这篇论文的标题是《ReST-MCTS∗: LLM Self-Training via Process Reward Guided Tree Search》,论文的主要内容涉及使用蒙特卡洛树搜索(MCTS)算法引导大型语言模型(LLM)进行自我训练。
1. 介绍 (Introduction)

在论文的介绍部分,作者首先讨论了当前大型语言模型(LLM)自我训练的背景和局限性。现有的自我训练方法大多依赖于让LLM生成多个答案,并从中筛选出正确答案,将其作为进一步微调的训练数据。然而,作者指出这种方法存在一些显著的问题:
- 低质量的训练数据集
:大多数自我训练方法通过筛选正确答案来构建训练集,但这并不能保证训练集中的推理过程都是正确的。换句话说,虽然模型可能在一些问题上得到了正确的最终答案,但中间推理步骤可能是错误的或无用的。这种情况会导致训练集包含大量错误的中间推理步骤,影响最终模型的推理能力。
- 人工标注的缺乏
:许多推理步骤的正确性验证依赖于人工标注(如过程奖励模型中的每一步推理都需要人为标记),而这种方式显然难以扩展,因为手动标注既耗时又昂贵。
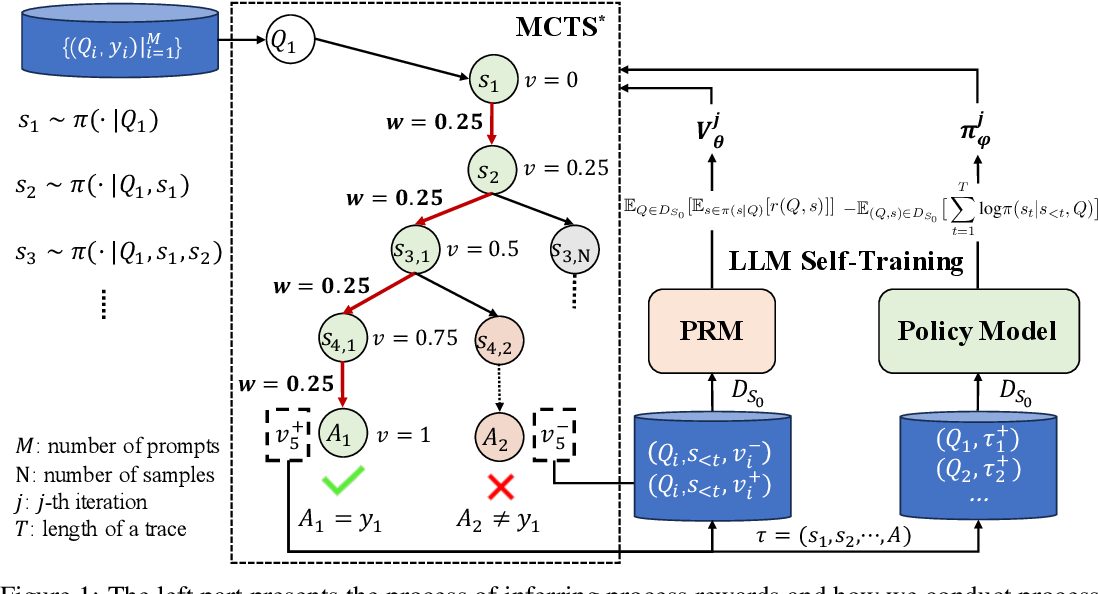
为了解决这些问题,作者提出了ReST-MCTS∗(Reinforced Self-Training with Monte Carlo Tree Search),这是一种基于强化学习的自我训练方法,通过树搜索结合过程奖励的引导来提高训练数据的质量。以下是ReST-MCTS∗方法的关键点:
- 过程奖励(Process Reward)引导
:与传统的强化学习不同,ReST-MCTS∗通过自动推导出正确的过程奖励,而不再依赖每一步人工标注。具体来说,ReST-MCTS∗可以在给定最终正确答案的情况下,推测每个推理步骤是否有助于最终正确答案的生成。这些推导出的奖励可以用作两个目的:
- 蒙特卡洛树搜索(MCTS∗)的应用
:ReST-MCTS∗通过集成树搜索算法,在同样的搜索预算下,相比于现有的推理基线(如Best-of-N或Tree-of-Thought),能够找到更高质量的推理路径。
- 多轮次迭代训练
:ReST-MCTS∗不仅通过树搜索策略提高推理路径的质量,而且还能够通过反复迭代,不断使用这些推理路径作为训练数据,逐步增强模型。这种迭代的过程允许模型在每次训练后自我改进,超越其他自我训练算法(如ReSTEM和Self-Rewarding LM)。
作者还展示了该方法的实验结果,表明ReST-MCTS∗在多种推理任务中,尤其是数学推理和科学推理任务中,显著优于现有的自我训练方法。最后,作者将代码开源,供社区研究使用【5†source】。
总结:
- 现有问题:LLM自我训练方法容易导致低质量的推理路径,且过于依赖人工标注。
- ReST-MCTS∗的贡献:通过引入树搜索和自动推导的过程奖励,避免人工标注,并筛选高质量的推理路径,从而实现更高效的模型自我训练。
2. 推理与自我训练的背景 (Background on Reasoning & Self-Training)
在本节中,作者对大型语言模型(LLM)推理和自我训练的背景进行了详细讨论,介绍了现有推理方法的关键概念以及自我训练中的挑战。
2.1. LLM推理策略
LLM推理的基本方法是从一个问题输入开始,逐步生成推理路径,直到得出最终答案。该过程类似于自动回归模型生成下一步内容。推理路径中的每一步(称为推理步骤)可以通过模型预测生成。
推理策略可以通过各种方法进行优化,以下是几种常见的推理策略:
1.链式推理 (Chain-of-Thought, CoT):
– 这种方法旨在通过让模型生成每一步的推理过程,从而提高模型的推理能力。每个推理步骤是一句话,这种链式结构让模型能够模拟人类的思维过程,从而更好地回答复杂问题。
– CoT方法不仅考虑最终答案的正确性,还重视生成推理路径的质量。
2.自我一致性 (Self-Consistency, SC):
– 自我一致性是一种常用的推理策略,它通过对同一个问题生成多个推理路径,并选择其中出现最频繁的答案作为最终答案。这种方法能够有效提高模型的可靠性。
– SC依赖于模型生成多个推理路径,并通过对比多个路径来选择最优解,从而提高推理的稳定性和一致性。
3.树搜索与价值函数 (Tree-Search & Value Function):
– 树搜索是一种探索性更强的推理策略,它允许模型在推理过程中分支和扩展不同的推理路径。为了应对庞大的搜索空间,树搜索算法通常需要一个价值函数来指导搜索过程,帮助模型找到最优的推理路径。
– 有两类常用的价值函数:
– 结果奖励模型 (Outcome Reward Model, ORM):这种模型只对最终答案的正确性进行打分,忽略推理路径的中间步骤。
– 过程奖励模型 (Process Reward Model, PRM):这种模型会对每个推理步骤进行评分,根据推理过程中的每一步是否正确来引导模型。
– 这些模型通过结合价值函数,能有效评估和筛选出高质量的推理路径。
4.Best-of-N:
– 该策略与自我一致性相似,但它依赖于通过预先训练的价值函数(如ORM或PRM)来从N个生成的推理路径中选择得分最高的那条路径。这种方法通过机器学习模型的评分机制来选择最优路径。
2.2. LLM自我训练方法
LLM自我训练的高层流程主要包括两个步骤:
1.生成步骤:
– 在生成步骤中,模型根据输入问题生成多个推理路径。每个路径代表了一条可能的解答途径。在ReST-MCTS∗中,推理路径是通过树搜索生成的结构化推理路径。
2.改进步骤:
– 生成推理路径后,下一步就是改进模型。通过对比生成的推理路径,构造一个学习信号来帮助模型自我提升。在ReST-MCTS∗中,这个过程是通过训练奖励模型和策略模型来完成的,模型会根据生成的推理路径进行微调,并在多个迭代中不断改进。
2.3. 现有工作的局限性
作者指出,现有的自我训练方法在构建有效的学习信号时面临着很大的挑战。以下是几种常见的局限性:
1.稀疏的学习信号:
– 理想情况下,模型希望获得关于每个推理步骤是否正确的密集学习信号。然而,由于缺乏细粒度的标注,大多数方法只能依赖稀疏的学习信号(如最终答案的正确性)。这类似于强化学习中的“信用分配问题”,即难以将奖励正确地分配到中间推理步骤。
2.人工标注的依赖:
– 许多过程奖励模型需要依赖人工标注来为每一步推理生成正确与否的标签,这显然无法扩展。获取大规模的人工标注不仅耗时耗力,还难以覆盖所有任务的多样性。
2.4. ReST-MCTS∗方法的创新
作者强调,ReST-MCTS∗方法旨在解决上述局限性。通过使用自动化的奖励模型,ReST-MCTS∗能够在无需人工标注的情况下生成高质量的推理路径,并且通过树搜索算法有效地筛选最优路径。这种方法不仅能生成更好的学习信号,还能在多个迭代中不断改进模型的推理能力。
总结:
- 推理策略:作者讨论了现有的推理方法,如链式推理、自我一致性、树搜索等。
- 自我训练方法:自我训练包含生成和改进两个步骤。生成推理路径后,模型通过不断微调,逐步改进推理能力。
- 现有方法的局限性:现有方法面临学习信号稀疏和依赖人工标注等问题,难以大规模应用。
- ReST-MCTS∗的贡献:该方法通过树搜索结合自动化奖励模型,有效解决了这些问题,能够在没有人工标注的情况下生成高质量推理路径。
3. ReST-MCTS∗ 方法 (The ReST-MCTS∗ Method)
在这一章节,作者详细介绍了ReST-MCTS∗方法的结构和关键技术细节。该方法旨在通过结合蒙特卡洛树搜索(MCTS∗)和过程奖励模型,改进大型语言模型(LLM)的自我训练流程。整个方法的核心在于自动生成高质量的推理路径,并将这些路径用于持续改进LLM的推理能力。
3.1 基于搜索的LLM推理策略 (Search-based Reasoning Policy for LLM)
这一节介绍了ReST-MCTS∗的推理策略,它结合了树搜索与过程奖励模型,旨在生成高质量的推理路径。
6. 结论 (Conclusion)
在结论部分,作者总结了ReST-MCTS∗方法的贡献与优越性,并展望了未来可能的改进方向。
1. 方法总结
ReST-MCTS∗是一个基于蒙特卡洛树搜索(MCTS)和过程奖励模型的自我训练框架,旨在通过自动化生成高质量的推理路径,提升大型语言模型(LLM)的推理能力。该方法有以下几个关键贡献:
- 过程奖励指导的树搜索:通过MCTS∗的搜索策略,ReST-MCTS∗能够根据推理路径的过程奖励自动生成高质量的推理路径。这使得推理过程不再依赖人工标注,节省了大量的人力成本。
- 高质量的推理路径生成:ReST-MCTS∗能够自动标注推理路径的质量,并通过过程奖励模型选择最优路径用于训练,从而显著提高推理准确性。
- 多轮次的自我训练:通过反复迭代使用树搜索生成的推理路径,ReST-MCTS∗实现了持续的自我改进,能够在多个推理任务上超越现有的自我训练方法(如ReSTEM和Self-Rewarding LM)。
2. 实验结果总结
在多个实验中,ReST-MCTS∗在数学推理和科学推理任务上表现优异,尤其是在SciBench和MATH等基准测试中展现了卓越的性能。实验结果显示,ReST-MCTS∗能够在相同的搜索预算下,生成比其他推理方法(如Best-of-N和Self-Consistency)更高质量的推理路径,并且随着自我训练的迭代次数增加,模型的性能不断提升。
3. 未来工作与局限性
作者在结论部分还指出了ReST-MCTS∗的一些局限性以及未来可以改进的方向:
- 扩展到其他推理任务
:目前,ReST-MCTS∗主要在数学和科学推理任务中展示了其优势,未来工作可以将该方法推广到其他推理任务,如编码、对话等领域,特别是那些没有明确地面真值(ground truth)的任务(如对话生成和软件工程任务)。
- 任务泛化能力的提升
:尽管ReST-MCTS∗在数学和科学领域表现优异,作者建议未来的研究应探讨该方法是否能够在其他领域中具有同样强的泛化能力。
- 模型的规模化与在线RL算法
:未来研究可以进一步扩展ReST-MCTS∗的规模,使其能处理更大规模的数据集和模型。此外,在线强化学习算法的引入可能有助于提高价值模型和策略模型的自我训练能力。
- 数据筛选技术的改进
:目前的自我训练流程依赖于树搜索生成的推理路径,未来的研究可以进一步改进数据筛选技术,使模型能够更高效地过滤低质量路径,进一步提高模型的推理效率。
结论总结
ReST-MCTS∗通过结合过程奖励模型和蒙特卡洛树搜索,在大型语言模型的自我训练领域做出了创新。该方法不仅能够生成高质量的推理路径,而且通过多轮次的迭代训练,实现了LLM推理能力的持续提升。实验结果证明了该方法在数学和科学推理任务上的优越性。尽管ReST-MCTS∗表现出色,作者也指出了该方法在任务扩展、泛化能力和在线强化学习等方面的改进方向,表明未来仍有许多潜在的优化空间。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![OpenAIo1原理解读:偏好链优化:改进LLMs中的思维链推理[Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs]-AI论文](https://assh83.com/wp-content/uploads/2024/10/2-Figure1-1-75x75.png)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)