
Meta 发布了 Llama 3.1 405B,这是一个大型开源语言模型,旨在与 GPT-4o 和 Claude 3.5 Sonnet 等封闭模型竞争。
2024 年 7 月 23 日星期二,Meta 宣布推出 Llama 3.1,这是其Llama 系列大型语言模型 (LLM)的最新版本。
虽然只是对 Llama 3 模型进行小幅更新,但它特别引入了Llama 3.1 405B——一个 4050 亿参数的模型,这是迄今为止世界上最大的开源 LLM,超过了 NVIDIA 的Nemotron-4-340B-Instruct。
实验评估表明,它在各种任务上均可与GPT-4、GPT-4o和Claude 3.5 Sonnet等领先模型相媲美。
然而,由于Mistral和Falcon等竞争对手选择较小的模型,人们开始质疑大型开放权重 LLM 在当前环境下的相关性。
请继续阅读以了解我们的观点以及有关 Llama 生态系统更新的信息。
什么是 Llama 3.1 405B?
Llama 3.1 是 Llama 3( 2024 年 4 月发布)的点更新,Llama 3.1 405B 是该模型的旗舰版本,顾名思义,它拥有 4050 亿个参数。

来源:Meta AI
LMSys Chatbot Arena 排行榜上的 Llama3.1 405B
拥有 4050 亿个参数使其在LMSys Chatbot Arena 排行榜上争夺高位,该排行榜是通过盲目用户投票获得的性能衡量标准。
最近几个月,OpenAI GPT-4、Anthropic Claude 3和 Google Gemini 等版本交替占据榜首。目前,GPT-4o 占据榜首,但规模较小的 Claude 3.5 Sonnet 占据第二位,而即将推出的 Claude 3.5 Opus 很可能会占据第一的位置,前提是它能在 OpenAI 更新 GPT-4o 之前发布。
这意味着高端市场的竞争非常激烈,看看 Llama 3.1 405B 与这些竞争对手相比的表现会很有趣。在我们等待 Llama 3.1 405B 出现在排行榜上的同时,本文后面将提供一些基准测试。
多语言能力
从 Llama 3 到 Llama 3.1 的主要更新是更好的非英语支持。Llama 3 的训练数据 95% 是英语,因此在其他语言中表现不佳。3.1 更新提供了对德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语的支持。
更长的背景
Llama 3 模型的上下文窗口(一次可以推理的文本量)为 8k 个标记(约 6k 个单词)。Llama 3.1 将其提升至更现代的 128k,使其与其他最先进的 LLM 相媲美。
这解决了 Llama 家族的一个重要弱点。对于企业用例(如总结长文档、从大型代码库生成涉及上下文的代码或扩展支持聊天机器人对话),可以存储数百页文本的长上下文窗口至关重要。
开放模型许可协议
Llama 3.1 模型可根据 Meta 的定制开放模型许可协议获得。此许可允许研究人员、开发人员和企业自由地将该模型用于研究和商业应用。
在一次重大更新中,Meta 还扩大了许可证,允许开发人员利用 Llama 模型(包括 405B 模型)的输出来增强其他模型。
本质上,这意味着任何人都可以利用该模型的功能来推进他们的工作,创建新的应用程序并探索人工智能的可能性,只要他们遵守协议中概述的条款。
Llama 3.1 405B 如何工作?
本节介绍 Llama 3.1 405B 的工作技术细节,包括其架构、训练过程、数据准备、计算要求和优化技术。
经过调整的 Transformer 架构
Llama 3.1 405B 基于标准解码器专用Transformer 架构构建,这是许多成功的大型语言模型所采用的设计。
在核心结构保持一致的同时,Meta 进行了细微调整,以增强模型在训练过程中的稳定性和性能。值得注意的是,Meta 有意排除了混合专家 (MoE) 架构,优先考虑训练过程中的稳定性和可扩展性。
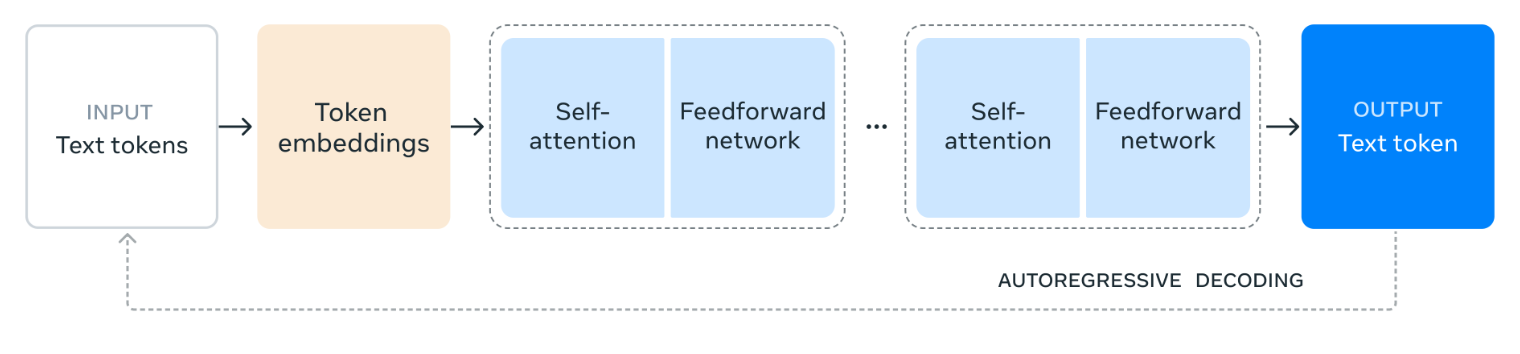
来源:Meta AI
该图说明了 Llama 3.1 405B 如何处理语言。它首先将输入文本划分为称为标记的较小单元,然后将其转换为称为标记嵌入的数字表示。
然后通过多层自注意力来处理这些嵌入,其中模型分析不同标记之间的关系以了解它们在输入中的重要性和上下文。
从自注意力层收集的信息随后会通过前馈网络,该网络会进一步处理和组合信息以得出含义。这种自注意力和前馈处理过程会重复多次,以加深模型的理解。
最后,模型利用这些信息逐个生成响应标记,在先前输出的基础上创建连贯且相关的文本。这一迭代过程称为自回归解码,它使模型能够对输入提示生成流畅且符合语境的响应。
多阶段训练过程
开发 Llama 3.1 405B 涉及一个多阶段的训练过程。最初,该模型在包含数万亿个标记的庞大而多样的数据集上进行了预训练。通过接触大量文本,该模型可以从遇到的模式和结构中学习语法、事实和推理能力。
在预训练之后,模型会经过多轮监督微调 (SFT) 和直接偏好优化 (DPO)。SFT 涉及对特定任务和数据集进行训练并提供人工反馈,从而引导模型产生所需的输出。
而 DPO 则侧重于根据从人类评估者那里收集到的偏好来改进模型的响应。这一迭代过程逐步增强了模型遵循指令的能力,提高了响应质量,并确保了安全。
数据质量和数量
Meta 声称非常重视训练数据的质量和数量。对于 Llama 3.1 405B,这涉及严格的数据准备过程,包括广泛的过滤和清理,以提高数据集的整体质量。
有趣的是,405B 模型本身用于生成合成数据,然后将其纳入训练过程以进一步完善模型的功能。
扩大计算规模
训练像 Llama 3.1 405B 这样庞大而复杂的模型需要大量的计算能力。具体来说,Meta 使用了 16,000 多个 NVIDIA 最强大的 GPU(H100)来高效地训练这个模型。
他们还对整个训练基础设施进行了重大改进,以确保其可以处理庞大的项目规模,从而使模型能够有效地学习和改进。
推理量化
为了使 Llama 3.1 405B 在实际应用中更具可用性,Meta 应用了一种称为量化的技术,该技术涉及将模型的权重从 16 位精度 (BF16) 转换为 8 位精度 (FP8)。这就像从高分辨率图像切换到略低的分辨率:它保留了必要的细节,同时减小了文件大小。
同样,量化简化了模型的内部计算,使其在单个服务器上的运行速度更快、效率更高。这种优化使其他人能够更轻松、更经济高效地利用该模型的功能。
Llama 3.1 405B 用例
Llama 3.1 405B 由于其开源特性和强大的功能而提供了各种潜在的应用。
合成数据生成
该模型能够生成与人类语言极为相似的文本,可用于创建大量合成数据。
这些合成数据对于训练其他语言模型、增强数据增强技术(使现有数据更加多样化)以及为各种应用开发真实的模拟非常有价值。
模型蒸馏
405B 模型中嵌入的知识可以通过“提炼”的过程转移到更小、更高效的模型中。
可以将模型蒸馏视为向学生(较小的 AI 模型)传授专家(较大的 Llama 3.1 405B 模型)的知识。此过程允许较小的模型学习和执行任务,而不需要与较大的模型相同程度的复杂性或计算资源。
这使得在智能手机或笔记本电脑等设备上运行高级 AI 功能成为可能,而与用于训练原始模型的强大服务器相比,这些设备的功能有限。
模型蒸馏的一个例子是 OpenAI 的GPT-4o mini,它是 GPT-4o 的蒸馏版本。
研究与实验
Llama 3.1 405B 是一种有价值的研究工具,使科学家和开发人员能够探索自然语言处理和人工智能的新领域。
它的开放性鼓励实验和协作,从而加快发现的步伐。
行业特定解决方案
通过使模型适应特定行业(例如医疗保健、金融或教育)的特定数据,可以创建定制的 AI 解决方案来应对这些领域的独特挑战和要求。
Llama 3.1 405B 安全重点
Meta 声称非常重视确保其 Llama 3.1 型号的安全性。

来源:Meta AI
在发布 Llama 3.1 405B 之前,他们进行了广泛的“红队”演习。在这些演习中,内部和外部专家扮演对手,试图找到让模型以有害或不适当的方式行事的方法。这有助于识别模型行为中的潜在风险或漏洞。
除了部署前测试外,Llama 3.1 405B 还经过了安全微调。此过程涉及诸如人类反馈强化学习 (RLHF)之类的技术,其中模型学习使其响应与人类价值观和偏好保持一致。这有助于减轻有害或有偏见的输出,使模型在实际使用中更安全、更可靠。
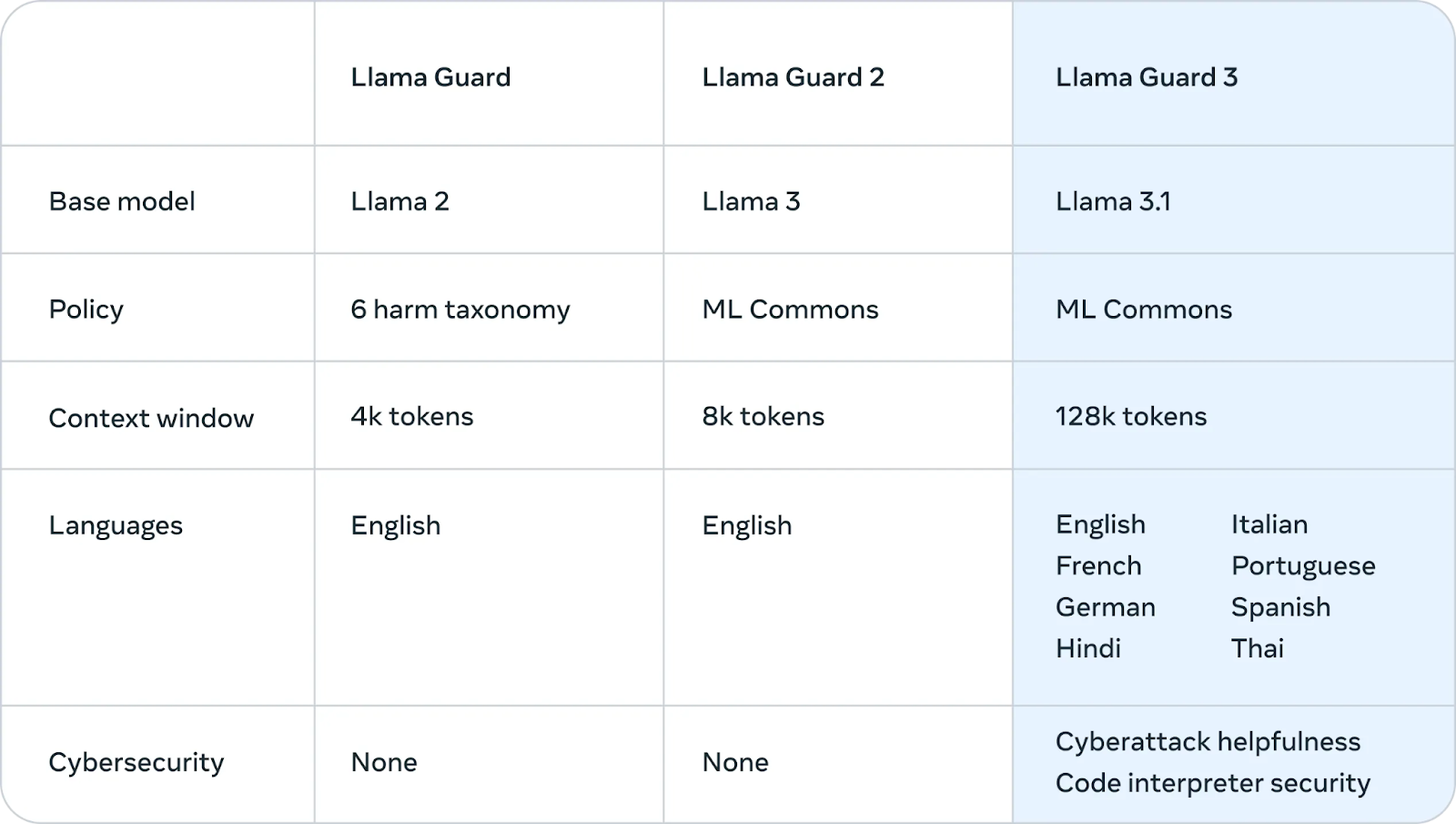
Meta 还推出了Llama Guard 3,这是一种新的多语言安全模型,旨在过滤和标记由 Llama 3.1 405B 生成的有害或不当内容。这一额外的保护层有助于确保模型的输出符合道德和安全准则。
来源:Meta AI
另一个安全功能是Prompt Guard ,旨在防止提示注入攻击。这些攻击涉及将恶意指令插入用户提示中以操纵模型的行为。Prompt Guard 会过滤掉此类指令,保护模型免受潜在的滥用。

来源:Meta AI
此外,Meta 还加入了Code Shield ,该功能专注于 Llama 3.1 405B 生成的代码的安全性。Code Shield 在推理过程中实时过滤不安全的代码建议,并为七种编程语言提供安全的命令执行保护,平均延迟时间为 200 毫秒。这有助于降低生成可能被利用或构成安全威胁的代码的风险。

来源:Meta AI
Llama 3.1 405B 基准测试
Meta 已在 150 多个不同的基准数据集上对 Llama 3.1 405B 进行了严格的评估。这些基准涵盖了广泛的语言任务和技能,从常识和推理到编码、数学和多语言能力。

来源:Meta AI
Llama 3.1 405B 在许多基准测试中的表现都堪比 GPT-4、GPT-4o 和 Claude 3.5 Sonnet 等领先的闭源模型。值得注意的是,它在推理任务中表现出色,在 ARC Challenge 上获得了 96.9 分,在 GSM8K 上获得了 96.8 分。它在代码生成方面也表现出色,在 HumanEval 基准测试中获得了 89.0 分。
除了自动基准测试之外,Meta AI 还进行了大量的人工评估,以评估 Llama 3.1 405B 在现实场景中的表现。
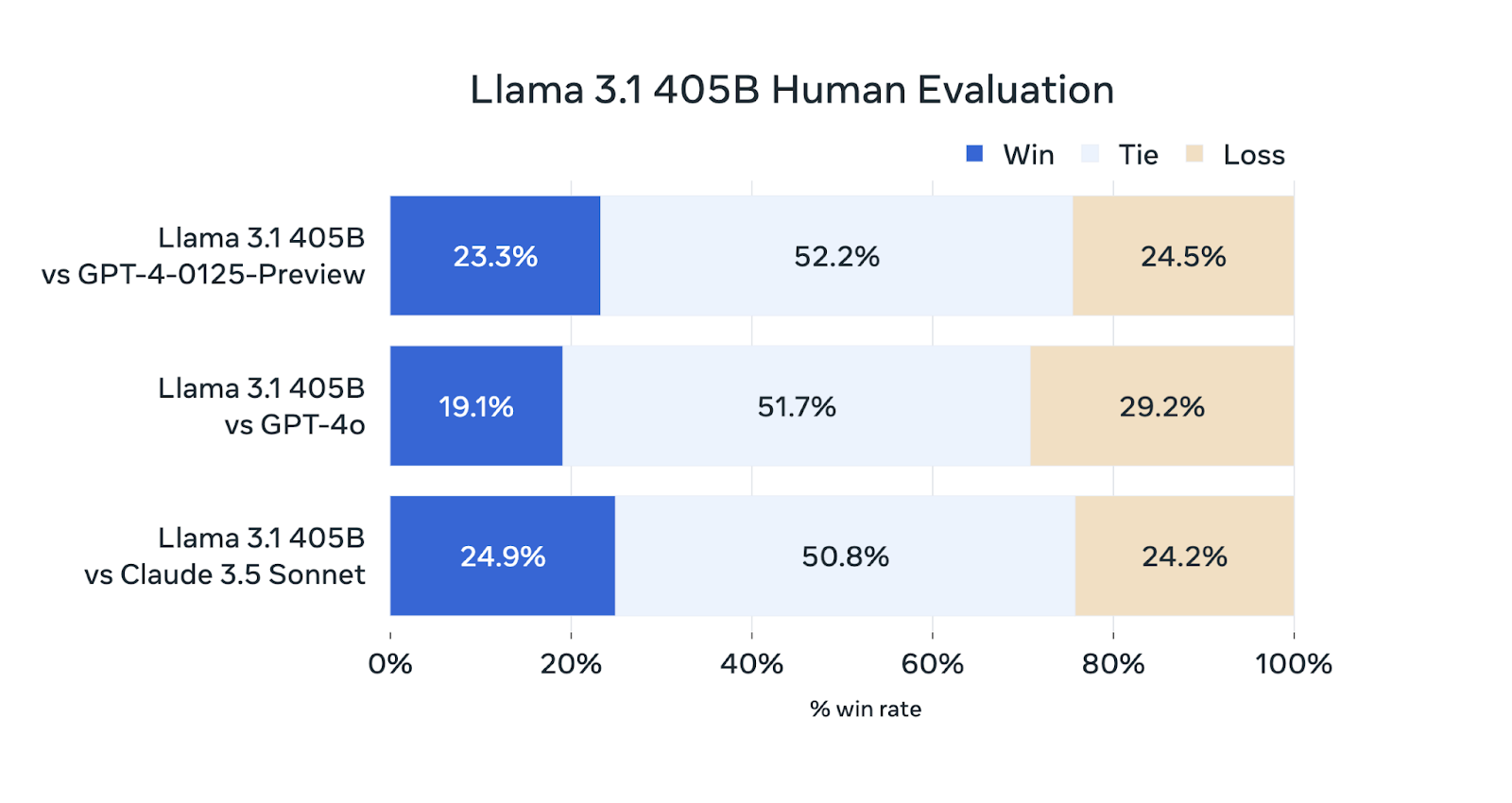
来源:Meta AI
虽然 Llama 3.1 405B 在这些评估中具有竞争力,但它的表现并不总是优于其他模型。它的表现与 GPT-4-0125-Preview(OpenAI 于 2024 年初发布的预览版 GPT-4 模型)和 Claude 3.5 Sonnet 相当,获胜和失败的评估百分比大致相同。它略微落后于 GPT-4o,仅赢得了 19.1% 的比较。
我可以在哪里访问 Llama 3.1 405B?
您可以通过两个主要渠道访问 Llama 3.1 405B:
- 直接从 Meta 下载:模型权重可以直接从 Meta 的官方 Llama 网站下载:llama.meta.com
- Hugging Face:Llama 3.1 405B 也可在Hugging Face平台上使用,该平台是共享和访问机器学习模型的流行中心。
通过使模型随时可用,Meta 旨在使研究人员、开发人员和组织能够将其功能用于各种应用程序,并为 AI 技术的持续进步做出贡献 – 请在马克·扎克伯格的信中阅读有关 Meta 关于开源 AI 的更多原则。
Llama 3.1 系列车型
虽然 Llama 3.1 405B 因其尺寸而引人注目,但 Llama 3.1 系列还提供其他型号,旨在满足不同的使用情况和资源限制。这些型号与 405B 版本共享先进功能,但针对特定需求进行了量身定制。
Llama 3.1 70B:多功能
Llama 3.1 70B 型号在性能和效率之间取得了平衡,使其成为广泛应用的有力候选者。
它在长文本摘要、创建多语言对话代理和提供编码帮助等任务方面表现出色。
虽然比 405B 型号小,但它在各种基准测试中仍能与其他类似尺寸的开放式和封闭式型号竞争。其尺寸减小也使其更易于在标准硬件上部署和管理。

来源:Meta AI
Llama 3.1 8B:轻便高效
Llama 3.1 8B 型号优先考虑速度和低资源消耗。它非常适合这些因素至关重要的场景,例如部署在边缘设备、移动平台或计算资源有限的环境中。
即使尺寸较小,它在各种任务中的表现也比类似尺寸的模型更具竞争力(见上表)。
所有 Llama 3.1 型号均具有共享增强功能
所有 Llama 3.1 型号都具有几项关键改进:
- 扩展上下文窗口(128K 个标记):上下文窗口(表示模型可以一次处理的文本量)已显著增加到 128,000 个标记。这使模型能够处理更长的输入,并在扩展对话或文档中保持上下文。
- 多语言支持:所有型号现在都支持八种语言:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。这种更广泛的语言支持将其适用范围扩大到全球受众。
- 改进的工具使用和推理:模型的工具使用和推理能力得到了增强,使其更加通用,能够更好地处理复杂的任务。
- 增强安全性:所有 Llama 3.1 型号都经过了严格的安全测试和微调,以降低潜在风险并促进负责任的 AI 使用。这包括努力减少偏见和有害输出。
大型 LLM 与小型 LLM:争论
Llama 3.1 405B 的发布虽然规模令人印象深刻,但也引发了关于当前人工智能领域语言模型最佳规模的讨论。
正如介绍中简要所述,Mistral 和 Falcon 等竞争对手选择了较小的模型,称它们提供了更实用、更易于访问的方法。这些较小的模型通常需要较少的计算资源,因此更容易部署和微调以完成特定任务。
然而,Llama 3.1 405B 等大型模型的支持者认为,这些模型的庞大规模使其能够捕捉更深、更广的知识,从而在更广泛的任务上表现出色。他们还指出,这些大型模型有可能成为“基础模型”,在此基础上通过提炼可以构建出更小、更专业的模型。
大型和小型 LLM 之间的争论最终归结为能力和实用性之间的权衡。虽然较大的模型提供了更大的高级性能潜力,但它们也带来了更高的计算需求和由于其能耗而可能对环境产生的影响。另一方面,较小的模型可能会牺牲一些性能来提高可访问性和易于部署性。
Meta 发布的 Llama 3.1 405B 以及 70B 和 8B 等较小型号似乎承认了这种权衡。通过提供一系列型号尺寸,它们满足了 AI 社区内不同的需求和偏好。
最终,大型和小型 LLM 之间的选择将取决于具体用例、可用资源和所需的性能特征。随着该领域的不断发展,这两种方法很可能会共存,每种方法都会在多样化的 AI 应用领域中找到自己的位置。
结论
Llama 3.1系列的发布,特别是405B模型,代表了对开源大型语言模型领域的显著贡献。
虽然它的性能可能无法始终超越所有封闭模型,但它的功能以及 Meta 对透明度和协作的承诺为人工智能发展提供了一条新的道路。
多种模型尺寸和共享增强功能的可用性扩大了研究人员、开发人员和组织的潜在应用范围。
通过公开分享这项技术,Meta 正在营造一种协作环境,从而加速该领域的进步,使先进的人工智能更加容易获得。
Llama 3.1 对人工智能未来的影响还有待观察,但它的发布凸显了开源计划在追求负责任和有益的人工智能技术方面日益增长的重要性。
常见问题解答
Llama 3.1 405B 比 GPT-4o 和 GPT-4 更好吗?
Llama 3.1 405B 的表现与 GPT-4 和 GPT-4o 相当,在推理任务和代码生成等某些基准测试中表现出色。然而,人工评估表明,其整体表现略逊于 GPT-4o。
Llama 3.1 405B 比 Claude 3.5 Sonnet 好吗?
Llama 3.1 405B 和 Claude 3.5 Sonnet 在许多基准测试和人工评估中表现出相当的性能,并且每个模型在不同领域都有优势。
Llama 3.1 405B 比 Gemini 好吗?
由于尚未对 Llama 3.1 405B 和 Gemini 进行过广泛的基准测试,因此直接比较的机会有限。不过,Llama 3.1 405B 在各种基准测试中的表现表明,它可以与 Gemini 相媲美。
Llama 3.1 405B 是开源的吗?
是的,Llama 3.1 405B 是在 Meta 的定制开放模型许可协议下发布的,允许用于研究和商业用途。
Llama 3.1 型号系列有多少种不同尺寸?
Llama 3.1家族包含多个不同尺寸的型号,包括旗舰型号405B、70B和8B。


![Llama Stack入门安装指南[结合Ollama]-AI大模型](https://assh83.com/wp-content/uploads/2024/09/3541422-0-82720500-1727389966-shutterstock_1175616652-100945248-orig-360x180.webp)

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)