
开始使用新的 Llama 模型并定制 Llama-3.1-8B-It 以从文本中预测各种心理健康障碍。
在本教程中,我们将了解 Llama 3.1 模型,并根据心理健康数据集的情绪分析对 Llama-3.1-8b-It 模型进行微调。我们的目标是自定义模型,使其能够根据文本预测患者的心理健康状况。我们还将适配器与基础模型合并,并将完整模型保存在 Hugging Face 中心。
我们将了解 Llama 3.1 模型、如何在 Kaggle 上访问它们以及如何使用 Transformer 库运行模型推理。我们还将在心理健康数据集分类数据集上微调 Llama-3.1-8b-It 模型。最后,我们将保存的适配器与基础模型合并,并将完整模型推送到 Hugging Face Hub。
如果您是该主题的新手,您可以通过阅读我们的文章“微调 LLM 入门指南”了解微调背后的理论。
隆重推出 Llama 3.1
Llama 3.1 是 Meta AI 开发的最新系列多语言大型语言模型 (LLM),正在突破语言理解和生成的界限。它有三种大小:8B、70B 和 405B 参数。
Llama 3.1 模型基于自回归语言模型架构构建,具有优化的转换器,可针对各种自然语言处理任务和数据集进行微调。它们在多样化的公开在线数据集上进行训练,支持八种语言(英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语),上下文长度为 128k。
Llama 3.1 模型可根据定制的商业许可供所有人使用,并且只需要个人的最少信息即可下载模型权重。
Llama 3.1 针对多语言对话进行了优化,在各种基准测试中均优于 Gemma 2、GPT 3.5 turbo 和 GPT-4o,包括一般聊天、编码、数学、推理等。它是迄今为止速度最快、最准确的开源模型。
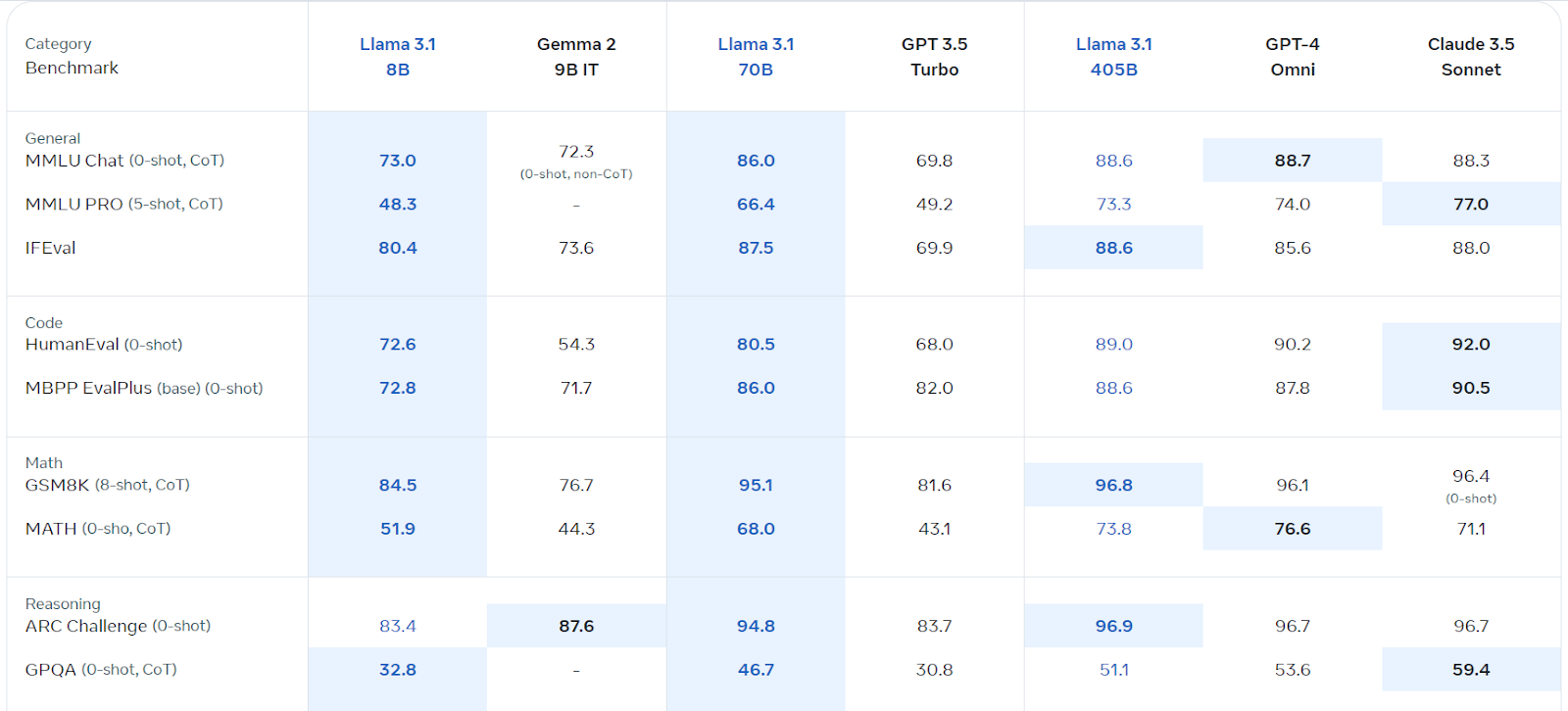
您可以通过阅读什么是 Meta 的 Llama 3.1 405B?其工作原理、用例等了解有关 Llama 3.1 模型的更多信息。
开始使用 Llama 3.1
在本教程中,我们将使用 Kaggle Notebook 作为开发环境,因为它提供免费的 GPU 和 TPU。要在 Kaggle 笔记本上使用 Llama 3.1 模型,请按照以下步骤操作:
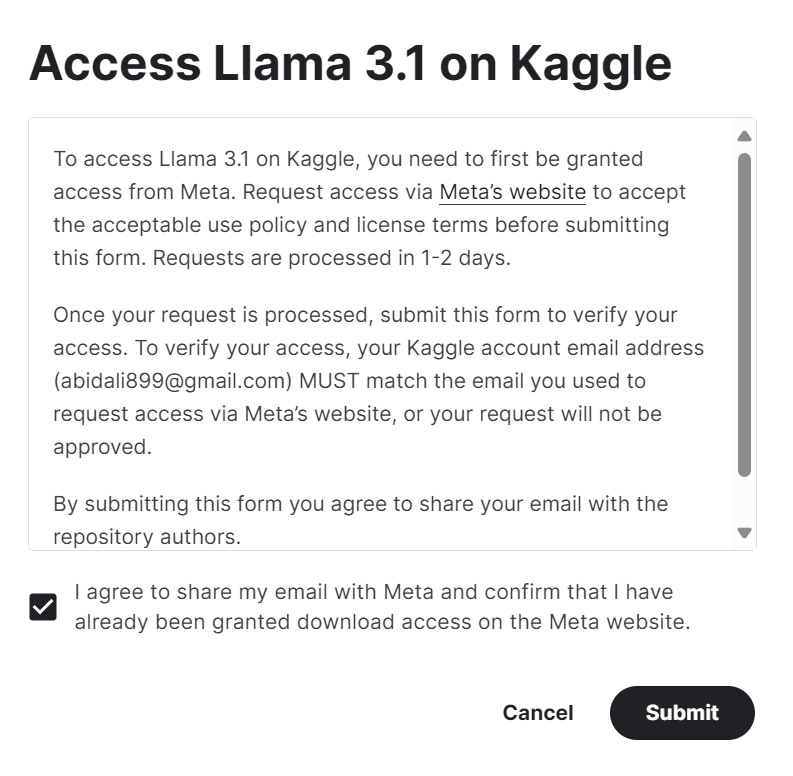
1.使用与您的 Kaggle 帐户相同的电子邮件地址填写meta.com上的表格。
2. 访问Kaggle 上的Meta | Llama 3.1模型存储库,然后单击“访问模型”按钮。接受所有条款,几秒钟后,您将获得该模型的访问权限。
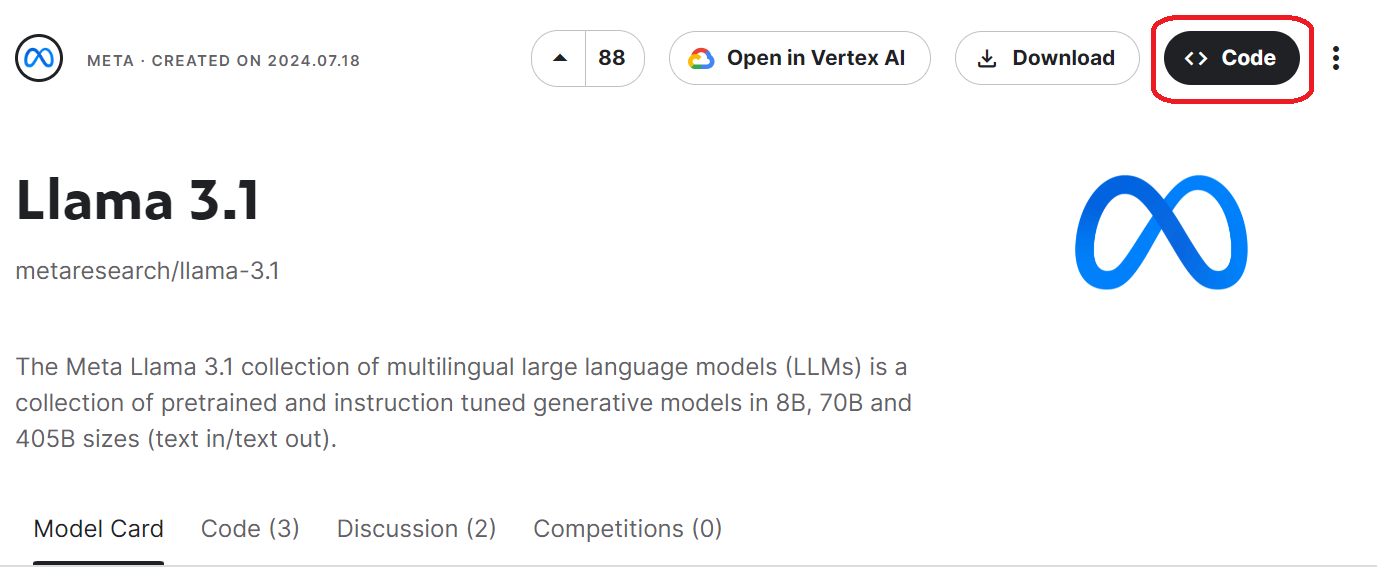
3. 单击模型页面右上角的“代码”按钮,使用 Llama 3.1 模型启动 Kaggle 笔记本。
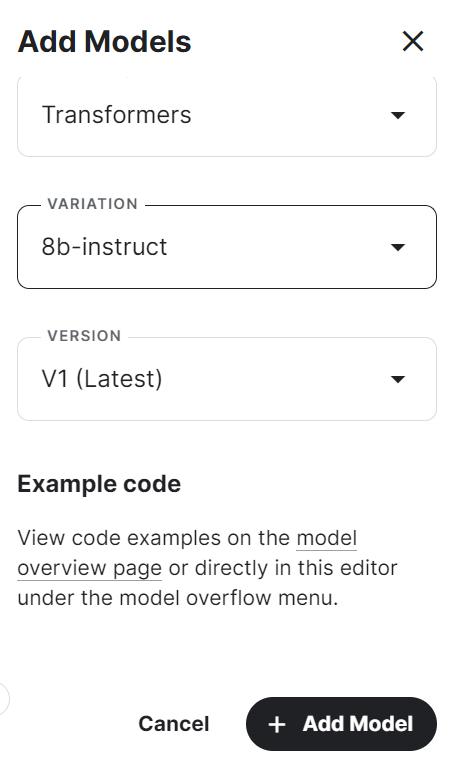
4.选择框架、变体和版本,然后按“添加模型”按钮。
5.使用以下命令在 Kaggle 笔记本中安装必要的 Python 包:
%pip install -U transformers accelerate6. 使用本地目录中的 Transformers 库加载模型和标记器。
7. 使用模型、标记器、火炬类型和设备映射创建文本生成管道。
from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)8. 编写消息并使用聊天模板将其转换为正确的提示。
9. 使用提示运行管道并打印出生成的输出。
messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])答案准确、详细。

如果在运行模型推理时遇到困难,请参考 Kaggle Notebook 中的Llama 3.1 简单模型推理。
对 Llama 3.1 进行心理健康障碍分类微调
现在,我们必须加载数据集、处理它并微调 Llama 3.1 模型。我们还将比较微调前后模型的性能。
如果您是 LLM 新手,我建议您在深入学习本教程的微调部分之前,先学习掌握大型语言模型 (LLM) 概念课程。
1. 设置
首先,我们将启动新的 Kaggle 笔记本和 Llama 3.1 模型,就像在上一节中所做的那样。
然后,我们将安装必要的 Python 包,如下所示:
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trl接下来,我们将心理健康情绪分析数据添加到 Kaggle 笔记本中。为此,请单击右上角的“添加输入”按钮,然后将模型链接粘贴到搜索栏中。然后,要添加模型,只需单击加号 (+) 按钮即可。
我们将使用权重和偏差 API 跟踪模型的性能。要访问 API,我们需要 API 密钥。使用 Secrets 在 Kaggle 中设置 API 密钥并激活它,如下所示。
然后我们可以使用 API 密钥启动权重和偏差项目。
import wandb
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune llama-3.1-8b-it on Sentiment Analysis Dataset',
job_type="training",
anonymous="allow"
)接下来,我们需要导入所有必要的 Python 包和函数。
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
from sklearn.model_selection import train_test_split2. 加载和处理数据集
现在我们需要加载数据集、执行数据清理并删除三个模糊类别。
为了简化问题,我们将删除“自杀”类别,因为 Llama 3.1 具有安全机制来阻止某些触发词。“压力”不被视为精神障碍,而“人格障碍”与“躁郁症”有很多重叠。
因此,我们只剩下四个类别:“正常”,“抑郁”,“焦虑”和“躁郁症”。
df = pd.read_csv("/kaggle/input/sentiment-analysis-for-mental-health/Combined Data.csv",index_col = "Unnamed: 0")
df.loc[:,'status'] = df.loc[:,'status'].str.replace('Bi-Polar','Bipolar')
df = df[(df.status != "Personality disorder") & (df.status != "Stress") & (df.status != "Suicidal")]
df.head()
为了节省训练时间,我们将仅使用 3000 个样本对模型进行微调。为此,我们将对数据集进行打乱并选择 3000 行。
然后,我们将数据集分成训练集、评估集和测试集,以进行模型训练和测试。
我们还想使用该generate_prompt函数在训练和评估集中创建“文本”列,该函数结合了“语句”和“状态”列中的数据。
最后,我们将使用函数在测试集中创建“文本”列generate_test_prompt,并y_true使用“状态”列。我们将使用它来生成模型评估报告,如下所示。
# Shuffle the DataFrame and select only 3000 rows
df = df.sample(frac=1, random_state=85).reset_index(drop=True).head(3000)
# Split the DataFrame
train_size = 0.8
eval_size = 0.1
# Calculate sizes
train_end = int(train_size * len(df))
eval_end = train_end + int(eval_size * len(df))
# Split the data
X_train = df[:train_end]
X_eval = df[train_end:eval_end]
X_test = df[eval_end:]
# Define the prompt generation functions
def generate_prompt(data_point):
return f"""
Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {data_point["statement"]}
label: {data_point["status"]}""".strip()
def generate_test_prompt(data_point):
return f"""
Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {data_point["statement"]}
label: """.strip()
# Generate prompts for training and evaluation data
X_train.loc[:,'text'] = X_train.apply(generate_prompt, axis=1)
X_eval.loc[:,'text'] = X_eval.apply(generate_prompt, axis=1)
# Generate test prompts and extract true labels
y_true = X_test.loc[:,'status']
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])此时,我们要检查训练集中类别的分布。
X_train.status.value_counts()您可以在下方看到,“正常”和“抑郁”类别的分布几乎相等。其余标签属于少数。这意味着我们的数据集不平衡,与少数标签相比,该模型在预测多数标签方面会更好。
我们可以平衡数据集,但这不是本教程的目标。
status
Normal 1028
Depression 938
Anxiety 258
Bipolar 176
Name: count, dtype: int64因此,接下来,我们要将训练集和评估集转换为 Hugging Face 数据集。
# Convert to datasets
train_data = Dataset.from_pandas(X_train[["text"]])
eval_data = Dataset.from_pandas(X_eval[["text"]])然后,我们显示“文本”列中的第 4 个样本。
train_data['text'][3]我们看到“文本”栏中有系统提示、声明、状态作为标签。

3. 加载模型和标记器
接下来,我们要以 4 位量化加载 Llama-3.1-8b-instruct 模型,以节省 GPU 内存。
然后我们将加载标记器并设置 pad 标记 id。
base_model_name = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype="float16",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token_id = tokenizer.eos_token_id4. 微调前的模型评估
在这里,我们创建predict函数,该函数将使用文本生成管道从“文本”列中预测标签。运行该函数将根据测试集中的各种样本返回精神障碍类别列表。
def predict(test, model, tokenizer):
y_pred = []
categories = ["Normal", "Depression", "Anxiety", "Bipolar"]
for i in tqdm(range(len(test))):
prompt = test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=2,
temperature=0.1)
result = pipe(prompt)
answer = result[0]['generated_text'].split("label:")[-1].strip()
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_pred
y_pred = predict(X_test, model, tokenizer)100%|██████████| 300/300 [02:54<00:00, 1.72it/s]之后,我们创建一个evaluate函数,该函数将使用预测标签和真实标签来计算模型的总体准确度和每个类别的准确度,生成分类报告并打印出混淆矩阵。运行该函数将为我们提供详细的模型评估摘要。
def evaluate(y_true, y_pred):
labels = ["Normal", "Depression", "Anxiety", "Bipolar"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(x, -1) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f'Accuracy: {accuracy:.3f}')
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {labels[label]}: {label_accuracy:.3f}')
# Generate classification report
class_report = classification_report(y_true=y_true_mapped, y_pred=y_pred_mapped, target_names=labels, labels=list(range(len(labels))))
print('\nClassification Report:')
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels))))
print('\nConfusion Matrix:')
print(conf_matrix)
evaluate(y_true, y_pred)即使没有进行微调,Llama 3.1 的表现也非常出色。79% 的准确率已经足够好了。让我们看看当我们在数据集上对模型进行微调时,模型会如何改进。
Accuracy: 0.790
Accuracy for label Normal: 0.741
Accuracy for label Depression: 0.939
Accuracy for label Anxiety: 0.556
Accuracy for label Bipolar: 0.533
Classification Report:
precision recall f1-score support
Normal 0.92 0.74 0.82 143
Depression 0.70 0.94 0.80 115
Anxiety 0.68 0.56 0.61 27
Bipolar 0.89 0.53 0.67 15
accuracy 0.79 300
macro avg 0.80 0.69 0.73 300
weighted avg 0.81 0.79 0.79 300
Confusion Matrix:
[[106 33 4 0]
[ 3 108 3 1]
[ 4 8 15 0]
[ 2 5 0 8]]5. 建立模型
在构建模型时,我们首先使用库从模型中提取线性模块名称bits and bytes。
然后,我们使用目标模块、任务类型和其他参数配置 LoRA,然后设置训练参数。这些训练参数针对 Kaggle 笔记本进行了优化。如果您在本地使用它们,则可能需要更改它们。
然后,我们将使用训练参数、模型、标记器、LoRA 配置和数据集创建模型训练器。
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)
modules['down_proj', 'gate_proj', 'o_proj', 'v_proj', 'up_proj', 'q_proj', 'k_proj']output_dir="llama-3.1-fine-tuned-model"
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules,
)
training_arguments = TrainingArguments(
output_dir=output_dir, # directory to save and repository id
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_accumulation_steps=8, # number of steps before performing a backward/update pass
gradient_checkpointing=True, # use gradient checkpointing to save memory
optim="paged_adamw_32bit",
logging_steps=1,
learning_rate=2e-4, # learning rate, based on QLoRA paper
weight_decay=0.001,
fp16=True,
bf16=False,
max_grad_norm=0.3, # max gradient norm based on QLoRA paper
max_steps=-1,
warmup_ratio=0.03, # warmup ratio based on QLoRA paper
group_by_length=False,
lr_scheduler_type="cosine", # use cosine learning rate scheduler
report_to="wandb", # report metrics to w&b
eval_strategy="steps", # save checkpoint every epoch
eval_steps = 0.2
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=512,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)6.模型训练
现在是时候开始模型训练了:
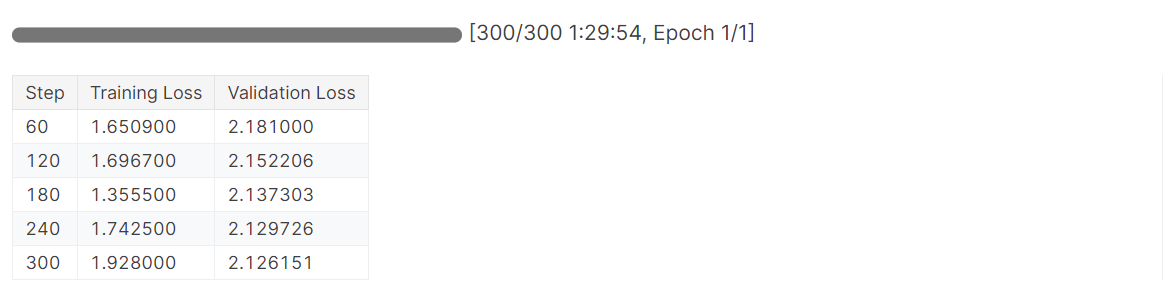
trainer.train()我们花了 1.5 小时对模型进行微调,验证损失逐渐减少。为了获得更好的性能,请尝试在完整数据集上对模型进行至少 5 个 epoch 的训练。
接下来,我们完成权重和偏差的运行。
wandb.finish()
model.config.use_cache = True我们将能够查看运行摘要,包括模型性能所需的所有指标。
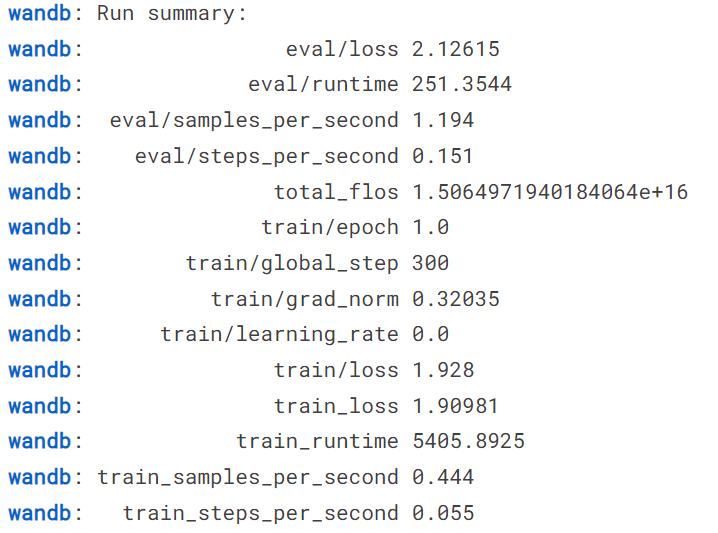
要查看详细摘要,请转到您的 Weights and Biases 帐户并在浏览器中查看运行情况。它带有交互式可视化功能。
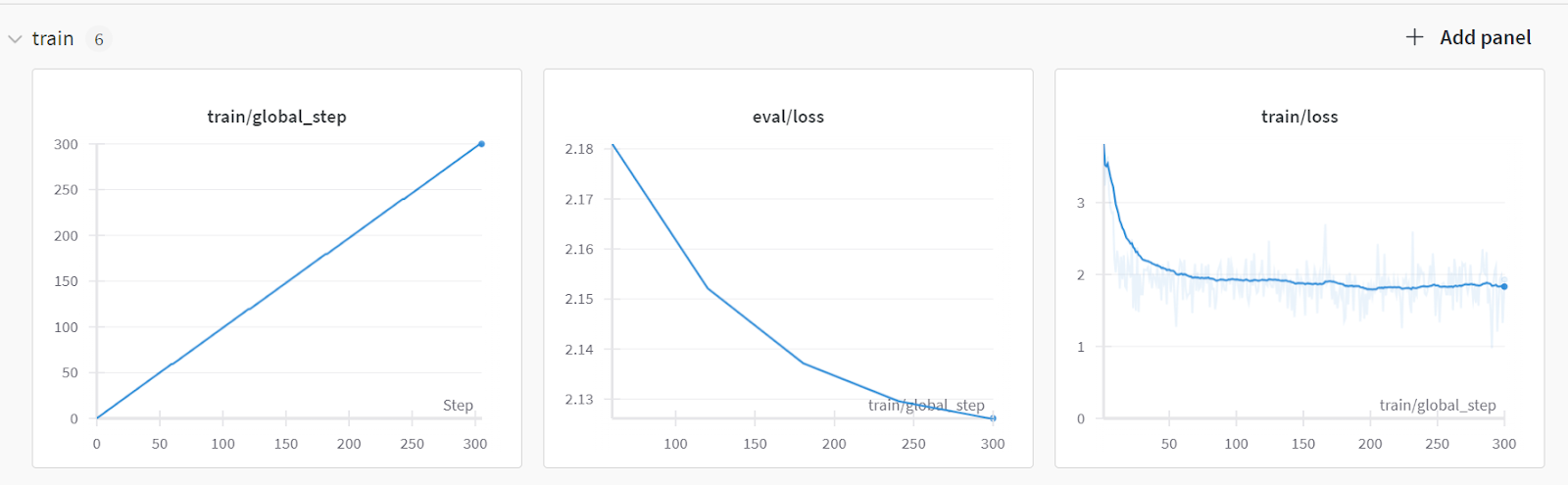
然后,我们可以将模型适配器和标记器都保存在本地。在下一节中,我们将使用它来将采用者与基础模型合并。
# Save trained model and tokenizer
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)7. 微调后测试模型
现在到了最关键的部分。我们的模型在微调后会表现得更好,还是会变得更糟?为了找出答案,我们必须在测试集上运行“预测”函数,然后运行“评估”函数来生成模型评估报告。
y_pred = predict(X_test, model, tokenizer)
evaluate(y_true, y_pred)从下面的结果可以看出,模型性能有了很大的提高,准确率从 79% 提高到了 91.3%。甚至 F1 分数看起来也不错。
100%|██████████| 300/300 [03:24<00:00, 1.47it/s]
Accuracy: 0.913
Accuracy for label Normal: 0.972
Accuracy for label Depression: 0.913
Accuracy for label Anxiety: 0.667
Accuracy for label Bipolar: 0.800
Classification Report:
precision recall f1-score support
Normal 0.92 0.97 0.95 143
Depression 0.93 0.91 0.92 115
Anxiety 0.75 0.67 0.71 27
Bipolar 1.00 0.80 0.89 15
accuracy 0.91 300
macro avg 0.90 0.84 0.87 300
weighted avg 0.91 0.91 0.91 300
Confusion Matrix:
[[139 3 1 0]
[ 5 105 5 0]
[ 6 3 18 0]
[ 1 2 0 12]]现在,我们可以保存 Kaggle 笔记本以保存结果和模型文件。为此,我们点击右上角的“保存版本”按钮,选择版本类型“快速保存”,然后选择保存输出类型“创建快速保存时始终保存输出”。
如果您在微调模型时遇到困难,请参阅 Kaggle笔记本以获得进一步帮助。
您还可以按照我们的指南《微调 Llama 3 并在本地使用》了解如何微调 Llama 3.0 模型。
合并并保存经过微调的 Llama 3.1 模型
在本节中,我们将适配器与基础模型合并,并将完整版本保存在 Hugging Face 中心上。
首先,我们启动一个带有 GPU 加速的新 Kaggle 笔记本,并添加已保存的笔记本以访问模型文件。我们还可以将其他 Kaggle 笔记本作为输入,类似于添加数据集。
然后我们可以安装必要的 Python 包。
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft接下来,我们使用 API 密钥登录 Hugging Face 中心 API,将我们的模型文件推送到 Hugging Face 模型存储库中。
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)然后我们可以设置基础模型和微调模型的目录。
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
fine_tuned_model = "/kaggle/input/fine-tune-llama-3-1-for-text-classification/llama-3.1-fine-tuned-model/"然后,加载标记器和基础模型。
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)我们将基础模型与微调适配器合并,如下所示。
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, fine_tuned_model)
model = model.merge_and_unload()在保存模型之前,让我们检查一下它是否正常工作。使用模型和标记器创建文本生成管道,并为其提供示例提示。
text = "I'm trapped in a storm of emotions that I can't control, and it feels like no one understands the chaos inside me"
prompt = f"""Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {text}
label: """.strip()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=2, do_sample=True, temperature=0.1)
print(outputs[0]["generated_text"].split("label: ")[-1].strip())我们的模型运行完美。
Depression我们现在可以在本地保存模型和标记器。
model_dir = "Llama-3.1-8B-Instruct-Mental-Health-Classification"
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)然后将模型和标记器推送至 Hugging Face Hub。
model.push_to_hub(model_dir, use_temp_dir=False)
tokenizer.push_to_hub(model_dir, use_temp_dir=False)这将在 Hugging Face 上创建存储库并推送所有模型和标记器文件。
CommitInfo(commit_url='https://huggingface.co/kingabzpro/Llama-3.1-8B-Instruct-Mental-Health-Classification/commit/e1244abeaac159e0a48439095200a4190c2b493c', commit_message='Upload tokenizer', commit_description='', oid='e1244abeaac159e0a48439095200a4190c2b493c', pr_url=None, pr_revision=None, pr_num=None)我们可以通过访问Hugging Face网站来查看所有的模型文件。
来源:kingabzpro/Llama-3.1-8B-Instruct-Mental-Health-Classification·Hugging Face
如果您在将适配器与基础模型合并时遇到问题,请参阅Kaggle 笔记本。
如果您发现对 LLM 进行微调很困难,则可以按照微调 OpenAI 的 GPT-4:分步指南教程来学习一种更简单的方法,即使用 OpenAI API 仅用几行代码在任何数据集上对模型进行微调。
最后的想法
对模型进行微调并不局限于基于数据集的定制,我们可以在各种自然语言任务上对大型语言模型进行微调,例如机器翻译、聚类、分类、问答、嵌入等。
在本教程中,我们学习了如何在心理健康分类数据集上微调 Llama 3.1 模型。该模型可用于识别在日常生活中面临挑战的患者甚至员工。
如果您想知道如何开始学习 LLM 并开始自行微调模型,那么您应该考虑学习“开发大型语言模型”技能课程。通过这一系列课程,您将在 LLM 中打下坚实的基础,推动您进入新的 AI 领域。


![Llama Stack入门安装指南[结合Ollama]-AI大模型](https://assh83.com/wp-content/uploads/2024/09/3541422-0-82720500-1727389966-shutterstock_1175616652-100945248-orig-360x180.webp)

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)