
1.1 基础prompt框架
指令:想要模型执行的特定任务或指令。
上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式要求等
角色指令/任务问题上下文示例(few shot)
好的提示语应该是一个完整的段落,在这个段落里提供尽可能多的细节,告诉模型他应该从什么角度去思考问题。
我希望你能充当我的英语口语老师,我将用英语与你交谈,而你将用英语回答我,以练习我的英语口语。我希望你能保持回复的整洁,将回复限制在100字以内。我希望你能严格纠正我的语法错误,错别字和事实性错误。现在我们开始练习,你可以先问我一个问题。记住,我要你严格纠正我的语法错误,错别字和事实性错误。
我希望你能充当我的英语口语老师 — 指定角色
我将用英语与你交谈,而你将用英语回答我,以练习我的英语口语 — 描述背景和指令
我希望你能保持回复的整洁,将回复限制在100字以内 –提出限制
我希望你能严格纠正我的语法错误,错别字和事实性错误 — 输出指示
记住,我要你严格纠正我的语法错误,错别字和事实性错误。– 再次强调
1.2 promtp技巧
指定角色
角色提示是一种强大的策略,可以塑造生成式人工智能模型的输出。它使我们能够控制生成文本的风格、语气和深度,使其更适合特定的上下文或受众。无论您是在草拟电子邮件、撰写评论还是在解决数学问题,角色提示都可以显著提高结果的质量和准确性。随着我们不断探索人工智能的能力,角色提示将继续成为提示工程的关键策略。
为什么指定角色可以提升大模型的输出质量甚至是准确度?
推论【引文】:对于在LLM中通过角色扮演观察到的现象,一个可信的理论根植于这些模型的训练方式。通过从不同领域的大量文本数据中训练,模型形成了对各种角色以及与角色相关的语言的复杂理解。当被要求采用特定角色时,模型可以利用这种理解来产生准确的、特定角色的响应。
发散思考:指定角色之所以有非常好的效果,是因为这个角色本身的含义已经包含了非常多的“隐藏信息”,可能包含限制信息、cot信息等。这些信息是对大量数据的准确抽象。相比其他提示词技巧他更简短、更准确、更丰富。一个猜想是给出越精确的角色指定,提示的效果可能越好,但是受限于个人认知,可能很多的角色我们都不知道,更无从指定。
给出示例
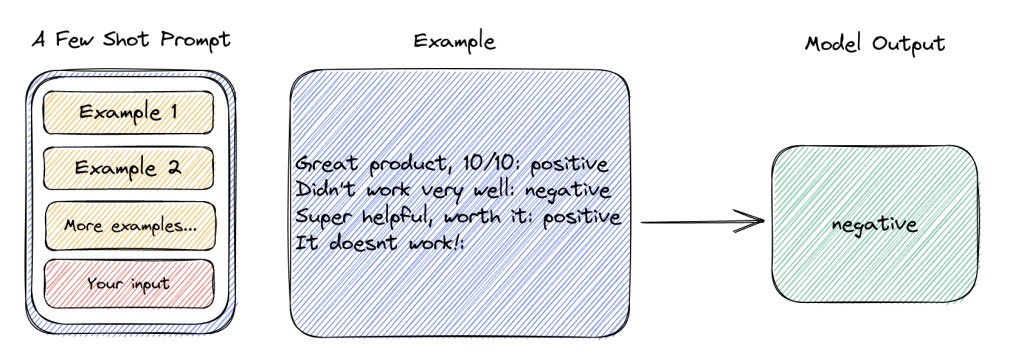
另一个提示策略是少样本提示(few shot prompting), 这种策略将为模型展示一些例子(shots),从而更形象地描述你的需求。
在某些情境下,我们能够相对简单地向AI描述可以或不可以做的事情。但在其他情境下,有些要求很难通过文字指令清晰传达给AI。即便能够描述,AI也可能难以充分理解。举例来说,给宠物取英文名通常融合了多种特定的命名风格。在这种情况下,我们可以通过在提示中加入一些例子来看。
总的来说,提供示例对解决某些任务很有用。当零样本提示和少样本提示不足时,这可能意味着模型学到的东西不足以在任务上表现良好。
链式思考提示
COT (chain-of-thought prompting)
思维链(CoT)提示过程1是一种最近开发的提示方法,它鼓励大语言模型解释其推理过程。下图显示了 few shot standard prompt(左)与链式思维提示过程(右)的比较。
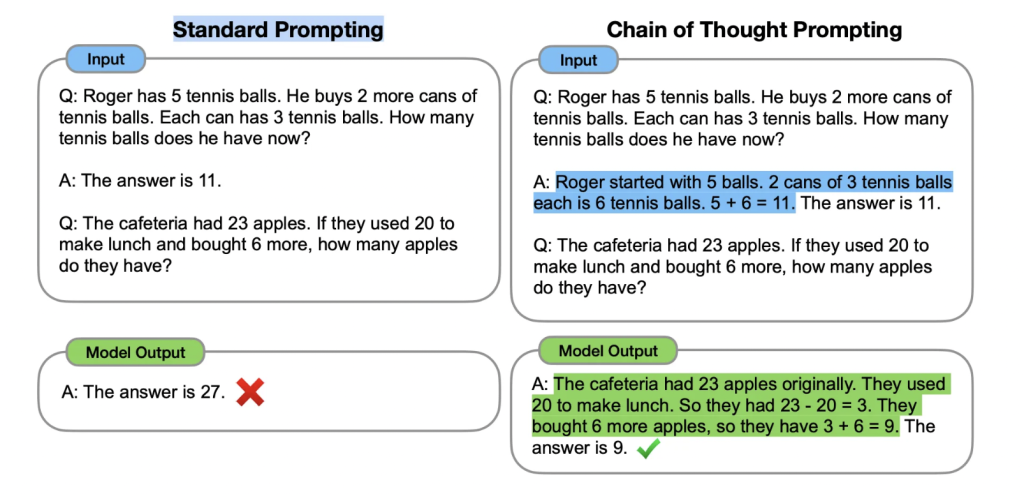
COT同样给出一些样本,但是这些样本包含了完成任务的推理过程。这样大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
重要的是,根据Wei等人的说法,“思维链仅在使用∼100B参数的模型时才会产生性能提升”。较小的模型编写了不合逻辑的思维链会导致精度比标准提示更差。通常,模型从思维链提示过程中获得性能提升的方式与模型的大小成比例。
自洽性
其想法是通过少样本CoT采样多个不同的推理路径,并使用生成结果选择最一致的答案。这有助于提高CoT提示在涉及算术和常识推理的任务中的性能。
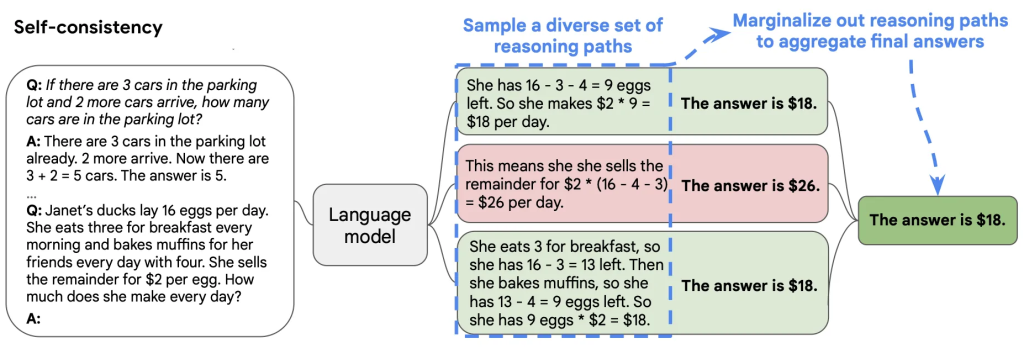
这个策略假设复杂推理任务一般可以通过多个推理路径获得正确答案,从解码器中抽样生成多样化的推理路径集合,选择一致性最高的输出结果作为最终答案。这个策略在工程上是常见的方案。
其具体过程 引文
Procedure 1. Add “think step-by-step“ to your original question (we’ll call this augmented question the question in the following).2. Ask the question repeatedly (n times) and collect the answers.3. Decide for a voting technique and decide which of the collected answers is picked as the final answer.
实践小问题对于多次调用给出答案,我们如何进行投票,得到最终答案呢?
直接将多次返回的结果,投喂给大模型问题,可以用以下prompt
What is the most common theme among these statements? {list of the collected answers}*
其他人的思考:
Self-consistency 可以用来解决LLM输出的不稳定性,一般我们在测试case时候也会习惯性跑测多次来确认效果,取平均结果作为测试结论,这种评测方式就是类似Self-consistencySC策略符合人类解决问题的直觉,做一道数学题,难免会存在多种不同的解决方案,然后基于投票策略选择最终结果输出,但是SC只关注了推理后最终的答案,没有关注推理路径本身,之前有研究表明过,LLM有时会给出正确的答案,看似合理实则错误的推理过程,这个论文没有讨论,应该看看推理链正确 + 答案正确的准确率,答案可能很容易评判,推理过程有没有可以衡量的方法呢
LtM (由易至难提示 )
最少到最多提示过程 (Least to Most prompting, LtM)1 将 思维链提示过程 (CoT prompting) 进一步发展,首先将问题分解为子问题,然后逐个解决。
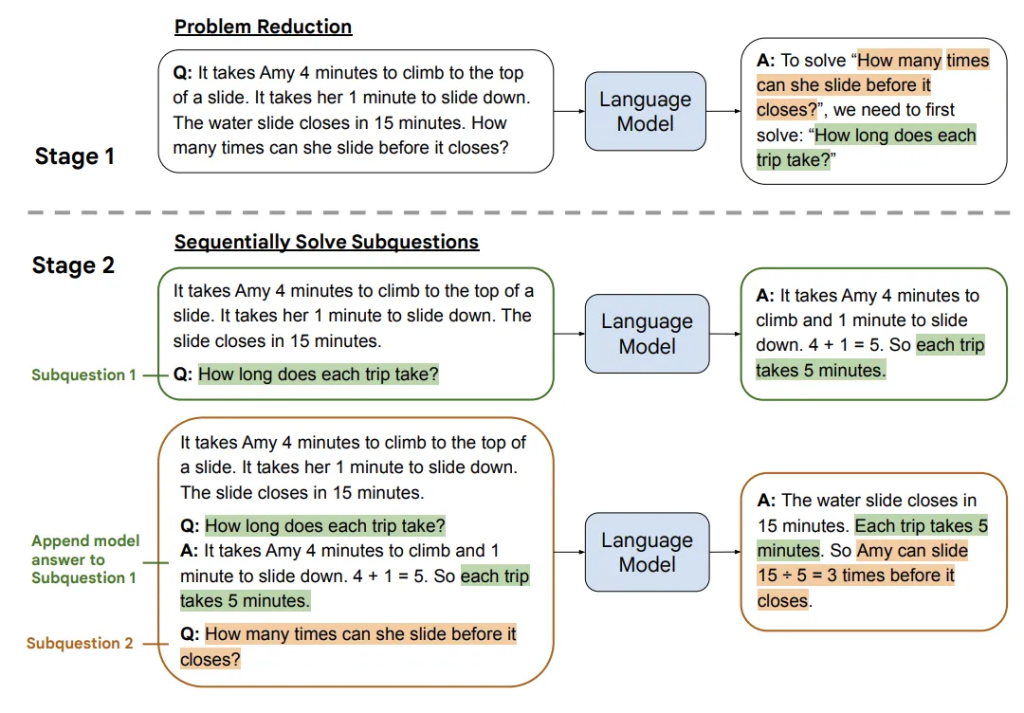
这个方法依然容易在现实中找到线索,我们在处理日常复杂事情时,也是经常讲复杂问题分解成简单问题,然后一步一步解决。
这个方法核心有两个阶段:
第一阶段(Decomposition):向语言模型提出查询,将问题分解成子问题。也就是说,首先将复杂的问题分解成一系列更简单的子问题。第二阶段(Subproblem solving):再次向语言模型提出查询,逐个解决这些子问题。值得注意的是,解决第二个子问题的答案建立在第一个子问题的答案之上。原始问题被附加在最后作为最终的子问题。
格式化提示语
使用分隔符
可以使用任何明显的标点符号将特定的文本部分与提示的其余部分分开,这可以是任何可以使模型明确知道这是一个单独部分的标记。使用分隔符是一种可以避免提示注入的有用技术,提示注入是指如果用户将某些输入添加到提示中,则可能会向模型提供与您想要执行的操作相冲突的指令,从而使其遵循冲突的指令而不是执行您想要的操作。即,输入里面可能包含其他指令,会覆盖掉你的指令。对此,使用分隔符是一个不错的策略。分隔符可以是:
“`、
“”、
<>、
\<\tag>、
:等。
指定输出格式
假设你想让 AI 总结一篇非常非常长的文章,并且按照特定格式给你总结,那你可以在文章前面明确输出的格式。
结构化输出可以是 JSON、HTML 等格式。
第二个策略是要求生成一个结构化的输出,这可以使模型的输出更容易被我们解析,例如,你可以在 Python 中将其读入字典或列表中。
1.3 prompt安全
提示注入:类似于sql注入,用户的输入拼接入prompt,可能使得prompt指令失效
提示泄漏:提示注入的一种,这种注入会使得一些系统上下文暴露
破解:通过一些特殊的prompt,可以让模型绕过自身的安全策略,输出一些非法内容。


![OpenAIo1原理解读:重复采样扩展推理计算[Large Language Monkeys: Scaling Inference Compute with Repeated Sampling]-AI论文](https://assh83.com/wp-content/uploads/2024/09/big-waves-8232503_960_720-360x180.jpg)
![OpenAIo1原理解读:重复采样扩展推理计算[Large Language Monkeys: Scaling Inference Compute with Repeated Sampling]-AI论文](https://assh83.com/wp-content/uploads/2024/09/beach-8563083_960_720-360x180.jpg)
![Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs[不要过度思考2+3等于几 在类LLM的过度思考上]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-2-350x250.png)
![Slow Perception: Let’s Perceive Geometric Figures Step-by-step[缓慢感知:让我们逐步感知几何图形]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-1-350x250.png)
![Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning[结合大型语言模型与过程奖励引导的树搜索以提升复杂推理能力]-AI论文](https://assh83.com/wp-content/uploads/2025/01/1-350x248.png)
![Large Concept Models:Language Modeling in a Sentence Representation Space[大型概念模型:在句子表示空间中的语言建模]-AI论文](https://assh83.com/wp-content/uploads/2025/01/image-1-350x250.png)