
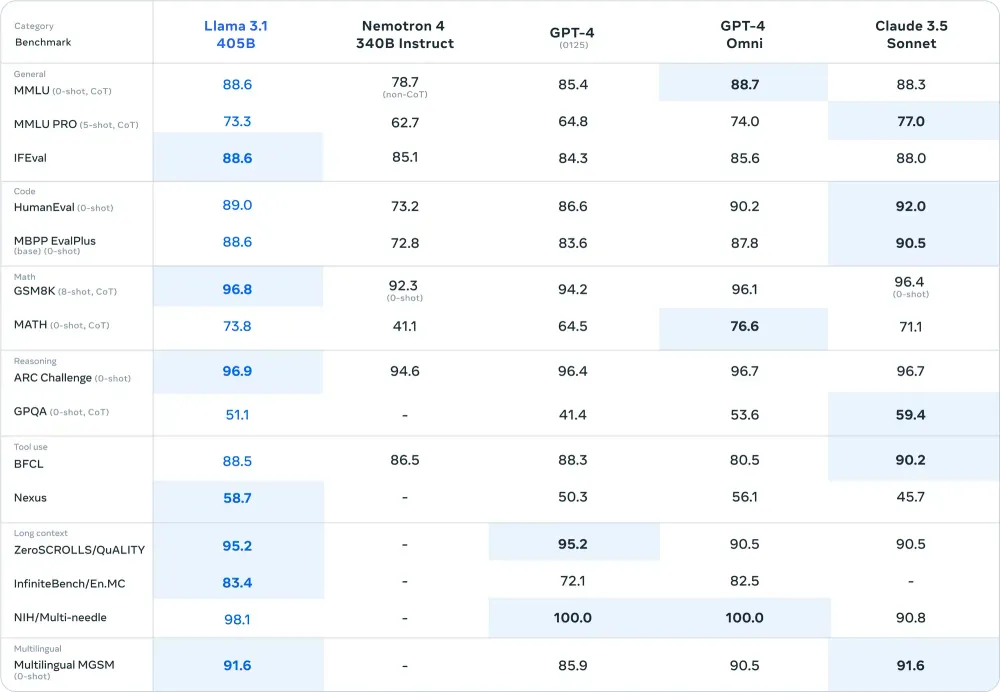
Meta 最近发布的 Llama 3.1 405B 模型在 AI 社区引起了轰动。这一开创性的开源模型不仅匹敌甚至超越了领先的闭源模型的性能。Llama 3.1 在推理任务(ARC Challenge 上为 96.9 分,GSM8K 上为 96.8 分)和代码生成(HumanEval 基准测试上为 89.0 分)上取得了令人印象深刻的成绩,堪称游戏规则的改变者。
按照本指南了解如何使用 Ollama(一个功能强大且用户友好的 LLM 运行平台)在 RunPod 上部署模型。此外,我们将向您展示如何仅使用一个 Docker 命令在类似 ChatGPT 的 WebUI 聊天界面中测试它。
为什么使用 Llama 3.1 405B?
Llama 3.1 具有突破性,主要有以下三个原因:
- 卓越的性能:凭借 4050 亿个参数,它在数学和多语言任务等关键基准测试中的表现优于大多数模型(包括 GPT-4o)。
- 可定制:提供具有顶级功能的开源替代方案,为独特用例提供增强的可访问性和定制性。
- 经济高效:在 RunPod 等服务上运行自己的模型比许多大型封闭模型 API 便宜得多。
有关 Llama 3.1 的更多详细信息,请查看Meta 的博客。
在 RunPod 上部署 Llama 3.1 405B 的分步指南
先决条件
1) 创建您的 RunPod 帐户并添加至少 10 美元来租用您的 GPU。
2)安装docker。
1. 创建并配置你的 GPU Pod
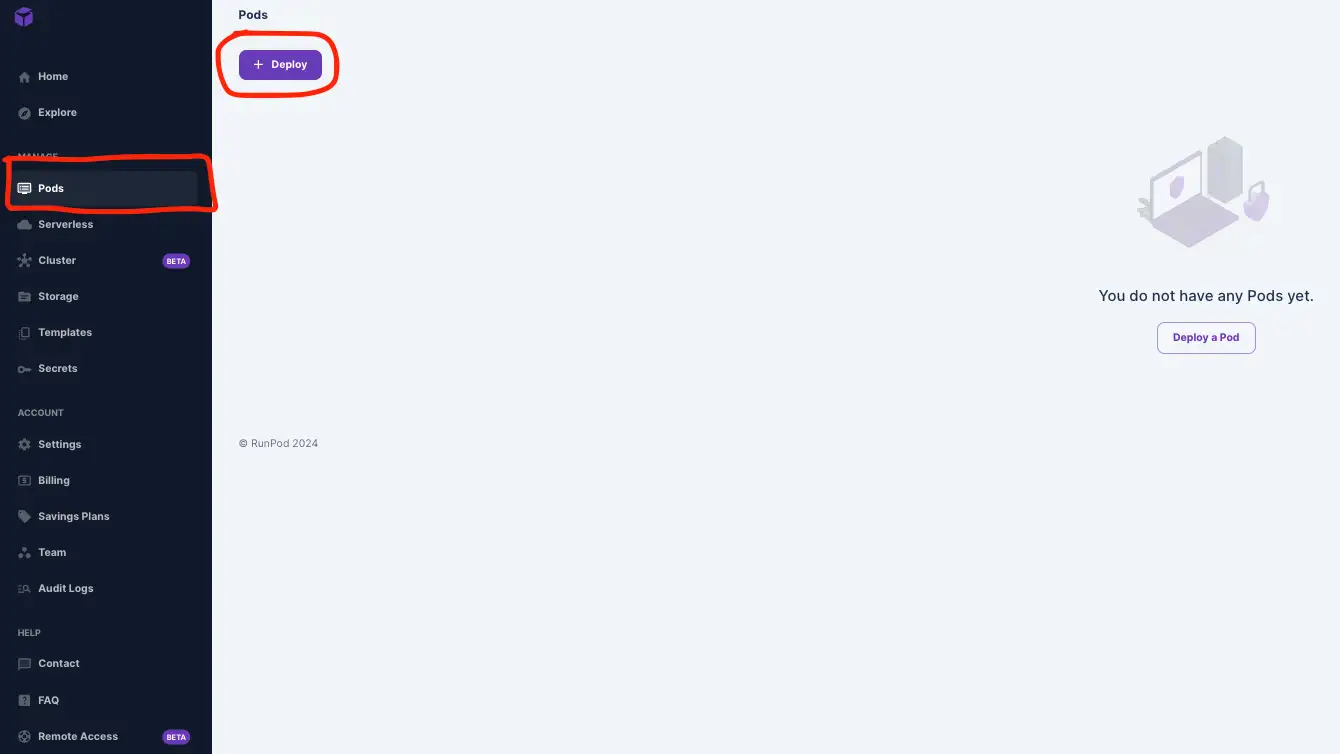
1)前往Pods并单击Deploy。
2) 选择 H100 PCIe 并选择 3 个 GPU 以提供 240GB 的 VRAM(每个 80GB)。Llama 3.1 405B 型号是 4 位量化的,因此我们至少需要 240GB 的 VRAM。有关更多详细信息,请查看我们关于选择合适的 VRAM的博客。
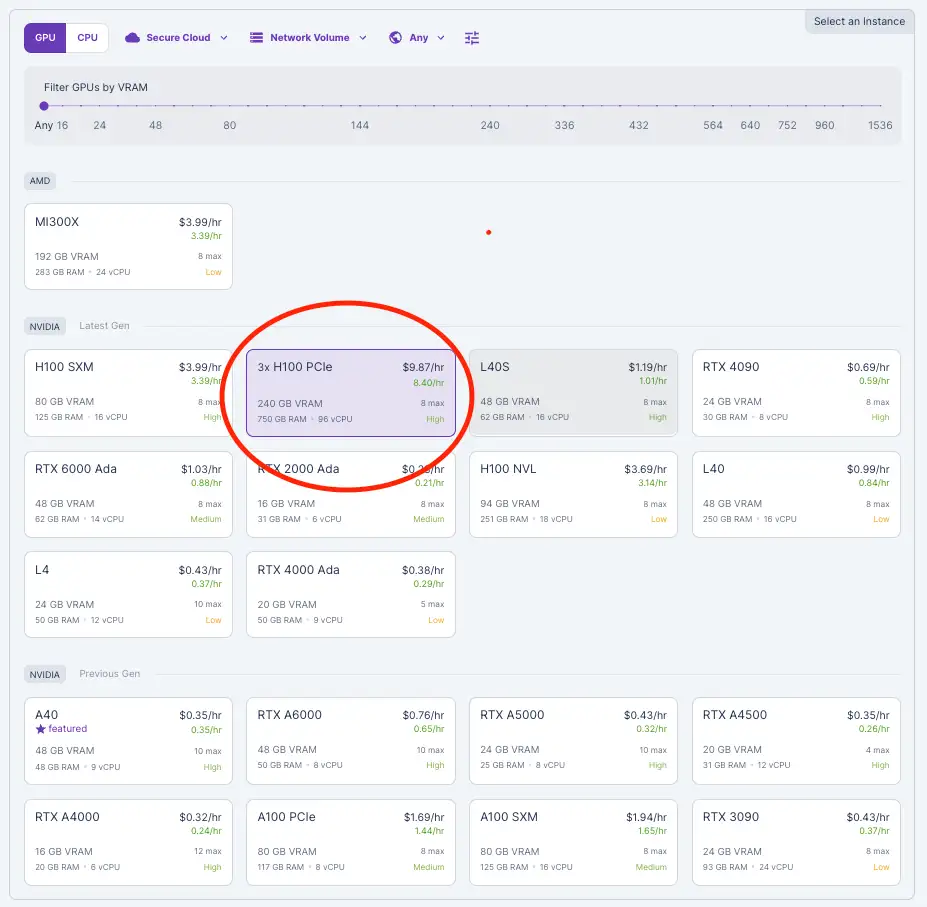
3)将 GPU 数量滑动至 3。
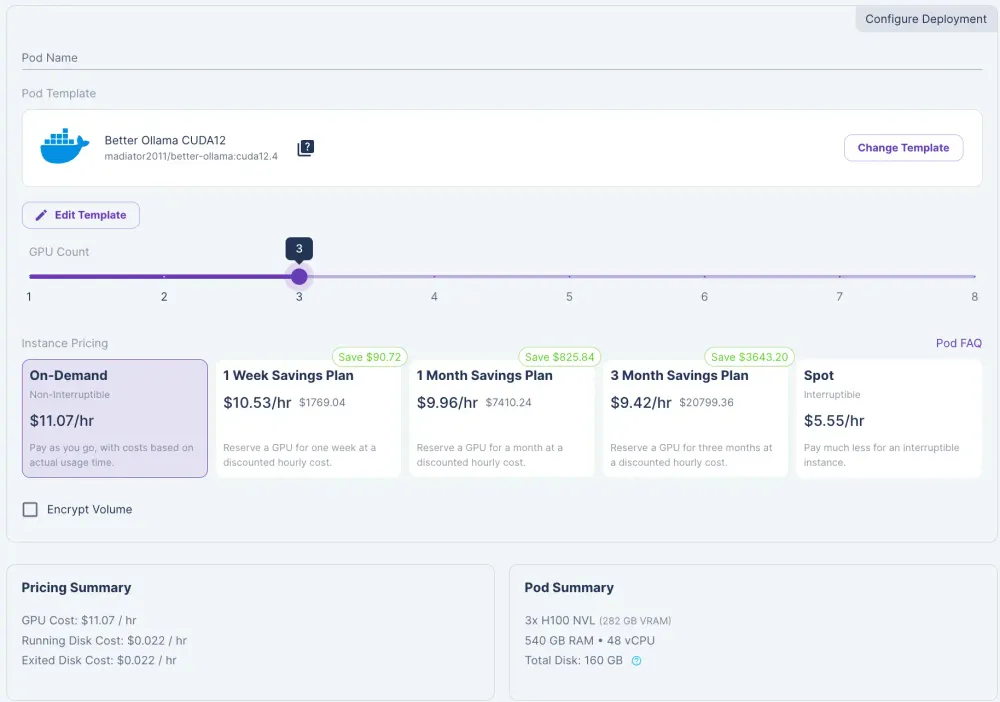
4)点击将模板更改为“Better Ollama CUDA 12”。
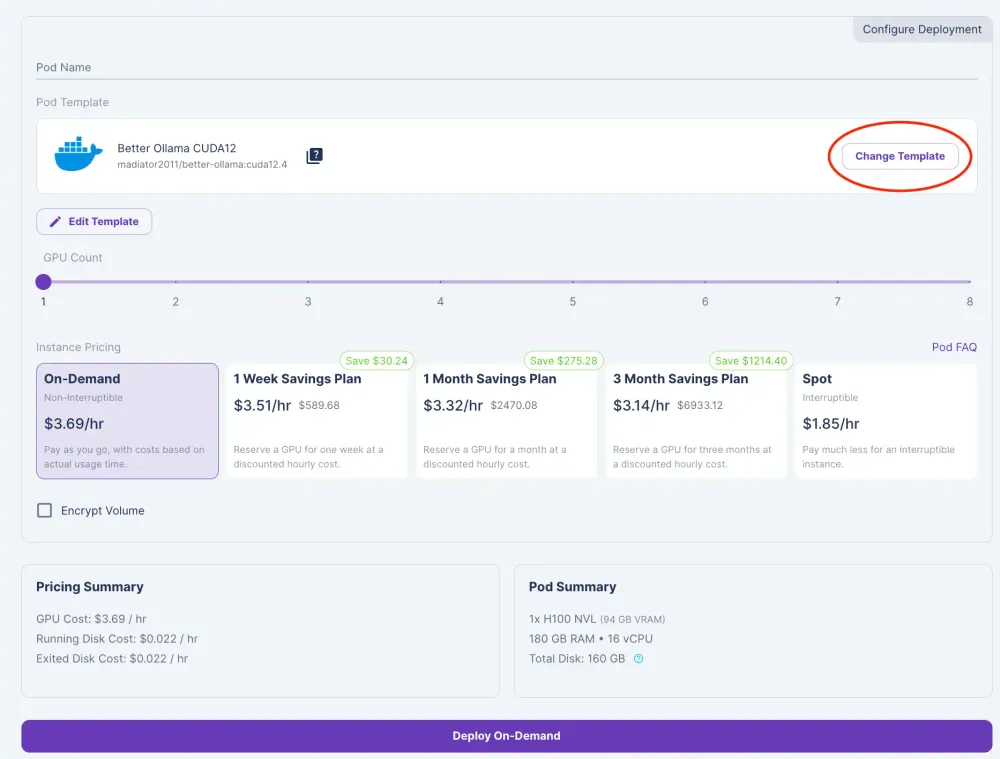
5)单击编辑模板并编辑容器磁盘并将其设置为 250 GB,以用于存储模型。
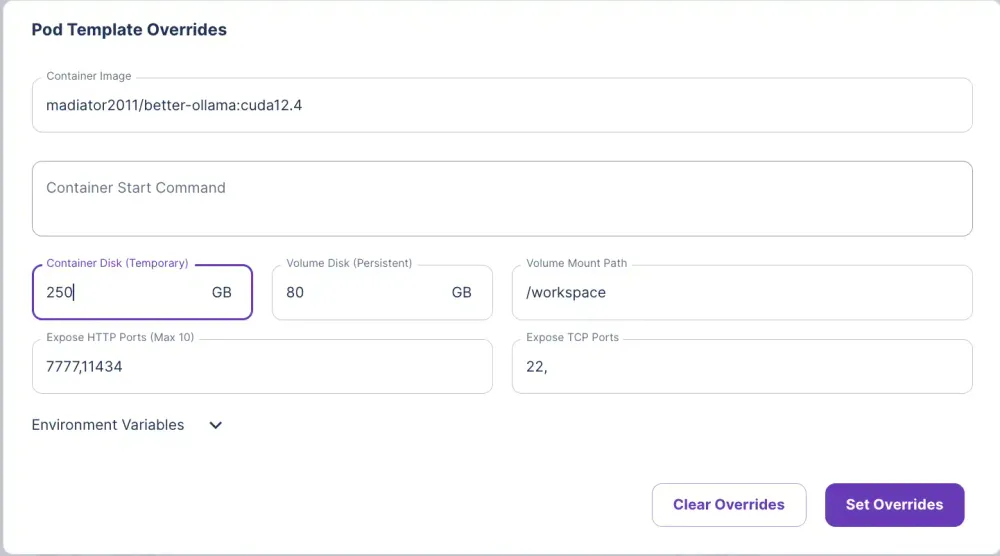
6) 单击“设置覆盖并部署”。
7)找到您的 Pod 并单击“连接”。
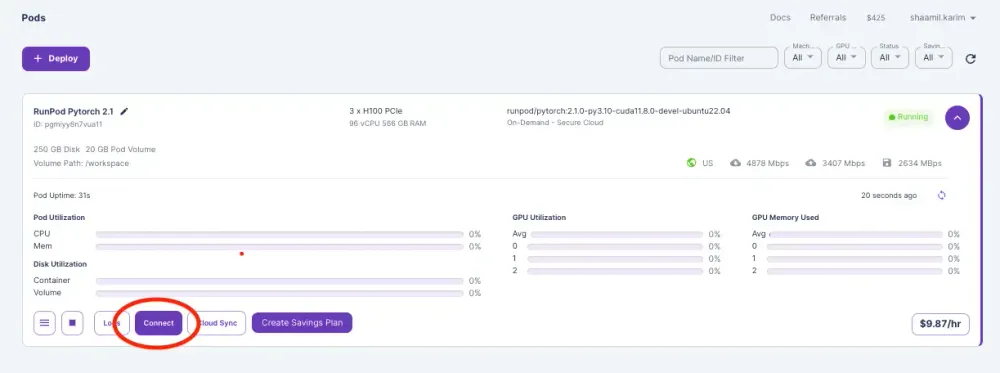
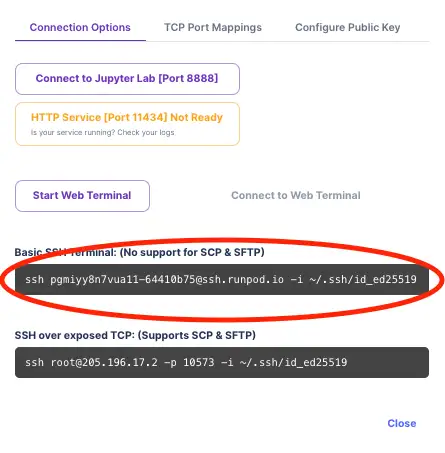
8)复制您的 SSH 命令。
2. 下载 Ollama 和 Llama 3.1 405B
1)打开您的终端并运行上面复制的 SSH 命令。
2)通过 SSH 连接后,在终端中运行此命令:
(curl -fsSL <https://ollama.com/install.sh> | sh && ollama serve > ollama.log 2>&1) &
此命令获取 Ollama 安装脚本并执行它,在您的 Pod 上设置 Ollama。该 ollama serve 代码启动 Ollama 服务器并对其进行初始化以提供 AI 模型。
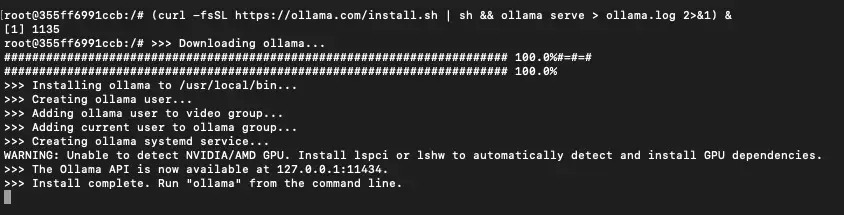
3)下载Llama 3.1 405B模型(抬头,可能需要一段时间):
ollama run llama3.1:405b
开始从终端与您的模型聊天。让我们使用 WebUI 使其更具交互性。
3. 使用 Open WebUI 的聊天界面运行 Llama 3.1 405B
1)打开一个新的终端窗口。
2)运行以下命令,将 {POD-ID} 替换为您的 pod ID:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://{POD-ID}-11434.proxy.runpod.net/ -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
example:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=:<https://pgmiyy8n7vua11-11434.proxy.runpod.net> -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
3)完成以上操作后,转到http://localhost:3000/并注册Open WebUI。
4)点击选择模型,选择我们下载的模型。
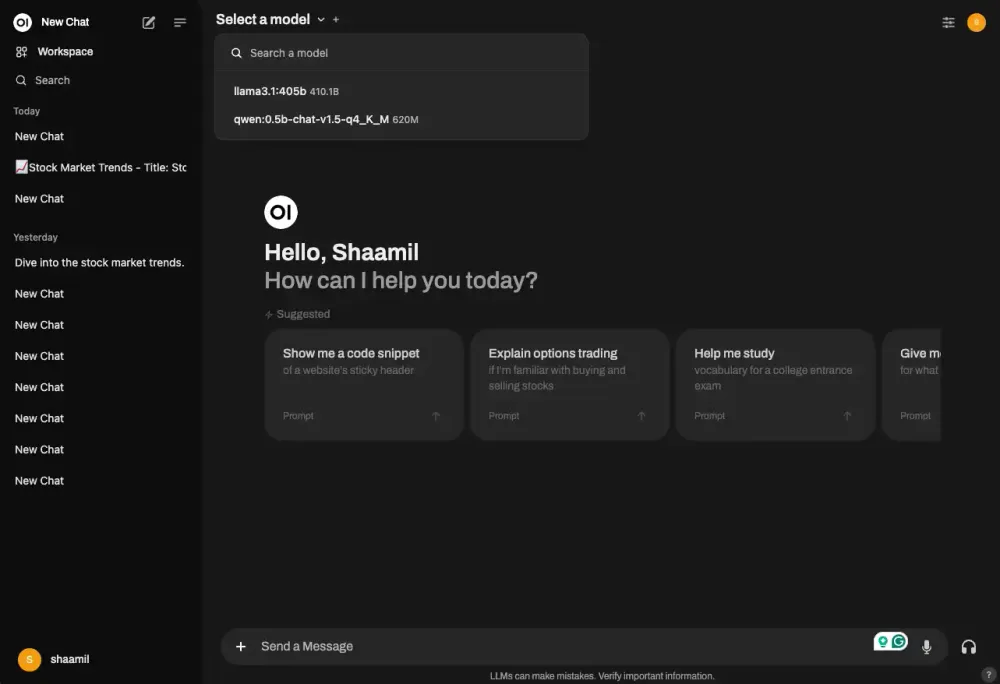
完成!现在,您有一个聊天界面,可以使用 RunPod 上的 Ollama 与您的 Llama 405b 模型聊天。
故障排除
- 如果 docker 命令未运行,请确保桌面应用已启动并正在运行。您还可以从容器列表中跟踪 docker 容器和日志。
- 如果您在使用 Open WebUI 界面时遇到问题,请确保您可以像步骤 2.3 中一样通过终端与模型聊天以隔离问题。查看 Open WebUI 的文档以获取更多帮助或在此博客上发表评论。
如果您仍然遇到问题,请在下面在此博客上发表评论以寻求帮助,或者关注Runpod 的文档或Open WebUI 的文档。
结论
回顾一下,您首先在 RunPod 上配置您的 Pod,通过终端通过 SSH 进入您的服务器,下载 Ollama 并通过 SSH 终端运行 Llama 3.1 405b 模型,然后运行您的 docker 命令在单独的终端选项卡上启动聊天界面。
现在,您已经体验到了在 RunPod 上运行带有 Ollama 的 Llama 3.1 405B 模型的速度和功能。通过利用 RunPod 的可扩展 GPU 资源和 Ollama 的高效部署工具,您可以充分利用这款尖端模型的潜力来完成您的项目。无论您是进行微调、进行研究还是开发应用程序,此设置都提供了突破 AI 极限所需的性能和可访问性。查看我们关于微调与 RAG的博客,以决定自定义设置的正确选项。


![Llama Stack入门安装指南[结合Ollama]-AI大模型](https://assh83.com/wp-content/uploads/2024/09/3541422-0-82720500-1727389966-shutterstock_1175616652-100945248-orig-360x180.webp)


![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)