这篇论文《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters》主要探讨了在推理时增加计算量如何提高大型语言模型(LLM)的表现。以下是根据论文目录的详细解读。
1. Introduction(介绍)
论文首先提出,尽管在训练期间已经进行了大量计算,但在推理时通过增加计算可以进一步提升LLM的表现。这种能力可以为更复杂的推理和自主改进任务打开大门,甚至可能在特定场景下用小模型代替大型模型。

通过系统性研究推理时增加计算的不同方法,作者发现这些方法的有效性与任务的难度密切相关,因此提出了“计算最优”(compute-optimal)的策略,即根据任务难度自适应地分配计算资源。
2. A Unified Perspective on Test-Time Computation: Proposer and Verifier(统一的推理时计算视角:提出者和验证者)
论文将推理时的计算方法归纳为两大类:
1)修改模型的输出分布(提出者),通过迭代调整模型的输出;
2)使用验证模型来评分每个输出,选择最佳答案(验证者)。作者重点探讨了如何通过修改模型的输入或输出来改善模型的生成分布,或者通过对生成结果的后处理来提高表现。
3. How to Scale Test-Time Computation Optimally(如何最优地扩展推理时的计算)
作者提出了推理时计算最优的策略,定义了一种计算预算分配方法,以便在给定任务上取得最佳表现。这个策略通过估计问题的难度(由模型的通过率等指标衡量),为不同难度的问题自适应地分配计算资源。
问题背景
给定一个任务和有限的推理时计算预算,论文提出一个核心问题:在不同的推理方法之间,如何最优地利用计算资源来提升模型的表现?另外,还比较了这种方法与使用更大预训练模型直接推理的效果。
计算最优扩展策略
作者提出了一种 “推理时计算最优扩展策略”(test-time compute-optimal scaling strategy)。其核心思想是,根据给定问题的难度,自适应地选择推理时最有效的计算方法。这意味着,推理时不同的方法(如修正答案或搜索验证答案)可能对不同的问题有不同的效果,计算资源的分配需要根据具体的任务进行调整。
定义计算最优扩展策略
作者将目标分布设定为模型在给定计算预算内生成的自然语言输出,具体表现为根据推理计算参数 ( \theta )、计算预算 ( N ) 和问题 ( q ),调整参数 ( \theta ) 来最大化生成的正确答案概率。该过程可以被描述为:
[ \theta^_{q,y^(q)(N)} = \arg\max_{\theta} (E_{y \sim Target(\theta,N,q)} [1_{y = y^*(q)}]) ]
其中,( y^(q) ) 表示问题 ( q ) 的正确答案,( \theta^ ) 是推理时的计算最优扩展策略。
问题难度的估计
为了执行计算最优扩展策略,论文提出了使用问题难度来引导计算资源分配的方法。问题难度被定义为模型解决该问题的难易程度。
具体来说,作者通过模型的 pass@1 率(即模型在2048次尝试中首次给出正确答案的概率)来将问题分为五个不同的难度等级。这些难度等级帮助选择最优的计算策略,并根据不同问题的难度自适应地分配推理时的计算资源。
基于模型预测的难度
在实际应用中,直接访问问题的正确答案通常是不现实的,因此需要基于模型输出来预测问题难度。通过使用验证器(verifier)的输出分数,作者提出了一种 基于模型预测的难度(model-predicted difficulty)方法。虽然这种方法增加了计算成本,但可以通过推理时的搜索来评估难度,从而使计算成本保持在可控范围内。
双重交叉验证
为了确保策略的有效性,作者使用了双重交叉验证(two-fold cross validation)来避免过拟合。在测试集上,计算出每个问题的难度等级,并根据不同难度选择最优的推理策略。
总结
第3章展示了如何通过估计问题的难度并基于难度调整推理时的计算策略,来最大化推理性能。作者认为,较简单的问题可能更适合通过修正答案的方式进行优化,而较复杂的问题可能需要更多的计算资源用于搜索验证答案。这一方法使得推理时计算可以更为高效地扩展,在多种推理任务中取得了显著的性能提升。
4. Experimental Setup(实验设置)
本节介绍了实验的基本设置,包括使用的数学推理数据集(MATH),以及实验中使用的PaLM 2-S*模型。MATH数据集包含难度不同的高中竞赛级别数学问题,适合研究LLM在推理时的推理能力。
5. Scaling Test-Time Compute via Verifiers(通过验证者扩展推理时计算)

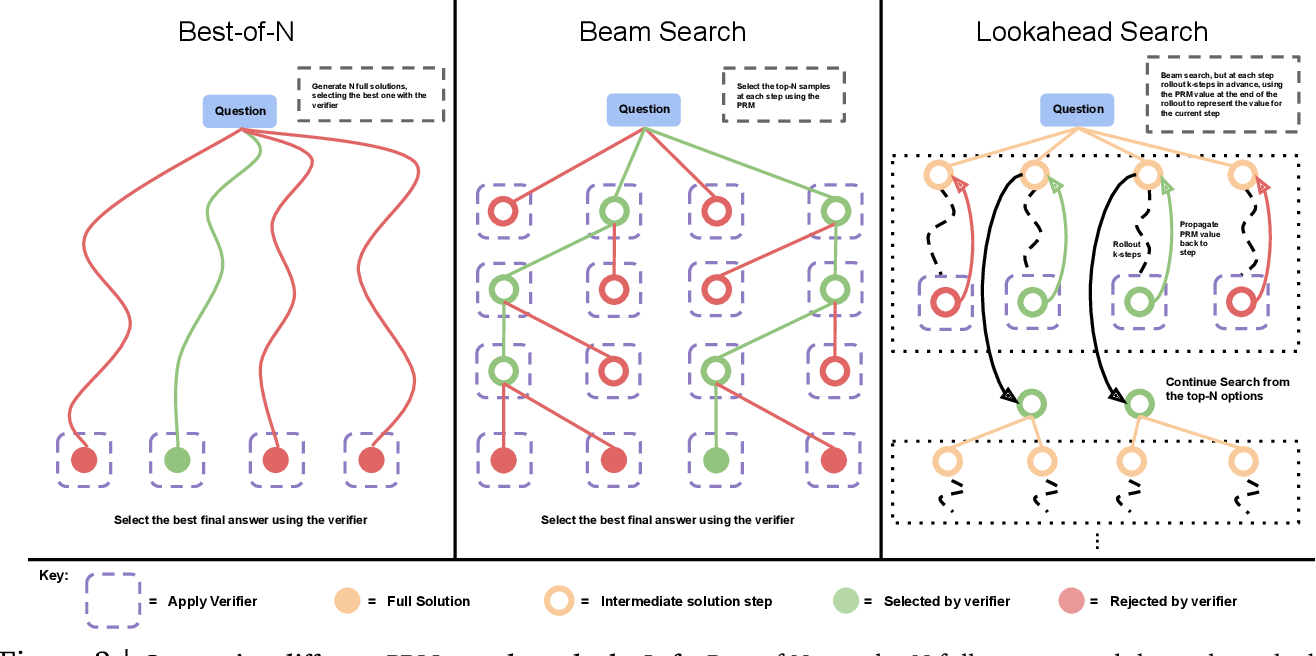
本节分析了如何通过优化验证者来扩展推理时的计算。作者对不同的验证方法进行了实验,如树搜索(beam search)和最佳-N采样法(best-of-N sampling)。结果显示,验证方法的有效性取决于问题的难度和计算预算。对更困难的问题,搜索方法效果更好,而对简单问题,最佳-N采样法表现更优。

6. Refining the Proposal Distribution(优化提出的分布)
本节探讨了如何通过让模型迭代修正自身答案来改进模型输出分布。实验结果表明,通过迭代修正模型的初始答案可以提升模型表现,特别是在推理任务中,逐步修正错误的答案比直接平行生成多个答案更有效。

7. Putting it Together: Exchanging Pretraining and Test-Time Compute(综合:预训练与推理时计算的替换)
在这一部分,作者研究了增加推理时的计算量是否能够替代更大规模的预训练。结果显示,在某些情况下,推理时的计算可以有效替代预训练,特别是对于容易和中等难度的问题,但对于更难的问题,增加预训练计算更为有效。
8. Discussion and Future Work(讨论与未来工作)
最后,作者总结了当前推理时计算扩展的局限性,并指出未来可以通过结合更多方法(如自我批评与修正)进一步提升表现。未来工作还应探索如何在训练和推理时相互交替使用计算资源,从而实现自我改进。
这篇论文的重点在于推理时增加计算可以有效地提升LLM的表现,尤其是在不同难度的问题上采用自适应的计算策略。

![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-360x180.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-360x180.png)
![Cultural Evolution of Cooperation among LLM Agents[大型语言模型代理间合作的文化演化]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-360x180.png)
![第3章:使用工具调用强制 JSON结构输出[以提取维基百科页面文章为例]-Claude工具调用教程](https://assh83.com/wp-content/uploads/2024/09/sea-7441916_1280-75x75.jpg)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)