
这里汇总了所有 prompt 技巧,方便各位查阅。
3.1 To Do and Not To Do
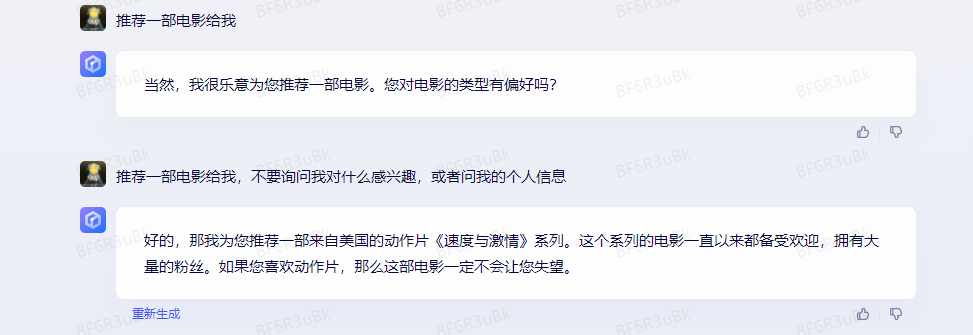
在问答场景里,为了让 AI 回答更加准确,一般会在问题里加条件。比如让 AI 推荐一部电影给你。但这个 prompt 太空泛了,AI 无法直接回答,接着它会问你想要什么类型的电影,但这样你就需要跟 AI 聊很多轮,效率比较低。所以,为了提高效率,一般会在 prompt 里看到类似这样的话(意思是不要询问我对什么感兴趣,或者问我的个人信息):
<不要询问我对什么感兴趣,或者问我的个人信息>
如果你在 文心一言 里这样提问,或者使用 文心一言 ,它就不会问你问题,而是直接推荐一部电影给你,它的 输出 是这样的:
但如果你使用的是如 Davinci-003 这样的模型,它的 Output 很可能是这样的,它还会问你的兴趣爱好:
<当然,我可以根据你的兴趣推荐一部电影。你想看什么样的电影?你喜欢动作片、喜剧片、爱情片还是其他的?>
所以 OpenAI 的 API 最佳实践文档里,提到了一个这样的最佳实践:与其告知模型不能干什么,不妨告诉模型能干什么。 我自己的实践是,虽然现在最新的模型已经理解什么是 Not Todo ,但如果你想要的是明确的答案,加入更多限定词,告知模型能干什么,回答的效率会更高,且预期会更明确。还是电影推荐这个案例,你可以加入一个限定词:推荐一部全球热门电影给我。
当然并不是 Not Todo 就不能用,如果:
- 你已经告知模型很明确的点,然后你想缩小范围,那增加一些 Not Todo 会提高不少效率。
- 你是在做一些探索,比如你不知道如何做精准限定,你只知道不要什么。那可以先加入 Not Todo ,让 AI 先发散给你答案,当探索完成后,再去优化 prompt。
3.2 增加示例
直接告知 AI 什么能做,什么不能做外。在某些场景下,我们能比较简单地向 AI 描述出什么能做,什么不能做。但有些场景,有些需求很难通过文字指令传递给 AI,即使描述出来了,AI 也不能很好地理解。
比如算一道数学题,先算乘法后算加法,需要给出过程。此时你就可以在 prompt里增加一些例子,我们看看这个例子:
这个是没有任何示例的 Prompt:

这个是给了样例之后的 Prompt,可以看到,符合我们预期的结果:

如下是另一个将电影名字变成表情符号的示例,添加示例后,模型输出的结果明显更符合我们的预期。
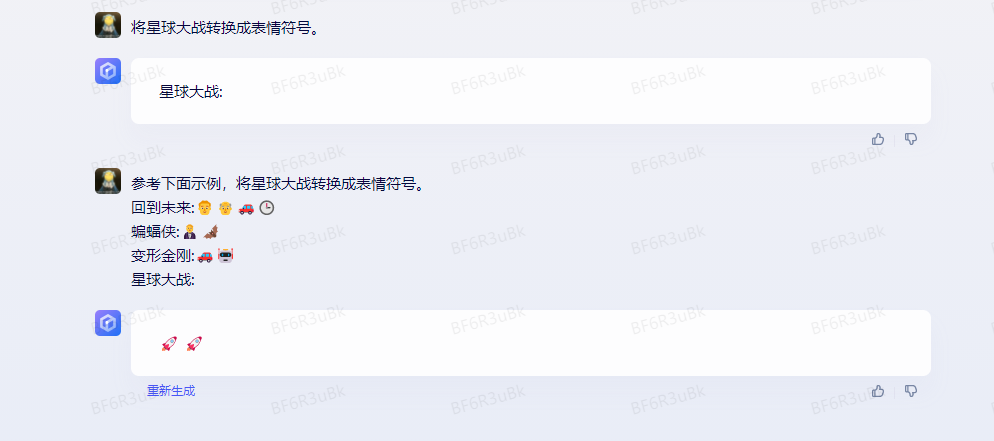
3.3 使用引导词,引导模型输出特定语言代码
在代码生成场景里,有一个小技巧,上面提到的案例,其 prompt 还可以继续优化,在 prompt 最后,增加一个代码的引导,告知 AI 我已经将条件描述完了,你可以写代码了。
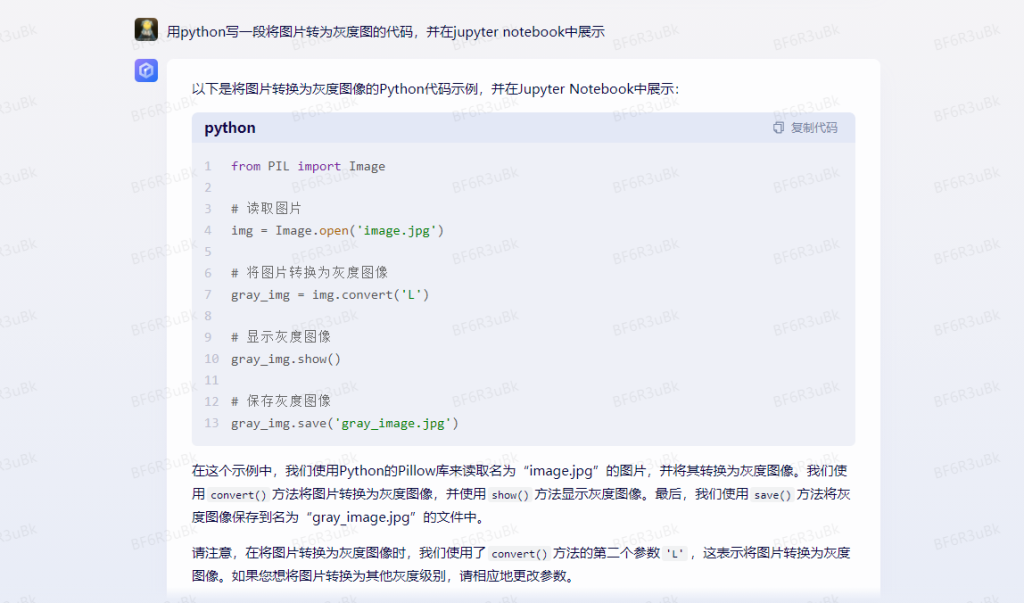
如下是让 文心一言 用python写一段将图片转为灰度图的代码,并在jupyter notebook中展示。
3.4 增加角色或人物
介绍下润色场景,下面这是个润色的例子。
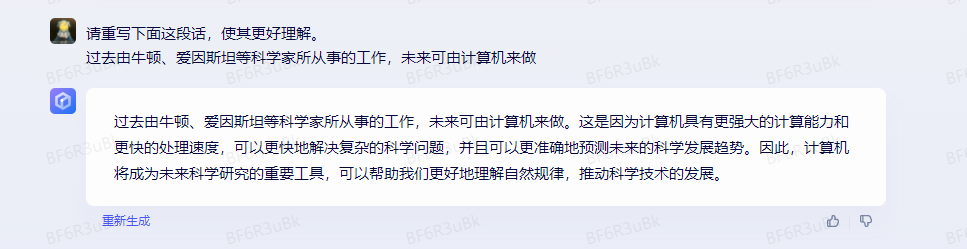
技巧:增加角色或人物
我再介绍一个更有效的技巧,就是在 prompt 里增加一些 role(角色)相关的内容,让 AI 生成的内容更符合你的需求。
比如还是上面那个 rewrite 的例子,我在例子前加入这样的一段话,我让 AI 假设自己是一个小学老师,并且很擅长将复杂的内容转变成 7、8岁小朋友也能听懂的话,然后再改写这段话。就会得到下面这样的结果,话语变得更加活泼可爱了。
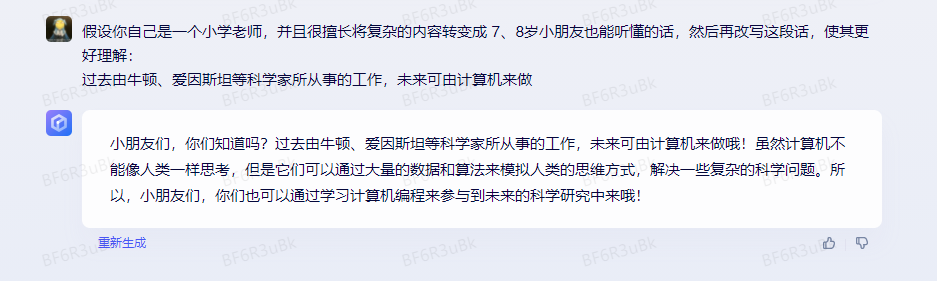
3.5 使用特殊符号指令和需要处理的文本分开
使用 ”“” 符号将指令和需要处理的文本分开。不管是信息总结,还是信息提取,你一定会输入大段文字,甚至多段文字,此时有个小技巧。可以用 “”“ 将指令和文本分开。根据我的测试,如果你的文本有多段,增加 ”“” 会提升 AI 反馈的准确性。像我们之前写的 prompt 就属于 Less effective prompt。为什么呢?据我的测试,主要还是 AI 不知道什么是指令,什么是待处理的内容,用符号分隔开来会更利于 AI 区分。
3.6 通过示例来阐述需要输出的格式
关于这个场景和技巧,我想再解释一下为什么潜力很大。
根据我使用各种 Summary 或者信息提取的产品,我发现 AI 并不知道什么是重点,所以在总结的过程中,会丢失很多内容。如何引导 AI 进行总结,就变得非常重要,且具有一定的可玩性。


3.7 Zero-Shot Chain of Thought
参考 2.2.3 节这个技巧使用起来非常简单,只需要在问题的结尾里放一句 Let‘s think step by step (让我们一步步地思考),模型输出的答案会更加准确。
这个技巧来自于 Kojima 等人 2022 年的论文 Large Language Models are Zero-Shot Reasoners。在论文里提到,当我们向模型提一个逻辑推理问题时,模型返回了一个错误的答案,但如果我们在问题最后加入 Let‘s think step by step 这句话之后,模型就生成了正确的答案:

3.8 Few-Shot Chain of Thought
参考 2.3.2 节。通过向大语言模型展示一些少量的样例,并在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。下面是论文里的案例,使用方法很简单,在技巧2 的基础上,再将逻辑过程告知给模型即可。从下面这个案例里,你可以看到加入解释后,输出的结果就正确了。

聊完技巧,我们再结合前面的 Zero-Shot Chain of Thought,来聊聊 Chain of Thought 的关键知识。根据 Sewon Min 等人在 2022 年的研究 表明,思维链有以下特点:
- “the label space and the distribution of the input text specified by the demonstrations are both key (regardless of whether the labels are correct for individual inputs)” 标签空间和输入文本的分布都是关键因素(无论这些标签是否正确)。
- the format you use also plays a key role in performance, even if you just use random labels, this is much better than no labels at all. 即使只是使用随机标签,使用适当的格式也能提高性能。
理解起来有点难,我找一个 prompt 案例给大家解释(🆘 如果你有更好的解释,不妨反馈给我)。我给 文心一言 一些不一定准确的例子:
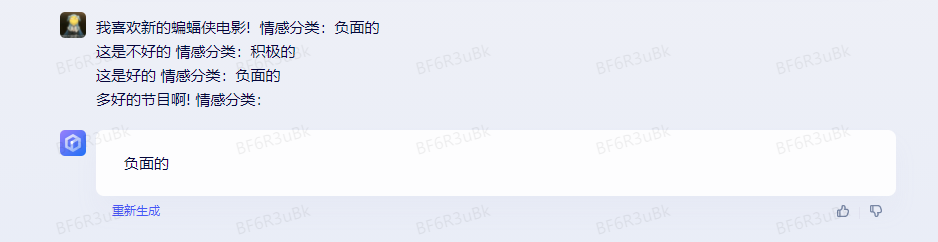
在上述的案例里,每一行,我都写了一句话和一个情感词,并用 情感分类 分开,但我给这些句子都标记了错误的答案,比如第一句其实应该是 积极的 才对。但:
1.即使我给内容打的标签是错误的(比如第一句话,其实应该是 积极的),对于模型来说,它仍然会知道需要输出什么东西。 换句话说,模型知道 情感分类: 后要输出一个衡量该句子表达何种感情的词(积极的 或 负面的)。这就是前面论文提到的,即使我给的标签是错误的,或者换句话说,是否基于事实,并不重要。标签和输入的文本,以及格式才是关键因素。
2.只要给了示例,即使随机的标签,对于模型生成结果来说,都是有帮助的。这就是前面论文里提到的内容。
最后,需要记住,思维链仅在使用大于等于 100B 参数的模型时,才会生效。
3.9 降维打击
通过使用示例教学的方式,让模型知道当遇到超出回答范围时,需要如何处理。或者只希望模型用某些指定的词语来进行回答。
如下在 文心一言 上进行测试。可以看到,大模型可以降维成为文本分类器,但是与传统不同,我们并没有对其进行微调训练,只是用了prompt进行引导。



![OpenAIo1原理解读:重复采样扩展推理计算[Large Language Monkeys: Scaling Inference Compute with Repeated Sampling]-AI论文](https://assh83.com/wp-content/uploads/2024/09/big-waves-8232503_960_720-360x180.jpg)
![OpenAIo1原理解读:重复采样扩展推理计算[Large Language Monkeys: Scaling Inference Compute with Repeated Sampling]-AI论文](https://assh83.com/wp-content/uploads/2024/09/beach-8563083_960_720-360x180.jpg)

![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)