
本分步教程深入探讨了如何充分利用 GPT-4 的全部功能,并通过微调增强其在专门任务中的性能。
OpenAI 最先进的模型生成式预训练 Transformer 4 (GPT-4)于 2023 年 3 月推出,是人工智能的一次飞跃,为人工智能能力树立了新的标杆。GPT-4 可通过ChatGPT Plus、OpenAI 的 API和 Microsoft Copilot 使用,其多模态能力脱颖而出,尤其是通过GPT-4V,它能够处理文本和图像,为各个领域的创新应用铺平了道路。
GPT-4 进步的核心在于其基于 Transformer 的框架,该框架基于来自互联网和授权来源的大量数据进行了广泛的预训练,并通过人工反馈和人工智能驱动的强化学习进行了微调。这种独特的方法旨在增强模型与人类道德标准和政策合规性的一致性。
虽然 GPT-4 比其前身GPT-3有所改进,但它继承了后者的一些局限性,凸显了大型语言模型和生成式人工智能的复杂挑战。其中一些挑战可以通过称为微调的过程来解决,这正是本教程的主题。本教程的目标是:
- 了解什么是微调以及何时使用它
- 微调的常见用例
- 使用 Python 逐步实现 OpenAI 的微调 API。
不过值得注意的是,GPT-4 微调目前仅处于实验阶段,符合条件的开发者可以通过微调 UI申请访问权限。话虽如此,本文涵盖的微调技术适用于所有 GPT 模型。
什么是微调?
微调是一个复杂的过程,它利用模型在不同数据集上进行初始训练时获得的大量基础知识,针对特定任务或领域优化预先训练的模型(如 GPT-4)。这涉及根据特定任务的数据调整模型的参数,增强其性能,并使其能够以更高的精度和效率处理特定应用。
微调影响的一个典型例子是增强模型对专业查询的响应。例如,当被问及为什么天空是蓝色时,预训练模型可能会提供基本的解释。通过微调,这种响应可以得到丰富,包括详细的科学背景,使其更适合教育平台等专业应用。
微调方法包括指令微调(使用展示所需响应的特定示例来训练模型)和参数高效微调(PEFT),后者仅更新模型参数的子集以节省计算资源并防止灾难性遗忘。
相比之下,检索增强生成 (RAG)代表了一种不同的方法。RAG 结合了基于检索的模型和生成模型的元素,通过在生成过程中整合从外部来源检索到的信息来提高生成内容的质量。
微调侧重于针对特定任务优化预先存在的模型,而 RAG 则整合了外部知识来丰富内容生成过程。
微调和 RAG 之间的选择取决于应用程序的具体要求,包括对最新信息的需求、可用的计算资源以及所需的任务专业化水平。微调提供了一种直接的方法,可以利用预先训练的模型的庞大知识库来完成特定任务,而 RAG 提供了一种动态方法来确保模型使用的信息的相关性和准确性。
何时使用微调?
对 OpenAI 的文本生成模型进行微调是一种有效的方法,可以根据特定需求对其进行定制,但需要大量时间和资源。在进行微调之前,建议尝试通过提示工程、提示链(将复杂任务划分为更简单、更连续的提示)和利用函数来最大化模型的性能。建议采用这种方法的原因如下:
- 模型最初可能会在某些任务上遇到困难,但制定正确的提示可以显著改善结果,在许多情况下不需要进行微调。
- 调整提示并采用提示链或函数调用等策略可以提供即时反馈,从而实现快速迭代。相比之下,微调涉及创建数据集和训练模型,这需要更多时间。
- 即使微调必不可少,但通过提示工程所做的前期工作也不会白费。将精心设计的提示纳入微调过程或将其与微调技术相结合通常可以产生最佳效果。
微调的常见用例
微调在以下场景中尤其有益:
- 自定义输出特性。当你需要模型遵循特定的风格、语气、格式或其他定性方面时,微调可以帮助相应地塑造其响应。
- 提高可靠性。对于模型始终如一地产生所需输出类型的应用来说,微调可以提高其可靠性。
- 处理复杂提示。如果模型无法遵循复杂的指令,微调可以帮助它更有效地理解和执行此类提示。
- 管理边缘情况。微调可以使模型以特定的、预定的方式处理大量边缘情况,从而增强其多功能性。
- 学习新技能或任务。当向模型引入难以在提示中概括的新技能或任务时,微调可以为其配备必要的能力。
使用 Python 对 OpenAI 的 GPT 模型进行微调的分步指南
由于 OpenAI 模型的专有性,如果您想微调任何 OpenAI 模型,则必须使用 OpenAI 的微调 API。此过程涉及将您的数据上传到 OpenAI 的服务器以训练模型。
目前仅支持以下模型通过API进行微调。
- GPT-3.5-Turbo-0125,
- GPT-3.5-Turbo-1106,
- GPT-3.5-Turbo-0613,
- 巴贝奇-002,
- 达芬奇-002
GPT-4 微调目前处于实验性访问阶段,符合条件的开发者可以通过微调 UI请求访问。无论使用哪种模型,微调的过程和本教程中的代码都不会改变。
微调 OpenAI GPT 模型的 6 个步骤
1.准备训练数据
这是最重要的一步。微调模型的质量直接取决于您为微调模型而创建的数据。对于 OpenAI API,数据必须以jsonl格式存储。
JSONL 格式是一种文本格式,其中每一行都是一个单独的 JSON 对象,因此适合逐行处理大型数据集。此格式对于处理可以轻松划分为单个记录而不会丢失结构的数据特别有用。
例子:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
在本教程中,我仅创建了五个示例的示例数据。数据包括有关机器学习中各种主题的问题和莎士比亚风格的答案。
我为本教程创建的示例数据:
{"messages": [{"role": "system", "content": "You are teaching assistant for Machine Learning. You should help to user to answer on his question."}, {"role": "user", "content": "What is machine learning?"}, {"role": "assistant", "content": "'Tis but the art of teaching machines to think, to learn from data most fine, and decisions to link."}]}
{"messages": [{"role": "system", "content": "You are teaching assistant for Machine Learning. You should help to user to answer on his question."}, {"role": "user", "content": "How doth neural networks work?"}, {"role": "assistant", "content": "They're like the brains of yon digital beast, with layers many, and nodes that cease."}]}2. 安装 openai 库并设置 API 令牌
使用 OpenAI API 创建微调作业的第一步是上传文件。要使用此 API,您必须openai安装 Python 库。
!pip install openai现在登录您的 platform.openai.com 帐户并生成 API 令牌:
然后您可以使用该库将令牌设置为环境变量os。
import os
# Set the OPENAI_API_KEY environment variable
os.environ['OPENAI_API_KEY'] = '...'3.上传训练文件
您的训练文件必须是jsonl格式。上传文件后,处理可能需要一段时间。文件上传的最大大小为 1 GB。要在 OpenAI 服务器上上传文件:
from openai import OpenAI
client = OpenAI()
client.files.create(
file=open("train.jsonl", "rb"),
purpose="fine-tune"
)输出:
FileObject(id='file-rIua39sJX1O64gzxTYfpvJx7', bytes=11165, created_at=1709499930, filename='train.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)4. 创建微调模型
确保文件已成功上传后,下一步是创建微调作业。training_file是将训练文件上传到 OpenAI API 时返回的文件 ID。要启动微调作业:
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-rIua39sJX1O64gzxTYfpvJx7",
model="gpt-3.5-turbo" #change to gpt-4-0613 if you have access
)要配置额外的微调设置,例如validation_file或超参数,请查看有关微调的 API 文档。
微调作业的完成时间各不相同,从几分钟到几小时不等,具体取决于模型和数据集的大小。例如,我们的 train.jsonl 数据集中只有 50 个示例,使用 gpt-3.5-turbo 模型,该作业仅用 7 分钟就完成了。
一旦工作完成,还会发送一封电子邮件确认。
除了设置微调作业之外,您还可以选择查看当前作业列表、检查特定作业的状态或取消作业。
from openai import OpenAI
client = OpenAI()
# List 10 fine-tuning jobs
client.fine_tuning.jobs.list(limit=10)
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve("...")
# Cancel a job
client.fine_tuning.jobs.cancel("...")
# List up to 10 events from a fine-tuning job
client.fine_tuning.jobs.list_events(fine_tuning_job_id="...", limit=10)
# Delete a fine-tuned model (must be an owner of the org the model was created in)
client.models.delete("ft:gpt-3.5-turbo:xxx:xxx")5.分析微调模型
OpenAI 提供关键的训练指标,例如训练损失、训练的 token 准确率、测试损失和测试 token 准确率。这些指标有助于确保训练按预期进行,损失减少,token 准确率提高。您可以在活动微调作业期间在事件对象中查看这些有用的指标。
{
"object": "fine_tuning.job.event",
"id": "ftjob-Na7BnF5y91wwGJ4EgxtzVyDD",
"created_at": 1693582679,
"level": "info",
"message": "Step 100/100: training loss=0.00",
"data": {
"step": 100,
"train_loss": 1.805623287509661e-5,
"train_mean_token_accuracy": 1.0
},
"type": "metrics"
}您也可以在 UI 上看到此信息。
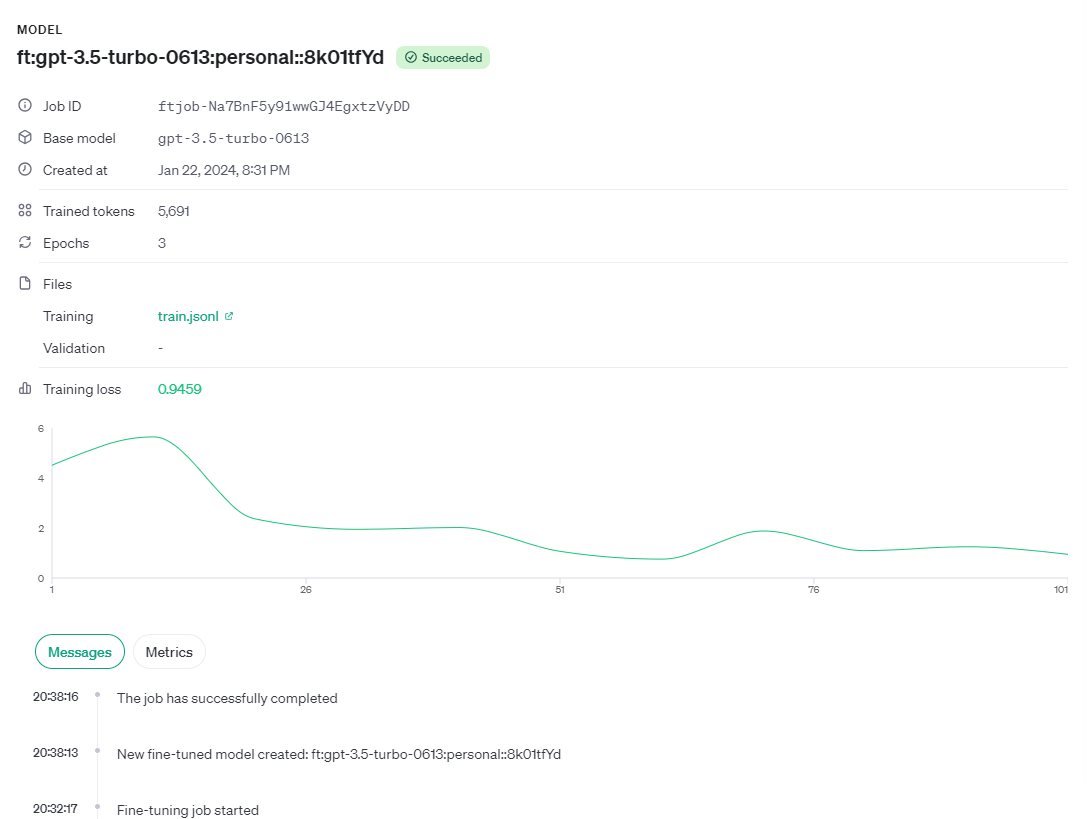
6. 使用微调模型
成功完成作业后,作业详细信息将包含fine_tuned_model显示模型名称的字段。您可以对此模型进行 API 调用,并从我们刚刚调整的模型获取响应。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0613:personal::8k01tfYd",
messages=[
{"role": "system", "content": "You are a teaching assistant for Machine Learning. You should help to user to answer on his question."},
{"role": "user", "content": "What is a loss function?"}
]
)
print(completion.choices[0].message)输出:
ChatCompletionMessage(content="To measure how far we falter, it guides our way, our hope's defaulter.", role='assistant', function_call=None, tool_calls=None)结论
本教程指导您完成 OpenAI 的 GPT 模型微调过程,这是利用 LLM 的强大功能开发专业领域应用的高级步骤。微调使我们能够优化语言模型的响应,使其更擅长以更高的精度和效率处理特定任务、风格或领域。
本教程使用 OpenAI Python API 对模型进行微调。如果您更愿意学习如何通过 UI 执行相同操作而无需编写一行代码,则可以查看Datacamp 上的“如何微调 GPT 3.5”教程。
由于 GPT 不是开源模型,因此微调过程相当简单,只需进行 API 调用即可。这与微调 llama-2、Mistral、Stable transmission 等开源模型的情况非常不同。如果您有兴趣了解如何微调各种开源模型,


![第3章:使用工具调用强制 JSON结构输出[以提取维基百科页面文章为例]-Claude工具调用教程](https://assh83.com/wp-content/uploads/2024/09/gower-5190799_1280-360x180.jpg)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)