1. Introduction
该论文的引言部分重点讨论了如何创建一种具有广泛任务能力的通用智能体,并能够在不同环境中自主演化。这一目标在AI领域长期以来备受关注,并已投入了大量研究。当前的大型语言模型(LLM)由于具备通用能力,被视为构建这种智能体的理想基础。

论文的研究动机在于现有方法的局限性。传统的智能体训练方法多依赖于人类监督,让模型模仿由专家提供的轨迹,但此种方式规模化困难,并且缺乏环境探索,导致模型的通用性和适应性受到限制。此外,一些方法虽然允许模型根据环境反馈进行自我改进,但通常只在特定环境下训练,形成的模型只能在狭窄的任务范围内有效,难以实现通用化。
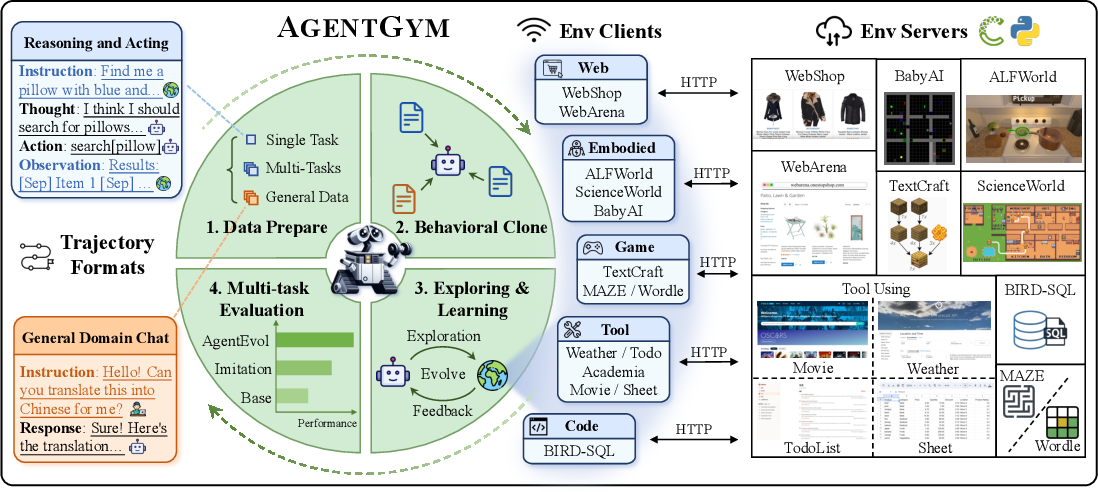
为了突破这一瓶颈,论文提出了一种新的框架AGENTGYM。该框架包括多种环境和任务,以支持智能体进行广泛、实时的多任务探索与学习。AGENTGYM通过集成多样化的数据集、基准测试套件及高质量的轨迹,支持智能体的演化实验。论文还提出了AGENTEVOL方法,用于探索智能体在未知环境和任务中的自我进化能力。

2. Preliminaries
在第二部分的“基本知识”章节中,该论文通过部分可观察马尔可夫决策过程(POMDP)来形式化描述智能体的任务和行为。定义了多个环境集 ( E ),其中每个环境 ( e \in E ) 都包含了不同的任务。对于每个特定环境 ( e ),任务被表示为一个POMDP,包括以下元素:
- 指令空间 ( U ): 表示任务的要求或指令。
- 状态空间 ( S ): 表示环境中的不同状态。
- 动作空间 ( A ): 表示智能体可以采取的行动。
- 观察空间 ( O ): 表示智能体可以观测到的环境信息。
- 状态转移函数 ( T: S \times A \rightarrow S ): 一个确定性函数,用于根据当前状态和动作更新状态。
- 奖励函数 ( r: S \times A \rightarrow R ): 用于根据动作和状态提供反馈。
在具体任务中,智能体基于其策略 ( \pi_\theta ) 来生成动作,并根据环境提供的反馈逐步调整,直到任务结束或达到最大步数。
该模型采用 ReAct 方法,以便智能体在生成动作前能首先生成“推理思维”,形成一种思维-动作-反馈的循环过程。在每个时间步 ( t ) 中,智能体会根据历史信息和当前反馈生成推理 ( h_{t+1} ),并随后生成动作 ( a_{t+1} )。这一过程不断重复,形成完整的轨迹 ( \tau = (h_1, a_1, o_1, …, o_T-1, h_T, a_T) 。
3. AGENTGYM: Platform, Benchmark Suite and Trajectory Set
该章节介绍了AGENTGYM的框架、基准套件和轨迹集,主要内容分为以下几个方面:
- 互动平台
AGENTGYM提供了一个包含多样环境、任务和目标的互动平台,支持LLM驱动的智能体进行任务探索。平台采用HTTP服务的API,以标准化任务说明、环境配置和智能体的观察/动作空间。此外,AGENTGYM提供了多轮互动和实时反馈的统一接口,用于支持在线评估、轨迹采样和互动训练。该平台包含了14种智能体环境和89种任务,涵盖网络任务、实体任务等多个领域,具有高度扩展性。

- 基准套件和指令收集
AGENTGYM基准套件AGENTEVAL涵盖了从多种环境和任务收集的指令,以进行多任务、多环境的全面评估。指令的扩展来自众包和AI方法,如self-instruct和指令进化等,通过选择具有挑战性的子集构建测试集,确保了指令的多样性和难度。
- 轨迹集AGENTTRAJ
AGENTGYM平台还收集了专家注释的轨迹集AGENTTRAJ,以支持智能体通过模仿学习掌握基本的任务能力。AGENTTRAJ-L是该数据集的扩展版本,为智能体的多任务学习提供更大的数据量。AGENTGYM利用最新的模型(如GPT-4-Turbo)和人工注释确保数据质量,以保障智能体训练的有效性【12:3†source】。
通过这些组件,AGENTGYM为研究者提供了一个开发和评估通用智能体的完整平台,进一步推动了智能体在多样化环境中的探索与进化。
4. AgentEvol for Evolution of Generally-capable LLM-based Agents
在本章节中,论文提出了 AGENTEVOL 算法,通过模仿学习和自我进化两个步骤,来训练和提升通用性强的大模型智能体。该方法主要包含两个关键步骤:行为克隆(Behavioral Cloning)和探索与学习。
4.1 行为克隆 (Behavioral Cloning with Collected Trajectories)
在这一部分,研究人员首先使用专家轨迹数据 AGENTTRAJ 对模型进行行为克隆,赋予智能体基本的交互能力。具体方法是利用所收集的轨迹集 (D_s) 进行训练,使得模型模仿每个轨迹中的思维 ( h ) 和动作 ( a ),从而达到基础的指令执行和任务完成能力。论文中通过最大化以下目标函数来实现:

这一步骤使得智能体能够在多任务环境中掌握基础知识和交互能力,为后续的探索学习阶段打下基础。
4.2 通过探索与学习实现进化 (Evolution through Exploration and Learning)
AGENTEVOL 的核心思想是将强化学习视为一种推理问题,使智能体在遇到新任务时能够自我进化。与标准的强化学习不同,AGENTEVOL 采取了一种基于推理的优化方法,利用智能体在多个环境中的探索结果来更新策略,从而在新的任务和指令中获得更高的奖励。
- 探索步骤
在每次迭代的探索阶段,智能体在每个环境中生成多个互动轨迹 ( D_m ),并基于奖励函数 ( r(e, u, \tau) ) 对每个轨迹进行评分。所有环境的轨迹合并后形成新数据集 ( D_m ),其中还包含行为克隆阶段的数据 ( D_s )。
- 学习步骤
在学习阶段,智能体使用新的数据集 ( D_m ) 进行训练,以优化以下目标函数:

通过在探索和学习之间交替,AGENTEVOL 实现了智能体的渐进式进化,使得模型能够适应已知和未知的任务和指令。
AGENTEVOL 的实验结果表明,通过该方法训练的智能体在不同环境和任务上的表现显著优于行为克隆基线,表明自我进化能力在提高模型通用性方面的潜力。
5. Behavioral Cloning with Collected Trajectories
该章节详细介绍了通过行为克隆(Behavioral Cloning, BC)对智能体进行训练的过程,以帮助其掌握基本的交互能力。行为克隆的核心是在AGENTTRAJ轨迹集上对智能体进行训练,使其能够逐步模仿专家的行为和思维过程。具体来说,行为克隆步骤包括以下要点:

- 目标函数
行为克隆过程通过最大化目标函数 ( J_{BC}(\theta) ) 来训练智能体。该函数定义为智能体在特定环境 ( e ) 和指令 ( u ) 下生成轨迹 ( \tau ) 的概率之和:

在该公式中,智能体学习通过模仿专家轨迹中的思维 ( h ) 和动作 ( a ) 来进行任务执行和指令跟随。
- AGENTTRAJ 数据集的使用
AGENTTRAJ是收集的专家轨迹集,为智能体提供了涵盖不同任务和指令的多样化数据。在行为克隆训练中,该数据集用于对智能体进行基础训练,使其在多任务、多环境的复杂场景中掌握指令执行和任务解决的基本能力。
- 基础模型的建立
:在完成行为克隆训练后,论文将基础智能体视为一个基本的通用能力智能体,即 ( \pi_\theta^{\text{base}} ),它具有初步的指令跟随和任务完成能力。该基础模型后续将在探索与学习阶段进一步优化。

该章节的核心是通过行为克隆帮助智能体打下基础,使其能够在基本任务中具备指令跟随的能力,为后续的自我进化提供一个有效的起点。
6. 通过探索与学习实现进化 (Evolution through Exploration and Learning)
这一章节介绍了 AGENTEVOL 算法中智能体进化的两个主要步骤:探索(Exploration)与学习(Learning)。
6.1 探索步骤 (Exploration Step)
在每轮探索中,智能体在每个环境 ( e ) 中与任务指令集 ( Q_e ) 交互,以生成多个互动轨迹。与行为克隆阶段相比,这里使用了更广泛的指令集,以推动智能体处理未知任务。对于每个指令 ( u_j ),智能体根据当前策略生成互动轨迹 ( \tau_j ),并根据环境奖励函数 ( r(e, u, \tau) ) 对这些轨迹进行评分。生成的数据集 ( D_m ) 包含所有环境中的轨迹,并且包含行为克隆步骤中的初始轨迹数据 ( D_s ),从而形成一个综合数据集。
6.2 学习步骤 (Learning Step)
在每轮的学习步骤中,智能体利用探索步骤生成的数据集 ( D_m ) 对模型进行优化,以最大化目标函数:

这一目标函数基于奖励函数调整策略,使智能体在高奖励轨迹上表现更佳。通过在探索和学习步骤间交替进行,AGENTEVOL 使得智能体能够适应已知和未知的任务和指令,从而推动智能体的渐进式进化,最终形成一个在不同任务中表现出色的通用智能体。
7. 实验与讨论 (Experiments and Discussion)
本章节详细介绍了实验设置、主要结果及分析,并从多个维度验证了 AGENTEVOL 算法的有效性。
7.1 实验设置 (Experimental Setup)
- 环境与任务
通过 AGENTGYM 框架探索智能体的自我进化,实验包含11种环境(如WebShop、ALFWorld、SciWorld等)。行为克隆(Behavioral Cloning, BC)使用的指令量少于进化阶段,以检验智能体在探索时的泛化能力。
- 基线模型
选用了多种封闭源和开源模型(如GPT-3.5-Turbo、GPT-4-Turbo、Claude 3、Llama-2-Chat)和基于专家轨迹训练的AgentLM。在AGENTTRAJ-L上进行BC的智能体作为最大BC性能的基线。
- 实现细节
实验在8台A100-80GB GPU上进行,以Llama-2-Chat-7B为主骨干模型,迭代次数设为4。为保证资源效率,每条指令在进化过程中仅采样一次。
7.2 主要结果 (Main Results)
实验结果显示:
- 封闭源模型
GPT-4-Turbo等封闭源模型在大部分任务上表现良好,但未能在所有任务上达到满意的效果,表明需要更强大的智能体。
- 开源模型
如Llama2-Chat表现较差,突显了初始行为克隆步骤的重要性。
- AGENTEVOL优于基线
AGENTEVOL在大多数任务上优于BClarge和其他SOTA模型,验证了进化方法在多任务环境下的优越性】。
7.3 讨论与分析 (Discussion & Analysis)
- 数据合并策略与迭代次数的消融实验
实验发现将每次迭代生成的轨迹与初始数据合并,能带来更稳定的提升,而将其与前一轮轨迹合并会导致性能波动。实验还表明,性能随着迭代次数增加逐渐提升,但在后续迭代中趋于稳定,因此选取M=4。
- 采样次数的影响
对采样数K的消融实验表明,增大K略微提升性能,但提升不显著,因此选定K=1以提高计算效率。
实验结果总体上证明了 AGENTEVOL 的有效性,尤其在任务复杂的环境中表现优异,表明该方法在构建多任务智能体方面具有显著潜力。
网址:Project site: https://agentgym.github.io
网址:AGENTGYM suite: https://github.com/WooooDyy/AgentGym

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![基于知识图谱增强的语言智能体推荐系统[Knowledge Graph Enhanced Language Agents for Recommendation]-AI论文](https://assh83.com/wp-content/uploads/2024/11/2-Figure1-1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)