1 摘要
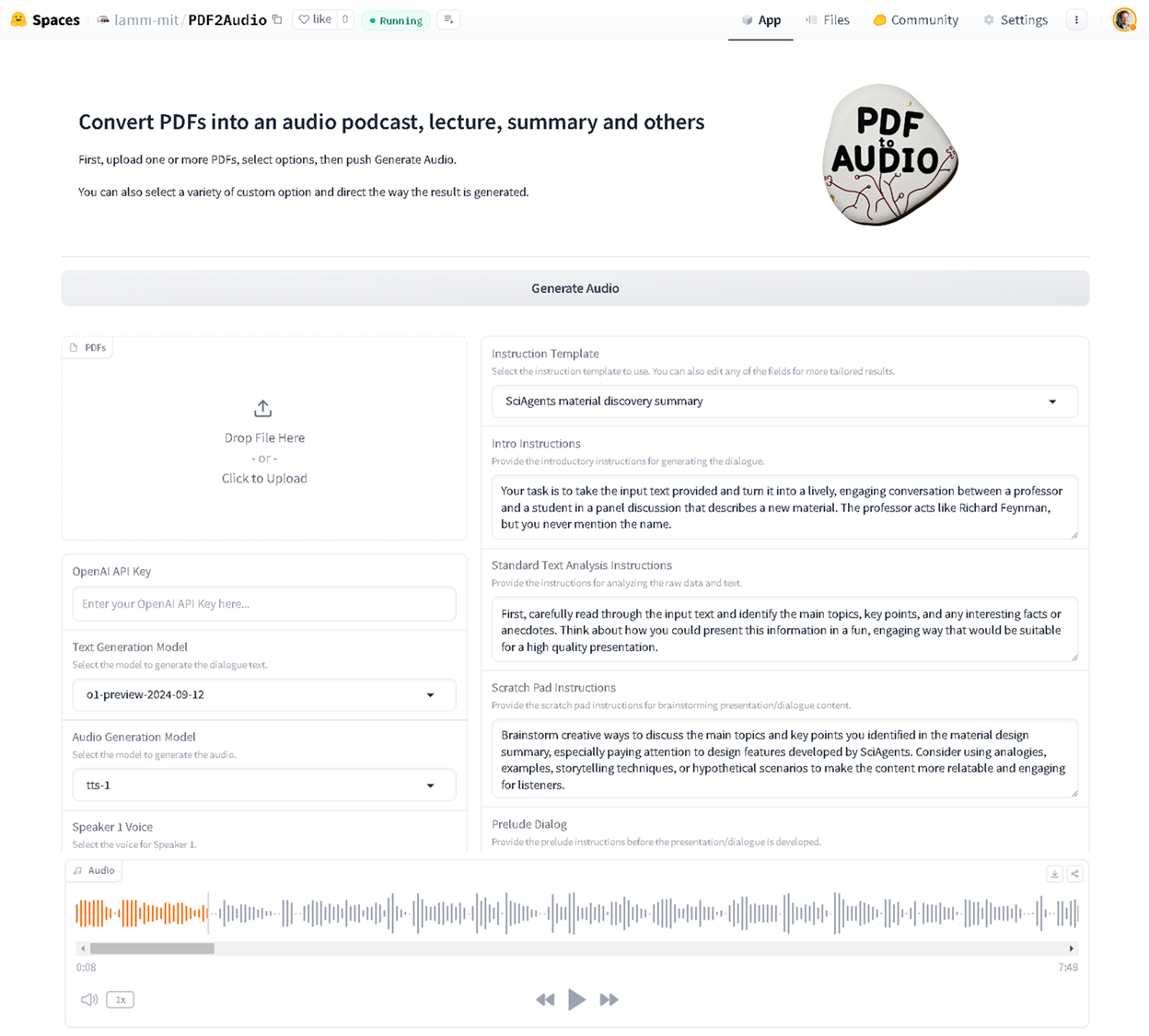
此代码可用于将 PDF 转换为音频播客、讲座、摘要等。它使用 OpenAI 的 GPT 模型进行文本生成和文本到语音的转换。您还可以编辑草稿记录(多次)并提供具体评论或有关如何调整或改进它的总体指示。

2 特征
- 上传多个 PDF 文件
- 从不同的教学模板(播客、讲座、摘要等)中进行选择
- 自定义文本生成和音频模型
- 为说话者选择不同的声音
- 通过具体或一般性评论对草稿进行迭代,和/或对记录进行编辑,并对模型进行具体反馈以进行改进
3 在 Colab 中使用
4 本地安装
按照以下步骤使用 Conda 在本地机器上设置 PDF2Audio:
- 克隆存储库:
git clone https://github.com/lamm-mit/PDF2Audio.git cd PDF2Audio - 安装 Miniconda(如果还没有):
- 从Miniconda 网站下载安装程序
- 按照操作系统的安装说明进行操作
- 验证安装:
conda --version - 创建一个新的 Conda 环境:
conda create -n pdf2audio python=3.9 - 激活 Conda 环境:
conda activate pdf2audio - 安装所需的依赖项:
pip install -r requirements.txt - 设置您的 OpenAI API 密钥:
.env在项目根目录中创建一个文件并添加您的 OpenAI API 密钥:OPENAI_API_KEY=your_api_key_here
5 运行应用程序
要运行 PDF2Audio 应用程序:
- 确保您位于项目目录中并且您的 Conda 环境已激活:
conda activate pdf2audio - 运行启动 Gradio 界面的 Python 脚本:
python app.py - 打开您的网络浏览器并转到终端提供的 URL(通常为
http://127.0.0.1:7860)。 - 使用 Gradio 界面上传 PDF 文件并将其转换为音频。
6 如何使用
- 上传一个或多个 PDF 文件
- 选择所需的指令模板
- 如果需要,可自定义说明
- 单击“生成音频”来创建您的音频内容
7 通过🤗 Hugging Face Spaces 访问
8 示例结果
9 笔记
10 致谢
该项目的灵感来自于https://github.com/knowsuchagency/pdf-to-podcast和https://github.com/knowsuchagency/promptic上提供的代码,并以其为基础。
@article{ghafarollahi2024sciagentsautomatingscientificdiscovery,
title={SciAgents: Automating scientific discovery through multi-agent intelligent graph reasoning},
author={Alireza Ghafarollahi and Markus J. Buehler},
year={2024},
eprint={2409.05556},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2409.05556},
}
@article{buehler2024graphreasoning,
title={Accelerating Scientific Discovery with Generative Knowledge Extraction, Graph-Based Representation, and Multimodal Intelligent Graph Reasoning},
author={Markus J. Buehler},
journal={Machine Learning: Science and Technology},
year={2024},
url={http://iopscience.iop.org/article/10.1088/2632-2153/ad7228},
}




![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)