1. Introduction(介绍)
1.1 背景:链式思维推理的发展
大语言模型(LLMs)近年来在问题求解能力上取得了突破。一个特别有效的方法是链式思维推理(Chain-of-Thought, CoT),它通过生成一系列中间推理步骤(即“思维链”)来解决复杂问题。这个方法的优势在于它能够让模型逐步推理,而不是直接给出答案。这种逐步推理的方式使得模型能够处理更复杂的任务,例如算术推理和多步推理问题。
然而,尽管CoT在复杂推理任务上展现了很大的潜力,仍存在一些不足。研究表明,CoT有时会生成非最优的推理路径。这是因为CoT的推理过程只生成单一的推理链,而没有充分探索其他可能的推理路径。因此,CoT的回答有时是无意识的,或者说是“非审慎”的,因为它只关注一条推理路线,容易忽略潜在的更优路径。

1.2 思维树(ToT)的引入与挑战
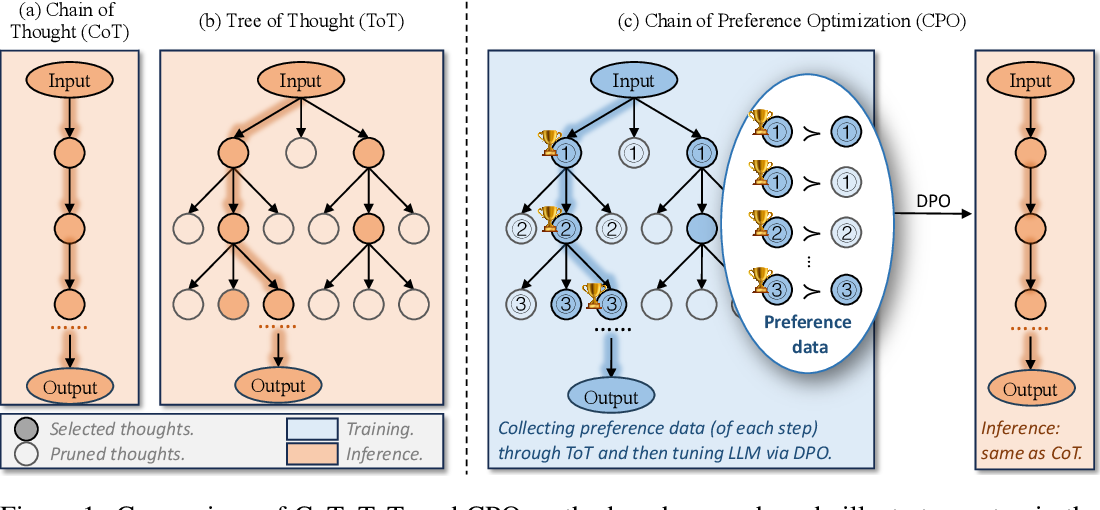
为了解决CoT的不足,研究者提出了思维树(Tree-of-Thought, ToT)方法。ToT的核心思想是,通过构建树状结构生成多个推理分支,每一步都会生成多个备选的推理路径,并进行自我评估和修剪。这种方法通过在多个推理路径中搜索最优路径,可以大大提高推理的质量,使得模型的推理更加“审慎”且“有意识”。ToT可以找到那些被CoT忽略的更优路径,从而改进问题求解。
然而,ToT的一个主要缺点是其推理复杂度显著增加。由于每一步都要生成多个分支并进行评估,ToT在推理过程中需要大量的计算资源,这限制了它的实际应用。尤其是在处理大规模模型和复杂问题时,这种高昂的计算成本变得难以忽视。
1.3 提出问题:如何在不增加推理复杂度的情况下提高性能?
为了解决CoT容易生成非最优路径以及ToT推理复杂度高的问题,论文提出了一个关键问题:“我们能否将ToT的策略深度融入CoT,从而提高其有效性,并保持推理的效率?”
这个问题的提出很重要,因为它不仅揭示了现有方法的局限性,还为新的方法探索提供了方向。为了解决这个问题,论文尝试了一种称为“偏好链优化”(Chain-of-Preference Optimization, CPO)的方法。
1.4 偏好链优化(CPO)的方法
论文引入了一种新的优化策略:偏好链优化(CPO)。CPO的核心思想是通过从ToT生成的树结构中提取偏好信息,指导CoT的推理路径选择。具体来说,ToT在推理过程中生成了多个候选路径,并对它们进行了评估和修剪。CPO则利用这些评估结果,将每一步的推理分支划分为优选路径和次优路径。这种偏好信息能够指导模型在未来的推理中更优先地选择最优路径,从而提高性能。
通过使用偏好信息进行微调,CPO能够让CoT的推理路径与ToT生成的最优路径对齐,但无需在推理时进行复杂的树搜索。这大大降低了推理的复杂性,使模型既能保持高效的推理速度,又能获得与ToT相媲美的推理质量。
1.5 实验结果与结论
为了验证CPO的有效性,论文通过一系列实验测试了该方法在多种复杂任务中的表现。这些任务包括问答(QA)、事实验证、以及算术推理。实验结果表明,CPO在这些任务中显著提升了LLMs的推理性能,平均提升了4.3%的准确率,并且推理速度比ToT快了约50倍。
总结
在介绍部分,论文明确指出了现有的CoT和ToT方法的优缺点,并提出了偏好链优化(CPO)作为一种能够在不增加推理复杂度的前提下,显著提升模型推理能力的新方法。CPO结合了ToT的策略深度与CoT的高效性,为大语言模型的推理带来了更好的性能和效率。
2. Related Work(相关工作)
在这一章节中,论文总结了与其研究密切相关的前人工作,主要分为以下几个方向:
2.1 LLMs的推理能力(Reasoning with LLMs)
近年来,大语言模型(LLMs)的多步推理能力得到了广泛关注,尤其是在需要复杂思维和推理的任务中表现突出。相关的研究集中在如何提升LLMs生成推理路径的能力,并且有几种主要的改进方法:
- 链式思维(Chain-of-Thought, CoT)推理
CoT推理通过生成一系列中间推理步骤,让模型可以逐步得到最终答案。这种方法提升了模型在复杂推理任务中的表现,因为它帮助模型通过多个步骤逐步构建逻辑思路。
- 推理路径的改进
一些研究尝试通过后期编辑或利用外部知识来改进CoT生成的推理路径。例如,模型可以通过外部知识库验证或调整推理路径,从而得到更准确的结果。然而,这些方法往往依赖于外部资源或额外的计算步骤。
- 非线性推理结构
与传统的线性推理路径不同,一些研究提出了非线性的推理结构,如树状或图状结构。例如,Tree-of-Thought(ToT)方法通过树搜索算法扩展模型的推理路径,但这种方法增加了推理过程的复杂性。论文提到,尽管这些方法能够提升推理质量,但它们都需要在推理过程中进行复杂的搜索操作,这导致了推理延迟的显著增加。
2.2 LLM自我改进(LLM self-improving)
大语言模型的自我改进近年来成为一个重要的研究方向,尤其是借助于强化学习(Reinforcement Learning, RL)的技术,通过人类反馈进行自我调整。主要方法包括:
- 强化学习与人类反馈结合(RLHF)
RLHF方法将LLMs视为强化学习的代理,结合人类反馈进行训练。具体做法是让模型通过多轮反馈不断调整生成的结果,从而使其更符合人类期望。
- 自我生成数据
为了增强模型的微调效果,越来越多的研究提出让LLMs生成自我监督的数据。例如,通过“自我奖励”机制,模型可以自行生成数据并进行评估,迭代地提升推理和生成的质量。然而,这些方法通常依赖于外部的奖励模型,或需要大量的人类标注数据。
- 无标注数据的自我学习
一些方法提出模型可以在没有标注数据的情况下,利用自我生成的反馈来改进。例如,通过模型自身的推理能力生成反馈信号,模型能够在没有外部奖励模型的情况下进行自我改进。这些方法和本论文中的偏好链优化(CPO)方法类似,都试图减少对人工标注的依赖。
2.3 大语言模型中的蒙特卡罗树搜索(Monte Carlo Tree Search for LLMs)
蒙特卡罗树搜索(Monte Carlo Tree Search, MCTS)是一种用于复杂决策环境中的强大算法,最著名的应用是战略性棋类游戏,如AlphaGo。近年来,MCTS也被引入大语言模型的推理中,以提升其决策和推理能力。MCTS的核心是通过不断扩展和评估不同的决策路径,找到最优解。
- MCTS在LLMs中的应用
MCTS可以帮助LLMs在推理时生成多个推理分支,并通过模拟不同的结果更新其选择路径。论文指出,虽然MCTS在提高模型推理质量上效果显著,但它的一个主要问题是推理延迟过高。每次推理时模型都需要生成和评估大量的分支,导致计算和内存开销极大。
- 路径优化与监督学习结合
一些研究试图通过将MCTS生成的推理路径用于监督学习微调模型。这种方法虽然可以提升模型在推理路径上的选择能力,但同样面临标注数据依赖或推理时间过长的问题。
论文提出,偏好链优化(CPO)能够在训练阶段充分利用MCTS生成的推理路径信息,而避免推理阶段的高昂成本,从而在推理速度和质量之间取得良好的平衡。
2.4 其他相关方法总结
除了上述三大领域,论文还讨论了其他与本研究相关的方法:
- 推理链的优化
现有一些方法关注如何通过优化模型的推理链来提升性能,譬如通过蒙特卡罗树搜索(MCTS)结合深度优先搜索(DFS)的方法来发现最优路径。然而,这些方法大多在推理阶段增加了计算量,不利于实际应用。
- 直接偏好优化(Direct Preference Optimization, DPO)
DPO是通过偏好数据直接优化语言模型的一种方法。与传统的RLHF不同,DPO将偏好反馈建模为优化问题,模型通过最大化偏好路径的概率,逐步调整生成结果。CPO借鉴了DPO的思想,但进一步优化了偏好信息在推理路径中的应用。
总结
这一章节回顾了与LLMs推理、路径优化、自我改进及MCTS在推理中的应用等领域的前沿研究。CPO方法在此基础上提出了一种新的优化方式,通过将MCTS生成的偏好数据用于微调模型,在保持推理效率的前提下提升推理质量,克服了现有方法中推理复杂度过高或数据依赖性强的不足。
3. Background(背景)
这一章节为理解论文提出的偏好链优化(CPO)方法提供了理论基础,主要介绍了现有的推理策略以及论文依赖的关键技术。主要分为以下几个部分:
3.1 Chain-of-Thought Prompting(链式思维提示)
链式思维提示(Chain-of-Thought, CoT)是一种用于大语言模型(LLMs)的推理方法,旨在通过逐步生成中间推理步骤,构建一条逻辑推理链。这个方法的核心是,在得到最终答案之前,模型会生成一系列的中间“思维节点”(thoughts),并通过这些节点逐步推导出最终的结论。
CoT的具体流程如下:
- 输入一个问题或任务时,模型会逐步生成多个“中间推理步骤”。
- 每个步骤都代表一个逻辑推理的部分,最终串联起整个推理过程。
- 最终答案不是直接从输入到输出,而是通过中间推理节点逐步生成,形成一条推理链。
例如,对于一个算术推理问题,输入是一个问题(如“2+3等于多少?”),模型会先生成步骤1(“2+3等于5”),然后生成最终答案5。CoT通过逐步推理增强了模型解决复杂问题的能力。
然而,论文指出CoT的局限性在于它只生成单一路径的推理。这种方式尽管直观,但可能会忽略更优的推理路径,尤其是在模型选择的推理链不是最优时,容易导致错误的最终结果。
3.2 Tree-of-Thought Prompting(思维树提示)
为了弥补CoT方法的不足,思维树提示(Tree-of-Thought, ToT)通过构建树状结构,使模型能够探索多条推理路径。与CoT不同,ToT每一步都生成多个可能的推理分支,这些分支通过自我评估进行筛选,从而找到最优的推理路径。

ToT的推理过程分为两个主要部分:
- 思维生成器(Thought Generator)
在每一步推理中,模型不仅生成一个推理节点,而是生成多个候选节点,形成多个分支。这些分支表示不同的推理路径,模型需要从中选择最优路径。
- 状态评估器(State Evaluator)
模型会对生成的每个推理节点进行评估,为每个分支打分,并选择得分最高的分支继续推理。剩下得分较低的分支会被修剪掉。
最终,ToT通过广度优先搜索(BFS)或深度优先搜索(DFS)等算法,选择最佳路径,直到推理过程结束。与CoT相比,ToT的优势在于它可以在推理空间中进行更全面的搜索,从而找到更好的解法。
但ToT的缺点也很明显:它显著增加了推理的计算复杂度和延迟。因为每一步生成多个分支,ToT在推理时需要额外的计算资源,因此在大规模应用中,效率问题成为一大瓶颈。
3.3 Direct Preference Optimization(直接偏好优化)
直接偏好优化(Direct Preference Optimization, DPO)是一种基于偏好数据优化语言模型的技术。传统的强化学习从人类反馈(RLHF)方法通过模拟奖励机制,优化模型的生成能力,而DPO将偏好建模为一个直接优化问题,使模型能通过最大化偏好生成路径的概率,来调整其输出。
DPO的流程如下:
- 模型生成多个候选路径,并通过偏好反馈进行排序。
- 偏好的路径(即模型认为较优的路径)被赋予更高的概率,模型的目标是最大化偏好路径的生成概率,同时最小化不受偏好路径的生成概率。
与RLHF的区别在于,DPO省去了构建复杂的奖励模型的步骤,而是直接通过优化偏好路径与非偏好路径之间的生成概率差异来进行模型调整。
CPO方法受DPO启发,将偏好数据应用到推理的每一个步骤中,通过推理过程中的多步偏好选择,逐步优化模型的推理路径选择。
4. Our Method: Chain of Preference Optimization(我们的方法:偏好链优化)
这一章节是论文的核心部分,详细介绍了偏好链优化(Chain of Preference Optimization, CPO)方法的原理及其实现步骤。CPO的目标是在推理过程中,通过将链式思维(CoT)的高效性和树式思维(ToT)的策略深度结合起来,提升模型的推理能力,同时保持推理效率。下面是该章节的详细解读:
4.1 Synthesizing the Chain of Preference Thoughts(偏好思维链的合成)
CPO的关键步骤是通过ToT生成的推理路径,提取偏好信息,并利用这些信息优化语言模型的推理能力。
- 思维生成(Thought Generation)
在每一个推理步骤中,CPO会生成多个推理候选项(思维)。例如,在某个推理步骤下,输入为部分推理链(例如思维链中的前几个节点),此时模型会生成若干个新的推理节点作为下一步的候选项。模型通过CoT的提示生成这些候选项,并且这些候选项代表不同的推理分支。
对于每一个输入,CPO生成的推理节点的数量为 k,这意味着在每个推理步骤中,模型生成多个备选节点,而不是像CoT那样只生成一个节点。
- 状态评估(State Evaluation)
对于生成的每个推理节点,模型通过自我评估机制来打分,以决定这些候选节点的优劣。评估过程由模型自己完成,不需要外部的奖励模型或人工标注数据。模型根据这些推理节点是否有助于回答原始问题,给出“可能的”或“不可能的”评估,从而为每个推理节点赋予不同的分数。
评估过程的结果是为每个节点分配一个分数,这些分数用于后续的修剪和优化过程。
- 搜索与收集(Search and Collection)
在生成多个思维节点并对其评估之后,模型会进行搜索,以选择最佳的推理路径。搜索算法通常采用广度优先搜索(BFS)或深度优先搜索(DFS),根据评估分数选择得分最高的若干个推理节点,保留这些节点并继续扩展推理路径。分数较低的节点会被修剪掉。
一旦模型找到了最优推理路径,整个推理过程就会结束。在这一过程中,CPO不仅保留了最终的最优路径,还保留了其他被生成但未被选中的次优路径。这些次优路径提供了额外的“偏好信息”,帮助模型更全面地理解推理过程中的选择。
- 构建偏好对(Constructing Preference Pairs)
CPO的创新之处在于,它利用了ToT生成的多条推理路径,并将它们构建为偏好对。具体来说,在每一步推理中,ToT会生成多个推理节点,并对它们进行打分。模型根据这些分数,将最优路径中的节点标记为“优选路径”,而其他路径则被标记为“次优路径”或“非偏好路径”。
偏好对是通过比较优选路径和次优路径的分数构建的。每个优选路径节点都会与其同层的次优节点进行配对,形成一个偏好对。在这个过程中,CPO生成了一组偏好数据,这些数据在训练阶段用于优化模型的推理能力。
4.2 Training with the CPO Objective(使用CPO目标进行训练)
CPO方法的核心目标是使用偏好信息优化模型,使模型更倾向于生成符合ToT最优路径的推理结果。这个过程借鉴了**直接偏好优化(Direct Preference Optimization, DPO)**的思想,通过对偏好对进行优化,调整模型的推理过程。CPO的训练目标包括以下几个步骤:
- 偏好对的生成概率
对于每一步推理中的优选路径和次优路径,模型的目标是最大化优选路径的生成概率,并最小化次优路径的生成概率。假设在推理的第 i 步,优选路径节点的生成概率为 πθ(z_wi|x, s_wi−1),次优路径节点的生成概率为 πθ(z_li|x, s_wi−1),其中 z_wi 和 z_li 分别表示优选节点和次优节点,s_wi−1 表示该节点之前的推理状态。
- 优化目标函数(Objective Function)
CPO的优化目标是使模型更倾向于生成优选路径。具体来说,CPO通过最大化优选路径和次优路径生成概率之间的对数差异来优化模型。这个目标函数可以表示为:

其中 σ 是逻辑函数,β 是控制偏差的超参数,πref 是基准模型的生成概率。这个公式的意义在于,它通过调节优选路径与次优路径的生成概率,使模型更偏向于生成优选路径。
- CPO目标函数的整体优化
CPO最终的优化目标是基于所有偏好对的数据集进行的。在训练过程中,模型从每一步推理中学习偏好信息,并调整其生成策略。通过对所有步骤中的偏好对进行优化,模型逐步学会在推理过程中选择最优路径,而不是次优路径。
完整的CPO目标函数可以表示为:上图公式4.
这个目标函数通过对整个推理链中的偏好对进行优化,确保模型在每一步都能生成最优路径。
CPO方法的优点
- 高效性:相比于ToT在推理阶段的高计算成本,CPO将大部分计算量移到了训练阶段,从而在推理时保持与CoT相似的低延迟。
- 更优的推理能力:通过利用ToT生成的偏好数据,CPO能够让模型在推理过程中做出更好的决策,提升推理的准确性和质量。
- 避免过度依赖标注数据:CPO不依赖于大规模的人工标注数据,而是利用自我生成的偏好对进行训练。这使得该方法更容易推广到不同的任务中。
总结
在这一章节中,论文详细介绍了CPO的实现原理和优化目标。通过结合链式思维和树式思维,CPO能够在保持推理效率的同时,显著提升模型的推理能力。CPO通过在每一步推理中生成偏好对,并基于这些偏好对进行优化,使模型逐步学会选择更优的推理路径,从而克服了现有方法中存在的推理效率和质量之间的权衡问题。
5. Experiments(实验)
在本章中,论文通过一系列实验验证了所提出的偏好链优化(CPO)方法的有效性。实验设计涉及多种复杂任务,包括问答(QA)、事实验证和算术推理。CPO的性能被与现有的链式思维(CoT)和树式思维(ToT)方法进行了对比。该部分主要包括实验的设置、总体结果、以及各个组件的详细评估。
5.1 Settings(实验设置)
任务与评估指标
实验涵盖了三个类型的推理任务:
- 问答任务(QA):包括三个常用的数据集——Bamboogle、WikiMultiHopQA和HotpotQA。
- 事实验证任务:使用了三个数据集——Fever、Feverous和Vitaminc。
- 算术推理任务:使用了SVAMP数据集,用于评估模型的算术推理能力。
每个数据集使用4-shot提示(即给模型提供四个示例),并且这些CoT示例是通过手工构建的。为了评估模型性能,实验报告了准确率(accuracy)和每个实例生成答案的平均推理延迟(latency)。
基线模型
为了验证CPO的有效性,论文设置了以下基线模型进行比较:
- CoT:该方法让模型在生成最终答案之前生成一系列推理步骤。使用贪心解码评估模型的推理能力,且不进行任何微调。
- ToT:该方法要求模型通过树搜索探索多个推理路径,生成最终答案。ToT也用于生成推理路径以进行微调。
- TS-SFT:基于ToT生成推理路径后,使用这些路径进行有监督的微调(Supervised Fine-Tuning, SFT),提升模型的推理能力。
实验细节
实验基于三种大语言模型:LLaMA2-7B、LLaMA2-13B和Mistral-7B。为了高效微调,使用了低秩适配(Low-Rank Adaptation, LoRA)方法。在实验中,DPO和SFT的学习率分别设为5e-6和1e-5,批次大小为32,使用AdamW优化器,并在NVIDIA A100 GPU上运行。为了防止过拟合,实验采用了早停(early stopping),并多次重复实验以消除随机性带来的影响。
5.2 Overall Results on Reasoning(推理总体结果)

实验结果表明,CPO在推理任务上表现出色,并有以下几个主要发现:
- CPO显著提升了LLMs的推理能力
CPO使得基础模型的推理能力提升了平均4.3%,在某些任务中提升幅度最大达9.7%。这表明CPO能够有效提高模型在复杂推理任务中的表现,尤其是在没有额外人工标注数据的情况下,CPO通过偏好信息实现了性能的提升。
- CPO在推理延迟上显著优于ToT
尽管ToT通过树搜索改进了推理路径,模型的推理质量有所提升,但其计算复杂度非常高,导致推理延迟增加。相比之下,CPO将复杂计算移到了训练阶段,保持了与CoT相似的推理延迟,同时取得了与ToT相当甚至更优的性能。CPO的推理速度比ToT快57.5倍,说明其在效率上具有极大优势。
- CPO的表现优于TS-SFT
尽管CPO和TS-SFT都使用ToT生成的推理路径进行训练,CPO表现出更好的推理能力。CPO能够利用ToT过程中的优选和次优思维路径,全面提升推理能力,而TS-SFT只利用了ToT发现的最终最佳路径。
5.3 Component-wise Evaluations(逐项评估)

论文还进行了组件层面的详细评估,分析了不同策略对模型性能的影响:
- 不同的次优路径选择方法对模型性能的影响
实验对比了三种不同的次优路径选择策略:最低评分策略(CPO w/ Lowest)、较低评分策略(CPO w/ Lower)以及所有次优路径策略(CPO w/ All)。结果表明,CPO w/ All表现最佳,这表明在每一步推理中利用所有非最优路径的偏好信息,能够更好地指导模型优化。
- 训练数据量的影响

实验还评估了不同训练数据量对CPO性能的影响。结果显示,当训练数据量较小时,模型容易过拟合,导致性能下降。但随着训练数据量的增加,模型性能逐步提升,直到达到一定数据量后,模型性能趋于稳定。最佳的效果是在使用约120个实例时达到。

- 不同类型训练数据的影响
实验表明,混合类型的数据训练有助于提升CPO的性能。通过将不同类型任务的数据(如QA任务、事实验证任务等)混合训练,CPO在多个任务上都表现出性能提升。
- 次优路径信息对优化过程的重要性
实验显示,随着次优路径数据在训练中的比例增加,模型的性能不断提高,这表明次优路径数据在优化过程中起到了至关重要的作用,能帮助模型更好地识别出最优推理路径。
6. Analysis(分析)
在本章节中,论文对偏好链优化(CPO)方法的关键优势进行了深入的分析,并探讨了其在推理中的表现。作者重点讨论了为何CPO能在推理效率和质量之间取得平衡,以及其在优化推理路径中的独特性。分析内容主要分为两个方面:链级别优化的重要性和迭代学习的好处。
6.1 链级别优化的重要性(Why is chain-level optimization important?)

作者首先对CPO方法的一个核心优势进行了详细的阐述——链级别的偏好优化。在CPO中,偏好信息是在每一步推理中生成的,这与传统的全路径优化方法有显著区别。为了说明这一点,论文比较了两种不同的偏好优化方法:
- 全路径偏好优化(Full-path Preference Optimization, FPO)
- 链级别偏好优化(Chain-of-Preference Optimization, CPO)
实验验证
论文通过实验进一步验证了链级别优化的有效性。在一系列推理任务上,CPO相较于FPO有显著的性能提升。在某些任务上,FPO的表现甚至不如简单的有监督微调(SFT),这表明全路径优化方法可能会因为梯度抵消问题而导致性能下降。而CPO则通过逐步优化解决了这一问题,表现出了更强的推理能力。
6.2 迭代学习的好处(CPO Benefits from Iterative Learning)
CPO的另一个关键优势在于它能够从迭代学习中受益,逐步提升模型的推理性能。论文探讨了CPO如何通过多轮迭代训练,不断增强模型的推理能力。具体来说,作者分析了两种不同的迭代训练策略:
- SFT + CPO 迭代训练
- CPO-only 迭代训练
推理路径的多样性与优化
论文还探讨了推理路径的多样性对迭代训练的影响。实验结果显示,随着迭代次数增加,CoT推理路径和ToT推理路径的性能趋于一致。随着模型逐渐变得更精确,其推理路径的多样性降低,这可能导致ToT方法在后期的迭代训练中不再具有明显的优势。作者推测,这种现象可能是因为模型的输出变得更加一致,导致ToT的搜索空间收缩。
6.3 迭代训练与推理时间的权衡
尽管CPO的迭代训练能够逐步提升模型的推理性能,但作者也指出了推理时间和性能提升之间的权衡问题。在CPO的迭代训练过程中,随着模型的推理路径变得更优,其推理速度保持稳定,甚至在某些情况下有所提高。这是因为CPO通过训练阶段的优化,减少了推理过程中不必要的路径搜索步骤,从而在提升推理质量的同时保持了推理效率。
相比之下,ToT方法的推理时间随着推理质量的提升而显著增加,这使得CPO在推理效率上具有显著优势。
总结
在分析章节中,论文深入探讨了CPO在推理路径优化中的独特优势,并通过实验验证了链级别优化的重要性。通过逐步生成和优化偏好对,CPO有效地避免了全路径优化中梯度抵消的问题,确保了每一步推理节点都能被充分优化。CPO还展示了通过迭代训练逐步提升模型性能的能力,并在推理效率和推理质量之间取得了良好的平衡。
7. Conclusion(结论)
论文总结了CPO的优势,强调了其在提升LLMs推理能力的同时,不增加推理复杂度的优点。通过引入ToT生成的偏好信息,CPO能够有效优化模型的推理路径,使其既能保持高效的推理速度,又能提升推理的准确性。实验结果证明了CPO的有效性,展示了它在多个复杂任务中的优越表现。
此外,论文也为未来的研究方向提出了建议,认为可以将CPO与其他推理算法(如思维图Graph-of-Thoughts)结合,进一步提升LLMs的推理能力。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)