1. Introduction(介绍)
在论文的引言部分,作者首先介绍了人类的两种截然不同的思维方式,并引用了心理学家丹尼尔·卡尼曼(Daniel Kahneman)的“快思考”和“慢思考”理论,提出这种双重思维系统不仅存在于人类认知中,也可以被应用于AI系统。具体来说,卡尼曼的理论将人类思维分为两类:
- System 1
快速、自动、无意识的思维方式。这种思维方式适用于处理日常直觉和情感的判断,比如看到飞来的物体时快速做出的躲避反应,或者通过别人的表情识别情绪。
- System 2
慢速、深思熟虑、逻辑推理的思维方式。它被用来处理更复杂的任务,比如数学计算、规划未来或者解决复杂问题。System 2 需要更多的注意力和认知资源。
作者指出,人类的认知过程实际上是这两种系统的混合体:System 1 快速地生成建议、直觉、意图和情感,而 System 2 会对这些进行评估,做出最终决策。尽管许多复杂问题依赖于System 2,但很多日常任务则可以通过System 1更快速地完成。

双系统思维与AI的关联
论文进一步讨论了这种双系统思维模式在人工智能中的潜在应用,尤其是在大型语言模型(LLMs)推动下的AI代理的表现。随着AI技术的进步,尤其是自然语言处理和强化学习(RL)领域的突破,AI代理现在能够与用户进行复杂的自然语言交互,并通过语言理解和多模态数据感知世界。这些能力类似于人类System 1的功能:通过快速生成直觉式的响应和建议,形成连贯的对话。
然而,AI代理不仅需要能够进行对话,还需要能够完成复杂的多步骤推理和决策,这一过程更接近于System 2的慢速思维。比如,当AI代理需要解决涉及多个步骤的复杂问题时,它需要调用工具、查找外部信息、进行推理和规划,从而影响其内部状态并达到目标。
引入Talker-Reasoner架构
为了模拟这种双系统思维,作者提出了Talker-Reasoner架构:
- Talker(类似于System 1)
:这个代理快速且直观,专注于生成自然且连贯的对话响应。它通过记忆库中的信息快速生成反应,并与外部环境互动。Talker是整个系统中“总在运行”的部分,可以随时进行交互,无需等待慢速的推理和计划。
- Reasoner(类似于System 2)
:这个代理则较为缓慢且深思熟虑,专注于多步骤的推理和计划。它的任务是调用外部工具、查找信息并在环境中执行行动,从而更新代理的内部状态。Reasoner需要进行多次推理,并将这些推理的结果保存到记忆库中,供Talker调用。
这种分工可以大幅优化AI代理的性能,减少延迟。Talker能够快速处理日常对话和简单任务,而对于复杂问题,Talker可以选择等待Reasoner的推理结果再给出答案。这样,代理既能在简单情况下保持快速响应,也能在复杂情况下进行深度推理。
睡眠教练案例
为展示这个架构的实际应用,论文引用了一个睡眠教练代理的例子。这个代理通过与用户对话,帮助他们改善睡眠质量。Talker负责快速响应用户的问题,而Reasoner则负责制定更复杂的、多步骤的睡眠改进计划。通过这个例子,作者展示了Talker-Reasoner架构在实际环境中的应用效果。
总结来说,论文的引言部分阐述了双系统思维理论在人类认知中的重要性,并进一步将其引申至AI代理的设计中。通过引入Talker-Reasoner架构,作者旨在模拟人类快思考和慢思考的过程,从而提升AI在交互、推理和计划方面的能力。
2. Related Work(相关工作)
在相关工作章节,作者详细回顾了与论文研究内容密切相关的领域,尤其是与大型语言模型(LLMs)和代理系统中的推理与规划相关的最新进展。该章节为后续的Talker-Reasoner架构提出背景支持,并解释了该领域已有工作所取得的成果及其局限性。
2.1 大型语言模型在代理规划中的应用
作者首先介绍了近年来大型语言模型(LLMs)的兴起,尤其是在自然语言处理和对话生成任务中的应用。这些模型具有令人瞩目的涌现能力(emergent capabilities),例如:
- 零样本提示(Zero-shot prompting):即模型在没有明确样本的情况下,仅凭提示词就能够完成任务的能力【5†source】。
- 上下文学习(In-context learning):模型能够从对话或上下文中逐渐学习并调整其输出【5†source】。
- 复杂推理能力(Complex reasoning):通过多轮对话或推理链条来解决复杂问题【5†source】。
LLMs的这些能力使其能够在越来越多的AI代理中被应用,从AI编程助手、健康教练到虚拟导师等【5†source】。尽管这些模型能生成连贯的对话和语言响应,它们在面对需要多步骤规划和深度推理的问题时,仍然显得力不从心。为了应对这一挑战,研究者开始探索将语言模型与外部工具结合,以增强其推理与执行复杂任务的能力。
2.2 与代理交互相关的工作
最相关的工作之一是关于基于文本的AI代理。这类代理通过文本与用户交互,处理用户的需求并给出反馈。具体而言,作者列举了以下几个关键工作:
- ReAct架构:ReAct是一种结合了推理链条(Chain-of-Thought,CoT)提示和任务特定行动生成的框架【5†source】。它不仅生成推理轨迹,还可以生成任务所需的行动(例如调用工具)。这一框架为多步骤推理奠定了基础,但在对话生成和工具调用的协调上存在不足。
- Reflexion框架:Reflexion在ReAct的基础上进行了扩展,加入了自我反思的机制,试图通过反思来改进推理效果【5†source】。
- AutoGPT:AutoGPT是另一个较为广泛使用的工具,它通过为复杂任务创建子目标的方式来实现高层目标的自动化【5†source】。
尽管这些工作在推理与行动生成方面取得了一定的进展,但它们存在两个主要的不足:
- 没有在推理和规划的同时进行对话(Talking while reasoning/planning)
大多数现有的代理只是在推理结束后给出响应,而不会在进行推理的同时与用户进行自然交互。这种方式导致了对话的延迟和不连贯性,尤其是在需要即时交互的场景中。
- 缺乏显式信念建模(Explicit belief modeling)
这些代理通常只根据当前的对话生成响应,而不主动构建有关用户、任务或环境的长期信念模型。信念模型能够帮助代理在多轮对话中保持一致性,并更好地理解用户的目标、需求和障碍。
2.3 与自然语言反馈代理相关的工作
作者还讨论了一些研究中使用的**自然语言反馈(Natural language feedback)**机制,这些机制允许代理根据用户的反馈调整其计划或响应。例如,某些研究探索了通过强化学习(RL)来更新代理的计划【5†source】。与这些工作不同,本文提出的Talker-Reasoner架构不依赖RL来更新所有未来的计划,而是通过增强上下文学习,将反馈纳入当前任务的推理和决策中,以提高代理的反应能力和智能性。
2.4 与显式信念建模相关的工作
显式信念建模是本研究的另一个核心贡献,作者将其与**心智理论(Theory of Mind, ToM)**的研究进行了关联。心智理论是关于理解他人思想和行为的心理能力,即代理如何通过与用户的互动,构建关于用户的目标、计划、动机等的信念模型【5†source】。通过这种信念建模,代理能够在每次与用户的交互中积累对用户更全面的理解,进而优化推理和计划。
另外,作者还提到了与**世界模型(World Modeling)**相关的工作。世界模型的研究探索了如何让代理构建一个更为广泛的世界理解,以便更好地预测和推理。对于Talker-Reasoner架构而言,信念建模则是代理对用户及其行为的代理化模型。这一模型持续更新,并通过信念的变化指导Reasoner的决策和Talker的对话生成【5†source】。
2.5 小结
总的来说,本章的相关工作回顾展示了当前领域的几个重要方向:
- 大型语言模型在多步骤推理和规划中的应用取得了一定进展,但在自然语言交互中仍存在局限。
- 现有的AI代理系统缺乏对话与推理并行处理的能力,导致系统响应速度慢。
- 信念建模和心智理论的研究为理解用户行为提供了理论支持,但尚未广泛应用于实际的AI代理系统中。
通过这些回顾,作者为本文提出的Talker-Reasoner架构提供了理论依据和研究背景,并为后续章节详细描述这种双系统架构奠定了基础。
3. The Talker-Reasoner Agent Model(Talker-Reasoner代理模型)
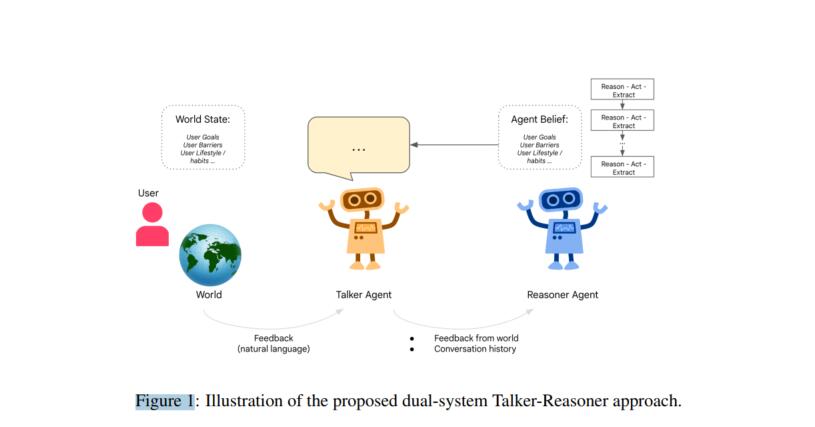
在这一章节中,作者详细介绍了论文的核心贡献——Talker-Reasoner代理模型,并将其作为模仿人类“快思考”(System 1)和“慢思考”(System 2)系统的架构。该模型分为两个部分,Talker代理负责快速、直观的对话生成,而Reasoner代理则负责更为复杂的多步骤推理和规划。这种双重系统架构帮助AI在与人类交互时既能保持对话的流畅性,又能在复杂情境下进行深度推理。

3.1 单语言代理与人类的互动:通过推理与计划协同对话与信念提取
首先,作者定义了一种单语言代理模型,这个代理能够通过自然语言与用户互动,帮助用户完成任务。为了实现这一目标,代理需要具备两个核心能力:
- 生成对话响应:代理必须能够与用户进行自然语言交互,生成连贯的对话响应。
- 多步骤推理与规划:代理不仅要生成对话,还要有能力执行多步骤的推理和规划,以解决复杂任务。
随着大型语言模型(LLMs)的引入,代理可以结合语言理解与推理能力,在与用户的互动中积累对任务和用户的认知。作者提出了一种基于强化学习(RL)的框架,能够帮助代理整合这些能力。
在这个框架下,代理通过与外部世界(包括用户和知识库等)进行部分可观察的交互(POMDP),逐步构建其对世界的信念。这些信念能够帮助代理在多轮对话中更新对用户目标、需求和情绪的理解。具体来说,代理通过以下流程工作:
- 观测与反馈:代理通过语言接收来自用户的观测和反馈,并将这些信息转化为代理内部的信念更新和计划。
- 行动生成:代理可以选择不同的工具(如搜索引擎或API)来获取外部知识,并根据这些信息制定计划。通过结合思维链条、工具调用和信念提取,代理生成解决问题的方案。
- 信念提取:代理会不断提取并更新其对用户的信念模型。这些信念模型是关于用户的目标、需求、情绪等信息的结构化表示,通常以JSON或XML格式存储。信念模型帮助代理在多轮对话中保持连贯性,并在不同上下文中做出一致的决策。
这部分建立了一个通用的语言代理框架,接下来,作者进一步提出了双系统架构,即将单一语言代理分为Talker与Reasoner两部分,分别处理快速反应和深度推理任务。
3.2 提出的双系统Talker-Reasoner代理模型
这一节是论文的核心部分,作者详细描述了Talker-Reasoner双系统代理模型的架构。该架构是基于卡尼曼的快思考和慢思考理论,分为Talker和Reasoner两个代理系统,各自承担不同的任务。

- Talker(快速思考,System 1)
- Reasoner(慢速思考,System 2)
Talker-Reasoner架构的交互
Talker与Reasoner通过记忆库进行交互。Talker依赖记忆库中的信念模型来生成快速响应,而Reasoner则负责更新信念并将其存储在记忆库中。当Talker需要生成复杂问题的回答时,它可以等待Reasoner完成推理,以确保回答的准确性。
不过,Talker在大多数情况下无需等待Reasoner的完成,而是使用已有的信念进行对话。只有在复杂问题下,例如用户请求多步骤计划时,Talker才会“等待”Reasoner的结果,这就类似于System 2接管System 1的决策过程。
3.2.1 The Talker (Thinking Fast) Agent
这一小节深入探讨了Talker代理的具体工作机制。Talker专注于快速生成自然语言对话,类似于人类的System 1,它追求响应速度和对话流畅性。Talker通过如下方式实现其功能:
- 与用户的交互:Talker通过强大的上下文学习模型生成对话,它结合用户最近的输入、对话历史和最新的信念模型来构建自然的对话响应。
- 访问记忆库:Talker与代理的记忆库交互,提取最新的信念和对话历史,以确保其响应的连贯性。记忆库中的信念由Reasoner生成,但Talker可以在Reasoner尚未完成更新时就利用旧的信念进行对话。
- 指令:为了确保Talker能够生成有用的对话响应,它会接收特定指令。这些指令决定了Talker在不同上下文下应如何回应用户的提问。
3.2.2 The Reasoner (Thinking Slow) Agent
Reasoner代理是一个负责复杂推理和决策的系统,它类似于人类的System 2,负责解决需要深思熟虑的问题。其工作机制如下:
- 多步骤推理:Reasoner代理执行复杂的推理过程,这通常包括多次调用外部工具或数据库,并结合推理链条逐步解决问题。
- 信念更新:Reasoner通过推理过程生成新的信念模型。这些信念代表了代理对世界的理解,包括用户的目标、动机等。信念模型以结构化的方式(如JSON或XML)存储在记忆库中,供Talker调用。
- 问题分解:Reasoner将复杂任务分解为多个子任务,并分别调用不同的模块或工具来解决每个子任务。这种分层推理方式使其能够处理更复杂的问题。
总结来说,这一章节详细介绍了Talker-Reasoner架构的设计与实现。Talker通过快速响应保证对话的流畅性,而Reasoner通过多步骤推理解决复杂问题。两者通过记忆库进行交互,协同工作,以模拟人类的“快思考”和“慢思考”系统。
4. Evaluation Case Study: Sleep Coaching Agent(评估案例研究:睡眠教练代理)
在这一章节,作者通过睡眠教练代理的案例研究来验证和展示所提出的Talker-Reasoner架构的实际应用。该案例说明了在一个现实的场景下,这一双系统架构如何帮助AI代理在与用户互动的同时完成复杂的推理和计划任务。
4.1 Grounding in a Real-World Scenario of AI Coaching for Sleep(基于现实场景的AI睡眠教练)
首先,作者选择了睡眠教练这一现实世界场景来验证他们的模型。睡眠教练的任务是通过与用户对话,帮助他们改善睡眠质量。这是一个实际应用场景,因为睡眠对人类健康有着重要的影响,而AI代理能够通过持续的互动帮助用户设定目标、制定改进计划、并提供反馈。
为什么选择睡眠教练作为评估场景?
- 用户模型:睡眠教练需要构建一个关于用户的信念模型,包括用户的睡眠问题、目标、习惯、障碍、和睡眠环境等信息。这种多维度的信息需要复杂的推理能力,正好可以验证Reasoner的信念提取和计划制定能力。
- 专家知识:睡眠教练需要有临床专家的知识基础,才能提供科学的建议。这要求代理系统能够调用外部知识,并将其转化为适合用户的个性化建议。
- 对话互动:睡眠教练需要在与用户的互动中保持对话的自然性和连贯性。这正是Talker擅长的任务,即快速生成连贯的对话响应。
通过这一案例,作者展示了Talker-Reasoner架构在面对复杂用户需求时的工作原理,并且如何通过分工协作,保持对话的流畅性和计划的复杂性。
4.2 Instantiating a Talker-Reasoner Dual-Agent Model for Sleep Coaching(为睡眠教练实例化Talker-Reasoner双代理模型)
在本节中,作者介绍了如何为睡眠教练实例化Talker-Reasoner双代理模型。
在本节中,作者介绍了如何为睡眠教练实例化Talker-Reasoner双代理模型。
1.睡眠教练的Talker代理
任务:Talker的任务是通过对话理解用户的睡眠问题,并提供及时的反馈。
实现:作者通过Gemini 1.5 Flash语言模型实例化了Talker代理。该模型能够结合临床专家知识,生成自然的对话响应。Talker被设计成能够处理用户的自然语言输入,并根据睡眠专家的建议,提供个性化的反馈。
指令集:Talker被赋予了不同阶段的指令集,包括理解阶段(Understanding phase)、目标设定阶段(Goal-setting phase)和计划制定阶段(Coaching-plan phase)。每个阶段的指令帮助Talker根据不同的上下文生成合理的对话。
2.睡眠教练的Reasoner代理
任务:Reasoner负责构建用户的信念模型,并生成多步骤的睡眠改进计划。
信念建模:作者设计了一套基于JSON/XML格式的信念模型,包含用户的睡眠问题、目标、习惯、障碍和环境等字段。这些字段能够随着Reasoner的推理不断更新。
分层推理:Reasoner在每次互动中,根据用户当前所处的阶段(理解、目标设定或计划制定),调用不同的推理模块生成相应的信念更新和计划。
3.Talker与Reasoner的协调
协同工作:Talker和Reasoner通过记忆库进行协调。Talker在大多数情况下可以立即响应用户,而不需要等待Reasoner的推理结果。然而,在需要多步骤计划时,Talker可以选择等待Reasoner完成推理再生成响应。
决定等待的条件:Talker是否需要等待Reasoner的推理结果,取决于信念模型中的“计划阶段”字段。例如,当用户处于“计划制定阶段”时,Talker会选择等待Reasoner完成推理再继续对话
4.3 Qualitative Results(定性结果)
本节通过两个具体例子展示了Talker-Reasoner架构的运行方式。
4.3.1 Example Conversation(对话示例)
这是一个典型的对话示例,展示了Talker和Reasoner在睡眠教练中的协同工作:
- 用户的输入:用户向AI教练寻求帮助,希望创建一个放松的睡前环境。
- Talker的响应:Talker首先根据信念模型中的信息生成快速响应,并询问用户可能导致睡眠障碍的因素。
- 用户的反馈:用户反馈表示噪音和光线是他们的主要困扰,并希望制定一个解决这些问题的计划。
- Talker的计划:Talker迅速生成了一个简单的计划,包括如何减少噪音和光线干扰的具体建议。
- 用户进一步反馈:用户表示希望逐步实施计划,并要求更多关于如何创建宁静氛围的资源。
- Reasoner的推理:Reasoner接管任务,生成了一个更为详细的计划,逐步介绍如何选择适合的颜色、声音等因素,并推荐了一些相关的YouTube资源。
- Talker整合Reasoner的响应:Talker将Reasoner的推理结果转化为自然语言对话,并继续与用户互动。
这个例子展示了Talker和Reasoner如何在复杂对话中协同工作。Talker在简单任务中快速响应用户,而在更复杂的任务中,Reasoner接管并提供详细的推理结果。
4.3.2 Adapting Planning from Feedback(根据反馈调整计划)
另一个例子展示了Talker-Reasoner架构如何根据用户的反馈动态调整计划:
- 用户的输入:用户对先前的计划表示满意,但希望加入一些关于“放松声音”的建议。
- Reasoner的调整:Reasoner根据用户的新需求,生成了一个新的计划部分,介绍了如何在卧室中使用自然声音营造宁静的环境,并提供了相关的YouTube资源。
这个例子展示了Reasoner如何根据用户反馈更新计划,并将结果反馈给Talker,从而保持对话的流畅性和连贯性。
4.4 Discussion(讨论)
在讨论部分,作者总结了双系统架构的成功模式和失败模式:
- 成功模式:直觉型Talker
在大多数情况下,Talker能够利用已有的信念模型快速生成响应,而无需等待Reasoner的推理。这种异步的工作模式非常有效,特别是在任务不太复杂或Talker已经具备足够信息时。
- 失败模式:快速判断型Talker
然而,在一些需要复杂推理的情况下,如果Talker没有等待Reasoner完成推理,它可能会做出错误的判断。例如,当用户需要一个详细的多步骤计划时,如果Talker在Reasoner尚未完成推理的情况下给出响应,可能会导致响应质量下降。
为了解决这一问题,作者建议在某些复杂情况下,Talker应强制等待Reasoner完成推理,以确保响应的准确性。这类似于在某些决策场景下,**System 2(慢思考)接管了System 1(快思考)**的决策。
总结来说,本章节通过睡眠教练代理的案例,展示了Talker-Reasoner架构在实际应用中的有效性。Talker负责保持对话的流畅性,而Reasoner负责生成复杂的多步骤计划。两者通过记忆库进行协同工作,实现了复杂任务的高效处理。
5. Discussion(讨论)
在讨论章节中,作者分析了Talker-Reasoner架构的实际表现,尤其是其在不同任务场景下的优劣,探讨了该模型的成功与失败模式,并为未来的研究方向提出了建议。
5.1 Talker-Reasoner架构的成功模式
在本文提出的Talker-Reasoner架构中,Talker与Reasoner的分工使得AI代理能够高效地处理不同类型的任务。具体来说,作者总结了架构的几个关键成功点:
- 直觉型Talker的优势
Talker的核心优势在于其能够快速生成对话响应,确保用户体验的流畅性。在多数情况下,Talker能够根据已有的信念模型和用户的输入快速做出判断,而不需要等待Reasoner的推理结果。这种模式类似于人类的快思考(System 1),能够处理日常的对话任务并快速回应。
- Talker与Reasoner的分工
Talker的快速响应与Reasoner的深度推理之间的分工是高效的。Talker持续与用户进行交互,而Reasoner则专注于更新信念模型和处理复杂的多步骤问题。这种分工减少了代理的总体计算成本,同时确保在复杂问题上能够通过推理得到更深入的解决方案。
- 异步交互的成功应用
在大多数场景中,Talker的快速响应能够处理用户的大部分需求,而无需Reasoner的同步参与。Talker可以通过现有的信念模型生成响应,即便这些信念并非最新。此异步工作方式确保了系统的低延迟,特别是在较简单的对话任务中。
5.2 失败模式与挑战
尽管Talker-Reasoner架构在很多任务场景中表现良好,但也存在一些潜在的挑战和失败模式:
- 快判断Talker的问题
在某些情况下,Talker依赖旧的信念模型或做出过快的判断,可能会导致错误的或不完整的响应。特别是在面对需要深度推理或复杂计划的任务时,Talker可能过早响应,无法提供用户所需的详细信息。作者将这种现象称为“快速判断型Talker”,类似于人类的**快思考(System 1)**有时会做出错误的直觉性决策。
- Reasoner的延迟
Reasoner的推理过程较为缓慢,尤其是在需要多步骤计划和复杂信念更新时。虽然Talker可以在大多数情况下独立工作,但在一些复杂任务中,Reasoner的延迟会影响代理的整体表现。例如,当用户请求一个详细的多步骤计划时,Talker不得不等待Reasoner完成推理,否则可能无法生成完整的响应。
- 同步问题
由于Talker和Reasoner之间的信息共享主要依赖于记忆库,有时Talker使用的是Reasoner尚未更新的信念。这会导致Talker在某些复杂对话中的回答滞后于用户的需求,尤其是在任务的计划阶段时,这种滞后性更加明显。
5.3 未来研究方向
作者提出了几条未来可能的研究方向,以进一步完善Talker-Reasoner架构:
- 智能切换机制
未来的研究可以探索如何让Talker自动判断何时需要等待Reasoner完成推理,何时可以继续进行对话。这类似于人类在面对复杂问题时,决定是否需要慢思考(System 2)来接管快速反应。这一机制能够避免Talker在不适当的情况下做出快速判断,同时确保对话的流畅性。
- 降低Reasoner的负担
虽然Reasoner在处理复杂任务时表现出色,但其推理过程可能会拖慢整个系统。因此,未来的研究可以探索如何降低Reasoner的计算负担,让其在不影响性能的前提下,能够更快地提供推理结果。一个可能的方向是设计多个层次的Reasoner,每个层次处理不同的复杂度问题,从而优化性能。
- 多Reasoner协同工作
未来的工作可以探索多Reasoner的架构,其中每个Reasoner负责不同类型的推理任务。多个Reasoner可以写入不同的记忆片段,并相互协作以处理更复杂的问题。这种架构可以提升系统处理并行任务的能力,并改善系统在应对多维度复杂问题时的表现。
- 自动识别System 2任务
进一步的研究可以致力于开发一种机制,帮助代理自动识别何时需要进入深度推理模式(即Reasoner接管任务)。通过训练代理能够更好地识别复杂问题,Talker可以在不延迟的情况下根据任务需求做出准确的响应。
在讨论部分,作者总结了Talker-Reasoner架构的成功之处和面临的挑战。该架构在任务分配上表现出色,Talker负责快速对话,Reasoner负责深度推理。然而,Talker在复杂任务中的快速响应可能会导致错误的判断,而Reasoner的推理延迟可能影响整体性能。未来的研究方向集中于优化Talker与Reasoner的协作机制,智能判断任务的复杂性,优化Reasoner的推理性能,并探索多Reasoner系统以进一步提升代理的智能性和效率。
6. Conclusions(结论)
在论文的结论部分,作者总结了他们提出的Talker-Reasoner架构,并讨论了该架构对未来AI代理系统的启示和潜在的应用前景。通过模拟人类的“快思考”和“慢思考”系统,该架构为AI系统提供了一种更为灵活和高效的任务处理方式。
6.1 双系统架构的优势
作者强调,Talker-Reasoner架构的设计灵感来自于行为科学中的双系统理论,能够很好地平衡快速响应与复杂推理。该架构的主要优势包括:
- 模块化设计
通过将AI代理分为两个独立但互补的部分(Talker和Reasoner),系统能够根据任务的需求动态调整工作方式。Talker处理直觉性、快速响应的任务,而Reasoner负责需要深思熟虑的推理任务。这样的模块化设计提升了系统的灵活性和可扩展性。
- 减少延迟
Talker的存在使得系统能够在大多数情况下立即响应用户,无需等待复杂的推理过程。这减少了系统的响应延迟,提高了用户体验。Talker的快速反应适用于大部分日常任务,而Reasoner则只在需要时介入,确保系统在复杂任务下也能提供深度推理支持。
- 增强用户互动
通过将复杂的多步骤推理和计划交给Reasoner,Talker可以专注于与用户的自然交互。这种分工让代理能够同时保持对话的流畅性和任务处理的复杂性,从而提升了用户体验和系统的智能性。
6.2 未来工作展望
尽管Talker-Reasoner架构在当前任务中的表现令人满意,作者也指出了未来可以进一步研究和改进的方向:
- 智能判断任务复杂性
未来的研究可以探索如何让Talker自动判断任务的复杂性,并决定是否需要等待Reasoner的推理结果。通过更智能的任务分配机制,代理可以更高效地在快思考和慢思考模式之间切换。
- 多模态输入和推理
目前的系统主要基于语言输入进行对话和推理。未来的研究可以进一步探索如何将多模态数据(如视觉、听觉等)整合到代理系统中,从而增强系统的环境感知能力和推理能力。
- 扩展应用领域
:作者认为,Talker-Reasoner架构不仅适用于本文中的睡眠教练案例,还可以推广到其他需要快速反应和深度推理的领域,如健康指导、教育、任务自动化等。未来的工作可以探索如何在这些应用中有效实现Talker和Reasoner的分工合作。
- 多Reasoner系统
未来的研究可以考虑扩展到多Reasoner系统,不同的Reasoner可以专注于处理不同类型的推理任务。多个Reasoner之间的协同工作可以进一步增强系统的推理能力,尤其是在应对更复杂、多步骤的任务时。
6.3 总结
作者最终总结道,Talker-Reasoner架构提供了一种能够结合快速对话生成与复杂推理的新型AI系统设计。通过借鉴人类认知中的双系统思维理论,这一架构为大型语言模型提供了更加灵活和高效的任务处理框架。未来的研究和应用可以进一步扩展这一架构,探索其在各种复杂任务中的应用潜力。
综上所述,论文在总结部分回顾了Talker-Reasoner架构的设计理念与其实际应用表现。通过这一架构,AI代理能够在保证对话流畅性的同时,处理复杂的多步骤推理任务。作者提出了一些未来改进的方向,旨在使这一架构在更多场景中得到广泛应用。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![OpenAIo1复制之旅:旅程学习战略进展报告[O1 Replication Journey: A Strategic Progress Report – Part 1]-AI论文](https://assh83.com/wp-content/uploads/2024/11/1-Figure1-1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)