行为模式。
为了验证以上假设,作者设计了一个小规模的语言建模实验,对比了密集、稀疏和超类标签(super-classed)损失情况:
- 密集损失:所有token参与监督,得到的最优模型规模系数为0.63。
- 稀疏损失:仅使用最后一个token参与监督,最优模型规模系数降低为0.5。
- 稀疏+超类损失:将最后一个token进一步简化为两大类,最优模型规模系数进一步降至0.15。
实验结果验证了稀疏监督和标签抽象性会显著降低模型规模的最优扩展系数,这与BC-Token任务中观察到的结果一致。
5.2 问题二:为什么从 BC-Token 切换到 BC-CNN 会改善损失曲线?(Q2: BC-Token vs. BC-CNN)
尽管行为克隆任务中的BC-Token和BC-CNN架构具有相同的非精细化损失信号,但BC-CNN的训练曲线更早收敛。其原因在于:
- 在BC-Token架构中,每个观察-动作对的预测需要556次计算步骤,而在BC-CNN中只需一步。这意味着BC-Token在每个动作预测中消耗的计算量约为BC-CNN的556倍,因此即使参数相同,BC-Token可以学习到更为复杂的函数。
- 由于计算资源密集,BC-Token模型需要更多训练数据来实现类似的表达能力,导致其曲线更晚收敛。
这表明,尽管BC-Token架构在理论上可以表现更好,但由于计算密集,它对数据量的需求较大。而BC-CNN则由于计算效率更高,能够在较少数据下达到同样的效果。
5.3 问题三:为什么 WM-Token-256 与 WM-Token-540 的最优模型规模系数不同?(Q3: WM-Token-256 vs. WM-Token-540)
在世界建模任务中,从256个token的VQGAN分词器切换到540个token的VQGAN分词器后,最优模型规模系数从0.49增加到0.62。这种变化可以归因于分词器的压缩率差异:
- 低压缩率:当图像被编码为更多的token(540 token)时,每个token的压缩程度降低,信息粒度更细。这意味着每个token的预测任务变得更简单,不需要非常复杂的模型来提取信息。因此,在这种情况下,较小的模型也能够胜任任务。
- 高压缩率:使用更少的token(256 token)时,信息被压缩得更密集,导致每个token包含更多信息,预测难度增加。这需要更大规模的模型来进行更高复杂度的计算。
为验证压缩率对扩展法则的影响,作者进行了额外的语言建模实验,对比了两种不同的分词方式:
- 字符级分词(低压缩):得到的最优模型规模系数为0.66。
- GPT-2分词器(高压缩):得到的最优模型规模系数降低到0.44。
这一实验进一步证实了压缩率较低的分词器倾向于需要较大的模型规模,而压缩率较高的分词器对数据集规模要求更高。
小结
通过这些分析,作者得出了以下几点重要结论:
- 监督信号的稀疏性和标签粒度直接影响最优模型规模的扩展系数。稀疏或粗粒度的标签会降低最优模型规模的扩展系数,使数据集规模相对更重要。
- 模型架构在行为克隆任务中起到关键作用。计算效率较低的BC-Token架构更依赖数据规模,而计算效率高的BC-CNN架构更依赖模型规模。
- 分词器压缩率对扩展系数有显著影响。低压缩率分词器需要更大规模的模型来处理细化信息,而高压缩率分词器则需增大数据集规模。
这些分析为具身AI的模型设计提供了更细化的扩展法则指导,能够帮助研究者根据任务需求选择合适的模型规模和数据集规模配置。
6. Discussion & Conclusion
在本章中,作者总结了论文的主要研究发现,讨论了扩展法则对具身AI的启示以及研究的局限性和未来发展方向。
主要研究发现
论文的核心贡献在于揭示了世界建模(World Modeling)和行为克隆(Behavior Cloning)这两个具身AI任务中存在与大语言模型(LLMs)类似的扩展法则。通过聚焦于生成预训练(Generative Pre-training)任务,作者发现:
- 扩展法则的普适性
- 在世界建模任务中,模型规模和数据集规模的扩展法则类似于在大语言模型中观察到的规律。模型的最佳规模和数据量可以根据计算预算通过幂律关系进行推算,使得模型在固定预算下实现性能的最大化。
- 分词器的压缩率影响扩展法则
- 实验显示,不同的分词器压缩率(即每个观察对应的token数量)对模型和数据集规模的最佳平衡有显著影响。使用低压缩率的分词器(更多token)时,最佳配置更偏向于增大模型规模;而在高压缩率分词器(更少token)时,则更偏向增大数据集规模。
- 行为克隆任务的架构影响
- 在行为克隆任务中,不同的架构类型(基于token的离散架构和基于CNN的连续架构)对扩展法则的影响也较大。基于token的离散架构更依赖于数据集的规模,而基于CNN的连续架构则更依赖于模型的规模。这表明在具身AI的行为克隆任务中,架构选择在扩展策略中起到了重要作用。
通过这些发现,作者为具身AI模型的规模设计和数据需求提供了理论依据,使得研究者可以更加科学地规划计算资源的分配。
实际应用启示
本研究为具身AI领域提供了几个重要的实际应用启示:
- 高效利用计算资源
- 研究结果表明,通过精确的扩展法则,可以在给定的计算预算下选择最佳的模型和数据集配置,以实现性能的最大化。这对于那些计算资源有限但希望获得最佳性能的实际应用尤其有用。
- 模型扩展策略的指导
- 在世界建模任务中,研究结果建议在增加计算预算时,模型规模和数据集规模应同比例扩展。而对于行为克隆任务,最佳扩展策略因架构不同而异。研究者可以依据任务类型和模型架构,选择合适的扩展策略。
- 改进具身AI的训练效率
- 本研究表明,通过选择适合的分词器和架构,具身AI中的训练效率可以显著提升。例如,在需要细粒度观察的任务中,可以选择低压缩率分词器来提升训练效果;而在具备足够数据的情况下,可以选择高压缩率分词器来降低对计算资源的需求。
局限性与未来研究方向
尽管本研究在具身AI的扩展法则研究上取得了重要进展,但作者指出了一些局限性,并提出了未来的研究方向:
- 模型和数据的多样性
- 本研究仅在特定的具身AI任务和架构上进行了扩展法则分析,未来可以考虑其他模型架构(如不同的Transformer变体)和任务类型(如强化学习中的奖励优化)对扩展法则的影响。
- 数据质量的影响
- 当前研究集中于离线数据集中的生成预训练损失,假设数据足够丰富且无重复。然而,实际数据的质量可能会影响模型的扩展效果。因此,未来可以考虑研究数据质量(例如噪声和重复数据)对扩展法则的影响。
- 下游任务表现与推理效率
- 尽管本研究的结果在生成预训练任务上表现良好,但最终具身AI模型的有效性还取决于下游任务(如在游戏或机器人中的实际表现)。如何将扩展法则的研究结果应用于下游任务的优化,仍需进一步研究。
- 同时,在推理效率和延迟方面,扩展法则的实用性尚待验证。未来工作可以探讨如何在推理过程中结合扩展法则,以获得更高效的模型。
总结
综上所述,本文在具身AI领域首次系统地分析了世界建模和行为克隆任务中的扩展法则。通过揭示与大语言模型类似的扩展规律,作者为具身AI的规模优化和资源配置提供了理论支持。这项研究不仅为特定具身AI任务的设计提供了参考,也为未来其他领域的扩展法则研究提供了新的视角和方法。
7. Extended Related Work
在本节中,作者进一步详细阐述了与扩展法则相关的其他重要研究,比较了具身AI(Embodied AI)和其他领域中扩展法则的异同,为本研究提供了理论背景和参考依据。
行为克隆的初步研究
Tuyls等人(2023)进行了一项初步研究,探讨了行为克隆任务中预训练损失和计算量之间的关系。与本研究不同的是,Tuyls等人的实验数据来自于固定的预训练智能体在Atari和NetHack等游戏中的演示数据,这些数据由一个单层LSTM网络生成,其规模通过宽度扩展来增加参数数量。研究表明,不同游戏中最优模型规模的扩展系数 ( N_{\text{optimal}} \propto C^a ) 范围在0.58到0.79之间。
本研究在多个方面与Tuyls等人的工作有所不同:
- 模型类型:本文主要使用Transformer模型,而非LSTM,并且对两种不同的架构(基于离散token的模型和基于CNN的模型)进行了测试。
- 数据类型:本文的数据来自人类行为,而非预训练智能体生成的数据。由于人类行为更为复杂,行为克隆任务在具身AI中的表现更为多样化。
- 研究任务:本文不仅研究了行为克隆任务,还对具身AI中的世界建模任务进行了扩展法则的分析,为不同类型的生成预训练任务提供了理论支持。
扩展法则在其他领域的应用
在其他数据模态中,自回归建模任务也观察到了类似的扩展法则现象,这些发现与本文的世界建模任务尤为相关。
- 视频和图像建模
- Henighan等人(2020)发现,视频建模中的模型和数据集的最佳扩展比例与大语言模型的扩展规律相似,其模型和数据集的比例同样可以通过幂律关系来估算。此外,他们发现分词器的选择并未显著影响扩展规律。
- 本研究在具身AI领域的世界建模任务中得出了不同的结论,即分词器的压缩率(token数量)对扩展系数具有重要影响。具体而言,在使用低压缩率分词器(即更多的token)时,模型规模的扩展相对更重要;而在高压缩率分词器(即更少的token)时,数据集规模的扩展更重要。
- 图像生成建模中的扩展法则
- Tian等人(2024)在图像生成任务中,基于非栅格(non-raster)顺序的图像token预测任务中观察到了扩展法则。这些结果也表明,在图像建模中,随着模型规模和数据集规模的增加,性能提升符合幂律关系。
这些研究为具身AI的扩展法则研究提供了参考。与视频和图像建模类似,具身AI的世界建模任务也依赖于生成预训练,而模型规模和数据集规模的扩展比例对性能提升的影响在不同任务和数据模态中表现出相似的规律。
这些研究为具身AI的扩展法则研究提供了参考。与视频和图像建模类似,具身AI的世界建模任务也依赖于生成预训练,而模型规模和数据集规模的扩展比例对性能提升的影响在不同任务和数据模态中表现出相似的规律。
本研究的独特之处
尽管具身AI中的扩展法则研究受到大语言模型(LLMs)、视频和图像建模等领域研究的启发,但本研究在几个方面独具特色:
- 生成预训练损失的选择
本研究关注生成预训练损失作为扩展法则的衡量标准,而非下游任务的实际表现。这样做的目的是在具身AI的复杂环境中,寻找一种更简单、可量化的中间指标。这种方法有效避免了在具身AI任务中直接使用下游表现作为扩展法则分析指标带来的复杂性。
- 扩展法则在具身AI的广泛应用
- 本研究不仅限于行为克隆任务,还扩展到世界建模任务,为具身AI任务中的扩展法则提供了更广泛的实验支持。此外,研究探讨了架构、分词器选择和数据压缩率等因素对扩展法则的影响,这在其他领域的扩展法则研究中较少见。
- 具身AI中模型和数据的最优比例
- 本文通过实验分析了在具身AI的特定任务中如何平衡模型和数据规模,从而获得计算最优配置。这些结论能够帮助研究者更高效地利用计算资源,设计合适的模型规模和数据集规模配置,从而实现具身AI任务的最佳表现。
小结
本节总结了其他领域的扩展法则研究为本文提供的参考和启发,并进一步明确了本研究的独特贡献。本研究在具身AI领域中,通过生成预训练损失作为中间信号,系统性地研究了世界建模和行为克隆任务的扩展法则,为具身AI任务中模型和数据规模的优化提供了理论支持。这一新颖的方法不仅填补了具身AI领域的研究空白,也为扩展法则的跨领域应用提供了宝贵的经验和指导。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![ASTUTE RAG[Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models]克服大型语言模型的不完美检索增强和知识冲突-AI论文](https://assh83.com/wp-content/uploads/2024/12/image-5-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)