
Claude 2/3/3.5 基准测试与评论
本页汇编了对 Claude 模型的评估和评价,基准测试衡量了 Claude 模型作为语言模型在各种 NLP 任务中的能力,包括文本蕴涵、问答、摘要和对话。我希望本页能让您全面了解 Claude 模型的语言能力以及它们与其他最先进的 AI 系统的比较情况。
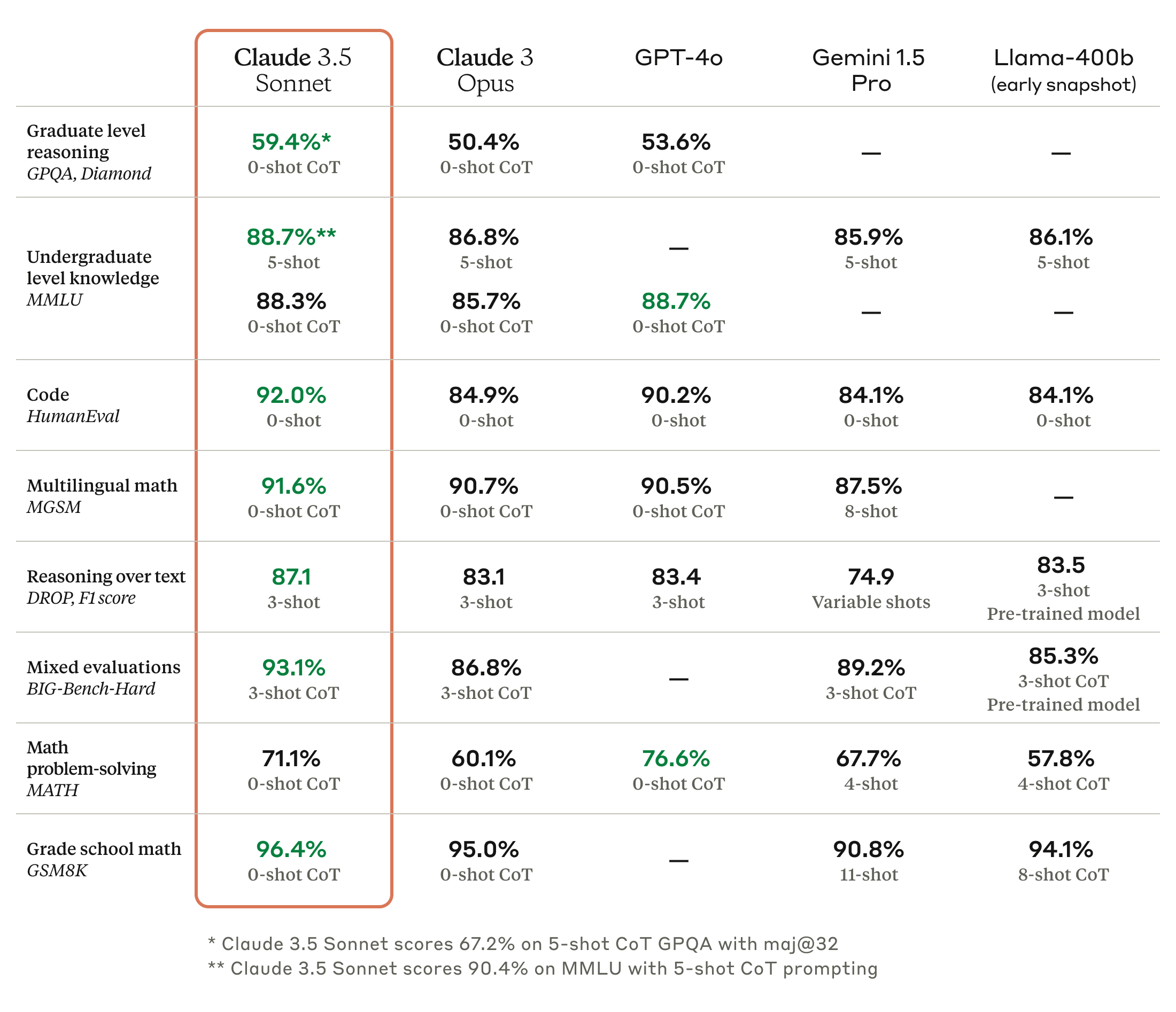
Claude 3.5 版本的对比
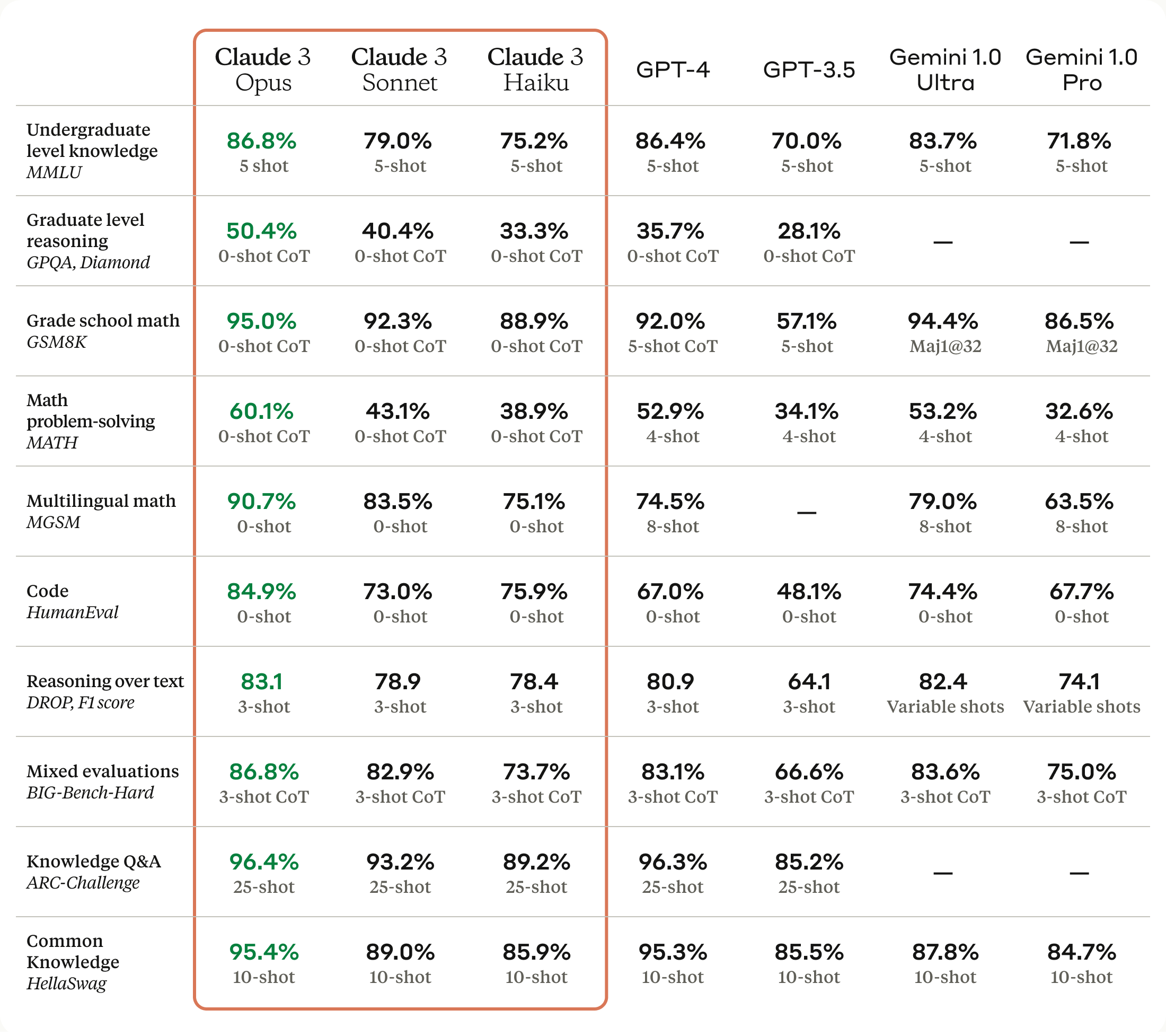
Claude 3 Models 的得分
Claude 2 在所有热门测试中的得分
- 76.5%(律师资格考试多项选择题 Claude 2 分数)
- 73.0%(律师资格考试多项选择题克劳德分数为 1.3)
- 第 90 个百分位(Claude 2 GRE 阅读/写作成绩与研究生院申请者相比)
- 中位数(Claude 2 GRE 定量推理分数与研究生院申请者相比)
- 71.2%(Codex HumanEval 上的 Claude 2 分数)
- 56.0%(之前 Claude 在 Codex HumanEval 上的得分)
- 88.0%(GSM8k 数学问题的 Claude 2 分数)
- 85.2%(之前 Claude 在 GSM8k 数学问题上的得分)
- 好 2 倍(Claude 2 与 Claude 1.3 在给出无害反应方面)
来自不同来源的评论
- Claude 2 AI 在处理 PDF 方面表现如何?– 让我们来一探究竟 –链接
- Claude 模型的模型卡和评估 – PDF
- Claude 3.5 Sonnet 模型卡附录 – PDF
- Claude 3 模型卡 – PDF
- ARB:大型语言模型的高级推理基准 – PDF
- LLM 幻觉分级 – Google Sheet
- Llama 2 vs Claude 2 vs GPT-4 –视频
- 连续使用 Anthropic 的 Claude 2 12 小时后,我发现了以下情况 – Reddit 讨论
- claude2有多强?– 视频
- 关于 Claude 2(Anthropic 的 ChatGPT 竞争对手)你需要知道些什么-链接

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-360x180.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-355x180.png)
![Claude客户支持聊天web app开发[可建私域知识库]](https://assh83.com/wp-content/uploads/2024/10/preview-360x180.png)

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)